




 Swin Transformer通过使用移动窗口解决Transformer在视觉任务中的规模和计算复杂度问题,构建层次特征图,适用于多种视觉任务。它以线性计算复杂度处理图像,通过窗口移动增强建模能力。
Swin Transformer通过使用移动窗口解决Transformer在视觉任务中的规模和计算复杂度问题,构建层次特征图,适用于多种视觉任务。它以线性计算复杂度处理图像,通过窗口移动增强建模能力。
Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
论文:https://arxiv.org/abs/2103.14030
代码:语义分割、图像分类、目标检测
相关阅读:更多
差异
作者观察到Transformer在语言领域和视觉领域的 两种模式差异:
- 规模。与在语言 Transformer 中作为处理的基本元素的单词符号不同,视觉元素可以在规模上有很大的变化,在现有的基于Transformer的模型中,token 都是固定规模的。
- 计算复杂度。self-attention 的二次复杂度(计算一个token(词语)和所有其他token之间的关系,如下表),而图像中的像素分辨率比文本段落中的单词高得多,因此图像Transformer 的计算复杂度比语言Transformer 高得多。
| 三 | 点 | 几 | 了 | , | 做 | 撚 | 啊 | 做 | |
|---|---|---|---|---|---|---|---|---|---|
| 三 | |||||||||
| 点 | |||||||||
| 几 | |||||||||
| 了 | |||||||||
| , | |||||||||
| 做 | |||||||||
| 撚 | |||||||||
| 啊 | |||||||||
| 做 |
规模 & 计算复杂度
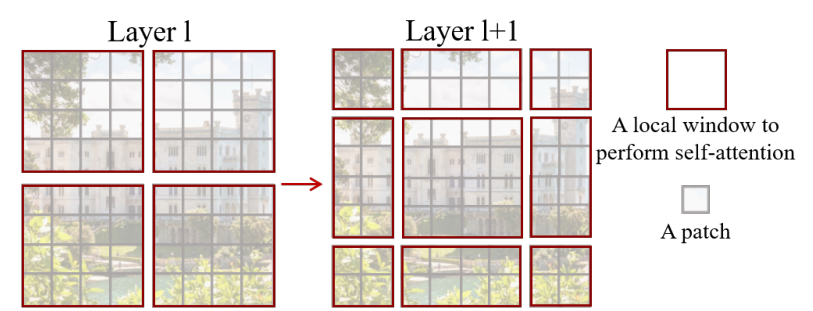
为了克服这些问题,作者提出Swin Transformer 用来构建层次特征图,由于只在每个局部窗口(如红色方块)内计算 self-attention,因此具有线性计算复杂度的图像大小。如下图所示,Swin Transformer通过从较小的patches(底层的灰色方块)开始,并逐渐合并更深的Transformer层中的邻近patches(例如,底层4个小灰块合并为中间层一个较大的灰块),构造了一个层次表示。有了这些层次特征图,Swin Transformer模型可以方便地利用高级技术进行密集预测,如特征金字塔网络(FPN)或U-Net。
线性计算复杂度是通过在非重叠窗口内局部计算 self-attention 来实现的,该窗口对图像进行划分(用红色标出)。每个窗口中的patches数量是固定的,因此复杂度与图像大小成线性关系。这些优点使Swin Transformer适合作为各种视觉任务的通用 主干 ,与以前基于Transformer的架构形成单一分辨率和二次复杂度的特征图形成对比。

Swin Transformer 的一个关键设计元素是它在连续的self-attention层之间的窗口分区的移动,如下图所示。移动的窗口桥接了上一层的窗口,提供了它们之间的连接,极大地提高了建模能力。这个策略在现实世界的延迟方面也是有效的:一个窗口内的所有查询patches共享同一个键集,这有助于硬件上的内存访问。相比之下,早期的基于滑动窗口的self-attention方法在一般硬件上受到低延迟的影响,这是由于不同查询像素的不同键集所致。实验表明,所提出的移位窗口方法比滑动窗口方法具有更低的延迟。
架构
| Patch Partition: | Images分割成不重叠的patches,patch相当于语言Transformer的token,使用4×4的patch大小,因此每个patch的特征维数为4×4×3 = 48。 |
|---|---|
| Stage 1: | 每个patch的特征应用线性嵌入层(Linear Embedding),将其投射到任意维度(记为C)。 |
| 这些patches token上应用Swin Transformer Block。Transformer Block维持 token 的数量( H 4 × W 4 \frac{H}{4}×\frac{W}{4} 4H×4W)。 | |
| Stage 2: | 第一个patches合并层将相邻4个patches的特征 拼接起来(减少 token 的数量),并在4c维的拼接特征上应用一个线性层。这将 patches 的数量减少了 4的倍(分辨率的2倍下采样),并且输出维数设置为2C。 |
| 然后应用 Swin Transformer Block 进行特征变换,分辨率保持在 H 8 × W 8 \frac{H}{8}×\frac{W}{8} 8H×8W。 | |
| Stage 3: | 同 Stage 2,输出分辨率分别为 H 16 × W 16 \frac{H}{16}×\frac{W}{16} 16H×16W。 |
| Stage 4: | 同 Stage 2,输出分辨率分别为 H 32 × W 32 \frac{H}{32}×\frac{W}{32} 32H×32 |
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1042
1042




 到【灌水乐园】发言
到【灌水乐园】发言







