create table tb(id int, value varchar(10))
insert into tb values(1, 'aa')
insert into tb values(1, 'bb')
insert into tb values(2, 'aaa')
insert into tb values(2, 'bbb')
insert into tb values(2, 'ccc')
go
CREATE FUNCTION dbo.f_strUnite(@id int)
RETURNS varchar(8000)
AS
BEGIN
DECLARE @str varchar(8000)
SET @str = ''
SELECT @str = @str + ',' + value FROM tb WHERE id=@id
RETURN STUFF(@str, 1, 1, '')
END
GO
select * from tb
SELECt id, value = dbo.f_strUnite(id) FROM tb GROUP BY id
drop table tb
drop function dbo.f_strUnite
go





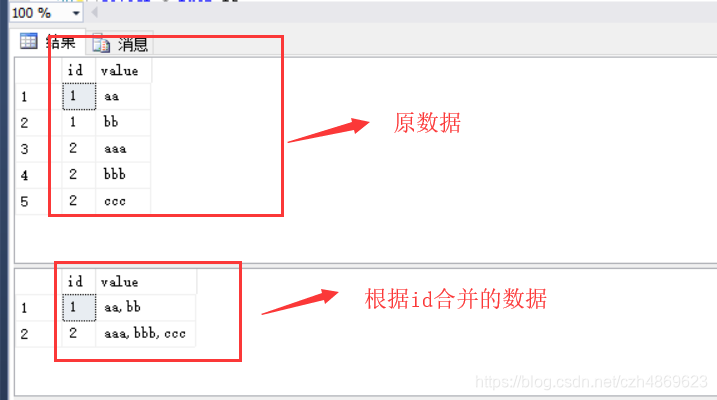
 本文介绍了一个SQL Server存储过程,该过程定义了一个函数用于将同一ID的所有记录值通过逗号连接成一个字符串。示例展示了如何创建表格、插入数据、定义和使用这个联合字符串的函数。
本文介绍了一个SQL Server存储过程,该过程定义了一个函数用于将同一ID的所有记录值通过逗号连接成一个字符串。示例展示了如何创建表格、插入数据、定义和使用这个联合字符串的函数。

















 1227
1227

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









