





论文 https://dl.acm.org/doi/10.1145/3690381
代码 https://github.com/Xiaoyu-SZ/FencrCode
最后一篇神经符号集成的论文了,24年底发表于TOIS,有很详细的实验分析。流程:逻辑规则借鉴RRL是自适应学习的,借鉴LINN架构进行规则逻辑运算编码,使用FM编码逻辑表达式,计算与逻辑常量真向量的相似度,并且使用了逻辑正则化,背景知识详细讲解了两个的机制。
动机
尽管现有推荐系统在准确性上取得了巨大成功,但其可解释性仍是提升用户信任和系统透明度的关键瓶颈 。基于逻辑规则的推断因其简洁、透明且符合人类认知,被认为是提高推荐模型可解释性的有效途径 。
然而,先前利用逻辑规则解释用户偏好的工作,往往只侧重于规则的构建(WWW22以及上一篇帖子的两个工作),而忽略了特征嵌入在捕捉特征间隐式关系方面的强大能力 。另一方面,一些结合了嵌入表示的逻辑推理方法虽然能赋予模型逻辑属性或利用预定义知识,却难以生成显式的、可供解释的推荐规则 。因此,本文的核心动机在于解决这一矛盾,即同时实现推荐模型的高推荐效果(通过利用特征嵌入)和高模型内在可解释性(通过学习显式的逻辑规则),弥补现有研究未能有效兼顾这两者的空白 。
贡献
提出了一种名为特征增强神经协同推理 (FENCR) 的新型端到端可解释推荐方法 ,它能够同时学习用于表示的特征嵌入和用于推理的显式逻辑规则 。为实现这一目标,设计了基于特征交互的神经逻辑模块,以在特征向量上有效表征合取 (∧) 和析取 (∨) 等逻辑运算 。
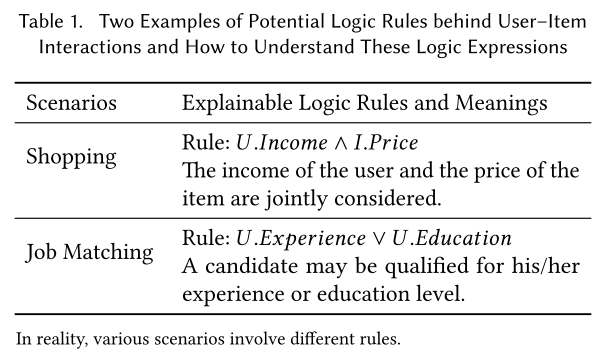
更重要的是,FENCR模型能够以数据驱动的方式自动提取代表性的逻辑规则 ,这些规则(例如购物场景下的“用户收入 ∧ 物品价格” 或求职场景下的“用户经验 ∨ 用户学历” 等直观形式)可以作为模型内在的、无需额外数据或先验知识的透明解释 。
背景知识
RRL (Rule-Based Representation Learner)
RRL是一个自适应的规则学习模型 。其目标是在保持分类准确率的同时,自动学习用于分类的可解释规则 。FENCR从中借鉴了通过训练权重矩阵来动态学习规则中包含的特征的思想 。
逻辑层是RRL进行规则学习的关键部分,它是一个多层神经网络,每一层都包含一定数量的合取节点和析取节点 。权重矩阵W代表了当前层与前一层之间的连接关系 。给定当前层第t个节点的权重向量Wt和前一层的输出 h(元素为二值),当权重W和输入h都二值化后,合取和析取操作定义为 :
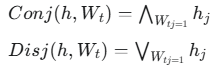
权重矩阵W的取值(0或1)决定了前一层的输出 hj 是否参与到当前节点的逻辑运算中 。通过以自监督的方式学习W,模型能够通过选择表达式中的元素来获取用于分类的逻辑规则 。例如,给定一个合取节点和四维输入 h=(h1,h2,h3,h4),如果对应的权重 W=(0,1,1,0),那么该节点代表的规则就是 h2∧h3,其中 hi 可以是变量或表达式 。
为了在神经网络中训练这些逻辑值,RRL使用了逻辑激活函数来实现合取层和析取层 :
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









