







一、解题思路
通过对大批不同类型的公文文档分析,总结公文文档的行文规则如下:
1)公文基本结构:红头、标题、主送机关、正文、附件、印发机关、印发日期、版记
2)标题格式:方正小标宋简体,二号(14Pt)
3)版记格式:两行表格,最后一个单元格内容为“[印发日期] + 印发”;
附带公文格式规范:
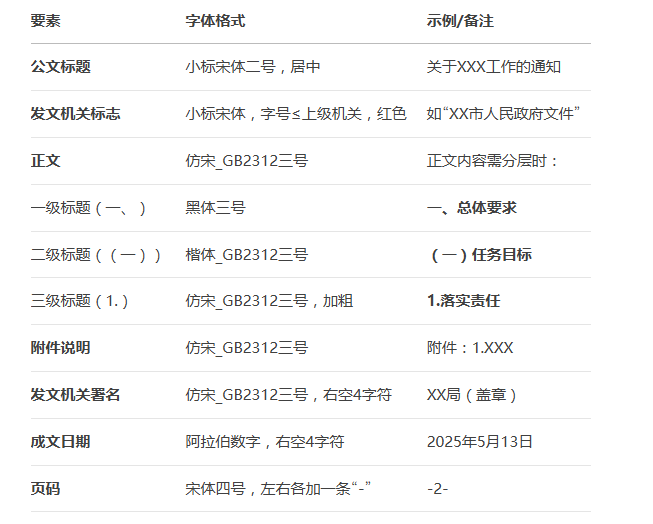
进而通过以上规则,找到去除红头、版记的规律如下:
1)识别判断文档中,字体为“方正小标宋简体”、字号为“14Pt”的标题段落,将标题之前的全部内容清除,包括文本、表格、图片、图形等。
2)识别判断文档中,最后1个单元格内容以“印发”结尾的最后1个表格,将其删除。
二、解题方案
通过AI辅助找到解题方案,如下:
通过Python语言编程,依赖docx库,经过“读取公文文件→通过代码处理红头和版记→另存为新文件”的过程,即可可完成对公文文档的转换处理。
三、解题过程
import os
from docx import Document
from docx.shared import Pt
from docx.oxml import OxmlElement
from docx.oxml.ns import qn
import util_doc
# 删除目标段落之前的所有元素(段落、表格、图片)
def delete_elements_before_target(doc, target_paragraph):
# 获取文档的 XML 结构
body = doc.element.body
# 遍历所有子元素,直到找到目标段落
for child in list(body):
# 如果当前元素是目标段落,则停止删除
if child == target_paragraph._element:
break
# 否则删除该元素(段落、表格、图片等)
body.remove(child)
# 删除文档中最后一个包含指定文本(如“印发”)的表格
def delete_last_table_with_text(doc, target_text="印发"):
# 获取文档的 XML 结构
body = doc.element.body
matching_tables = []
# 遍历所有表格,记录包含目标文本的表格
for table in doc.tables:
for row in table.rows:
for cell in row.cells:
if target_text in cell.text:
matching_tables.append(table._element) # 记录表格的 XML 元素
break # 找到即可跳出当前表格的检查
else:
continue # 如果内层循环未 break,则继续检查下一行
break # 如果内层循环 break,则跳出当前表格的检查
# 删除最后一个匹配的表格(如果存在)
if matching_tables:
last_table = matching_tables[-1] # 取最后一个
body.remove(last_table)
print(f"版记处理:已删除最后一个单元格包含文本“{target_text}”的表格")
else:
print(f"版记处理:未找到包含文本“{target_text}”的表格,无需版记")
# 主函数:去除红头、版记执行函数
def find_and_truncate_doc(input_path):
# 读取输入文件名和后缀
dir_name, file_name = os.path.split(input_path) # 分离目录和文件名
name, ext = os.path.splitext(file_name) # 分离文件名和扩展名
if ext == ".doc":
input_path = util_doc.convert_doc_to_docx(input_path) # 如果是.doc,转换为.docx
ext = ".docx"
# 组装新文件名(在原文件名后添加 "_exchanged")
output_name = f"{name}_exchanged{ext}"
output_path = os.path.join(dir_name, output_name) # 保持原目录
# 打开文档
doc = Document(input_path)
target_paragraph = None
# 遍历所有段落,寻找符合条件的段落
for paragraph in doc.paragraphs:
for run in paragraph.runs:
font = run.font
if font.name == "方正小标宋简体" and font.size and font.size == Pt(22):
if '' != paragraph.text.strip():
target_paragraph = paragraph
break
if target_paragraph is not None:
break
if target_paragraph is None:
print("红头处理:未找到正文标题,无法处理红头!")
return
# 删除目标段落之前的所有内容(包括文本、表格、图片)
delete_elements_before_target(doc, target_paragraph)
# 删除文档末尾的表格(如果存在)
delete_last_table_with_text(doc)
# 保存修改后的文档
doc.save(output_path)
print(f"[红头、版记]处理完成,结果已保存至: {output_path}")
# 示例调用
find_and_truncate_doc("demofiles\\xxx单位关于“xxxx”征求意见的函.docx")
三、解题复盘
通过以上代码可以基本完成公文转换的处理,但是也遇到一些特殊情况需要处理,如下:
1)python的docx库只能处理.docx和.wps的word文件,不支持.doc文件处理
需要先通过其它工具将.doc转为.docx(有个扩展方案:使用 libreoffice转换.doc到.docx,但是依然存在转换后内容排版错乱问题,比如段落首行缩进的差异)
2)以上方案在识别标题时,存在识别不到的情况,导致删除红头“不干净”或“删多了”
主要原因是以上方案是通过“循环段落”的方式进行查找和处理的,有些文档的结构复杂所以没识别到。需要将该情况反馈给AI继续优化处理方案,换了个方式识别标题就更准确,如下:
改善思路:先识别标题的行号,在通过标题行号值,删除前面的所有行。
from docx import Document
from docx.shared import Pt
from docx.oxml import parse_xml
from docx.oxml.ns import qn
def find_first_line_with_font_improved(docx_path, font_name="方正小标宋简体", font_size=22):
"""
改进版的docx字体查找函数,能更准确地识别格式
参数:
docx_path: Word文档路径
font_name: 要查找的字体名称
font_size: 要查找的字号(磅值)
返回:
找到的第一行文字及其段落索引
"""
doc = Document(docx_path)
for i, paragraph in enumerate(doc.paragraphs):
# 检查整个段落的默认格式
if (paragraph.style.font.name == font_name and
paragraph.style.font.size and
paragraph.style.font.size.pt == font_size):
return paragraph.text, i
# 检查段落中的每个run(文本片段)
for run in paragraph.runs:
# 检查显式设置的字体属性
explicit_font = run.font
if (explicit_font.name and explicit_font.name == font_name and
explicit_font.size and explicit_font.size.pt == font_size):
return paragraph.text, i
# 检查继承自样式的字体属性
if run._element.rPr is not None:
rPr = run._element.rPr
# 检查字体
if rPr.rFonts is not None:
font_eastasia = rPr.rFonts.get(qn("w:eastAsia"), None)
if font_eastasia == font_name:
# 检查字号
sz = rPr.find(qn("w:sz"))
if sz is not None and int(sz.get(qn("w:val"))) == font_size * 2:
return paragraph.text, i
return None, -1
# 使用示例
file_path = "demofiles\\“XXXX”工作推进专题会议纪要.docx"
font_name = "方正小标宋简体"
font_size = 22 # 二号字
text, para_idx = find_first_line_with_font_improved(file_path, font_name, font_size)
print("匹配到的行::",text)
if text:
print(f"找到的第一行文字(段落{para_idx + 1}): {text}")
else:
print("未找到符合要求的文字")
from docx import Document
from docx.oxml import OxmlElement
from docx.oxml.ns import qn
def delete_all_content_before_line(docx_path, output_path, target_line_num):
"""
删除文档中指定行号之前的所有内容(包括文字、表格、图片、形状等)
增强版:处理footnotes_part错误并完善删除逻辑
参数:
docx_path: 输入文档路径
output_path: 输出文档路径
target_line_num: 目标行号(从1开始计数)
"""
doc = Document(docx_path)
# 验证目标行号是否有效
if target_line_num < 1 or target_line_num > len(doc.paragraphs):
print(f"错误:行号 {target_line_num} 超出范围(文档共 {len(doc.paragraphs)} 段)")
return
# 获取文档主体中的所有元素
body = doc.element.body
# 找到目标段落元素
target_paragraph = doc.paragraphs[target_line_num - 1]._element
# 收集需要删除的元素
elements_to_remove = []
current_element = body[0]
# 遍历文档主体中的所有元素
while current_element is not None and current_element != target_paragraph:
elements_to_remove.append(current_element)
current_element = current_element.getnext()
# 删除所有需要移除的元素
for element in elements_to_remove:
body.remove(element)
# 清空所有页眉页脚(更安全的实现)
for section in doc.sections:
# 处理页眉
for header in [section.header, getattr(section, 'first_page_header', None)]:
if header is not None:
for element in list(header._element):
header._element.remove(element)
# 处理页脚
for footer in [section.footer, getattr(section, 'first_page_footer', None)]:
if footer is not None:
for element in list(footer._element):
footer._element.remove(element)
# 更安全的尾注处理(兼容不同python-docx版本)
try:
if hasattr(doc._part, 'footnotes_part'):
for footnote in doc._part.footnotes_part.footnotes:
footnote._element.clear()
except Exception as e:
print(f"处理尾注时出现警告: {str(e)}")
# 处理文档属性(可选)
doc_props = doc.core_properties
doc_props.title = "处理后的文档"
doc_props.author = "Python处理"
# 保存文档
doc.save(output_path)
print(f"已成功删除第 {target_line_num} 行之前的所有内容,结果保存到: {output_path}")
# 使用示例
input_file = "demofiles\\关于报送《xxxxxx》的函.docx"
output_file = "demofiles\\处理后的文档.docx"
target_line = 7 # 要保留的行号(从该行开始保留)
delete_all_content_before_line(input_file, output_file, target_line)
四、总结
最终通过调试优化,彻底解决了公文文档“去除红头和版记”的技术问题,技术总结如下:
1)遇到问题多借助AI工具,能够快速理清解决思路,评估是否可行性;
2)优先使用Python做尝试和验证(有简单、快速的优势),然后再转其它项目语言进行实现,Java也可以;
3)AI工具也不是万能的,他给的方案不具备普适性,需要针对出现的问题进行调试优化;
用心沉淀,持续完善更新,欢迎留言交流 ~


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









