







目录
一.系统概述
1.系统功能介绍
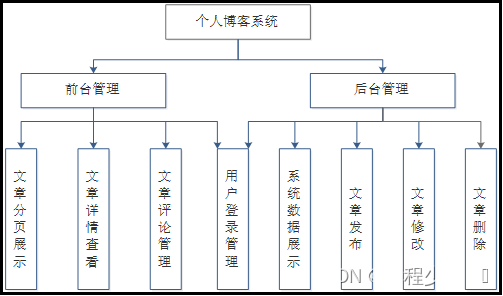
注: 前台使用Spring Boot支持的模板引擎Thymeleaf+jQuery完成页面信息展示 后台使用Spring MVC+Spring Boot+MyBatis框架进行整合开发
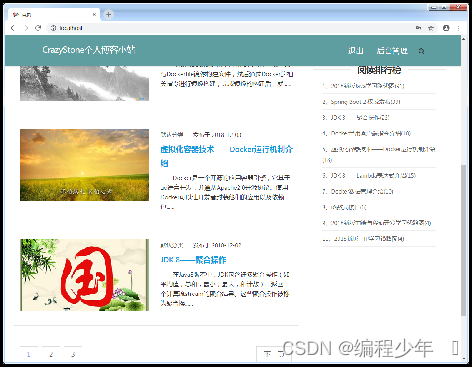
2.项目效果预览
首页预览
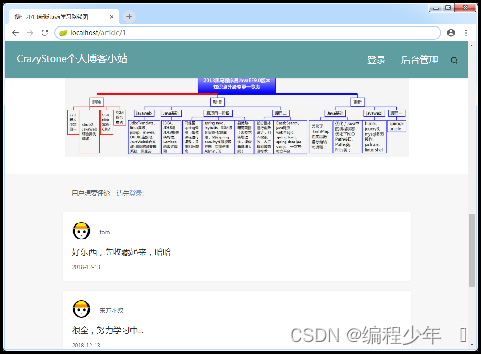
文章详情页预览
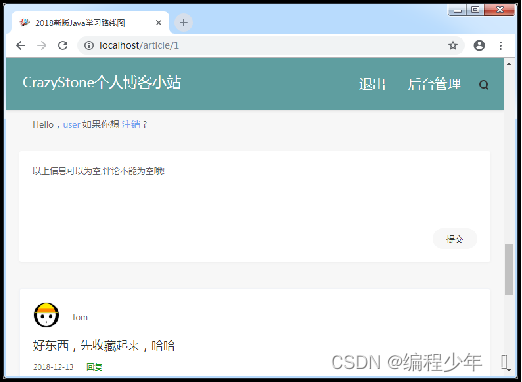
文章评论页预览
后台首页预览
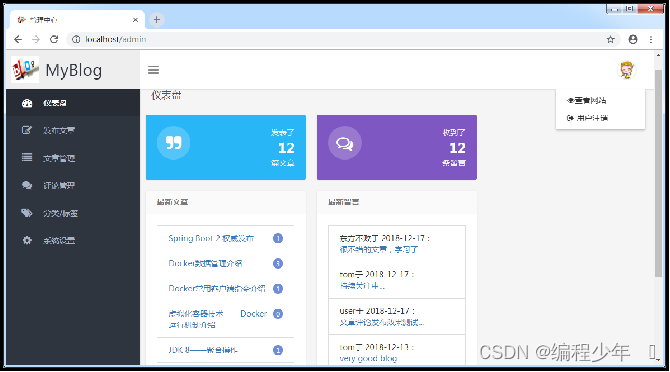
后台文件编辑页面预览
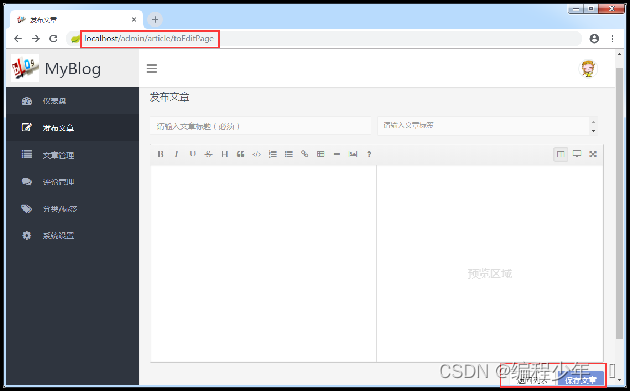
后台文章管理列表页面预览
二.项目设计
1.系统开发及运行环境
系统开发所需的环境及相关软件
操作系统:Windows
Java开发包:JDK 8
项目管理工具:Maven 3.6.0
项目开发工具:IntelliJ IDEA
数据库:MySQL
缓存管理工具:Redis 3.2.100
浏览器:谷歌浏览器
2.文件组织结构
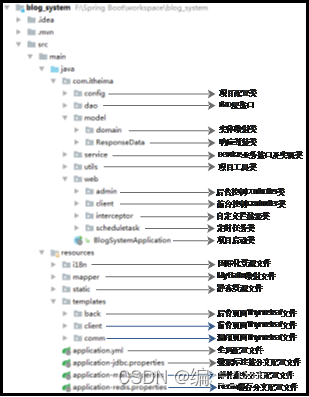
3.数据库设计
创建blog_system数据库
/*
Navicat MySQL Data Transfer
Source Server : mysql
Source Server Version : 50720
Source Host : localhost:3306
Source Database : blog_system
Target Server Type : MYSQL
Target Server Version : 50720
File Encoding : 65001
Date: 2018-12-13 16:54:34
*/
SET FOREIGN_KEY_CHECKS=0;
-- ----------------------------
-- Table structure for `t_article`
-- ----------------------------
DROP TABLE IF EXISTS `t_article`;
CREATE TABLE `t_article` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`title` varchar(50) NOT NULL COMMENT '文章标题',
`content` longtext COMMENT '文章具体内容',
`created` date NOT NULL COMMENT '发表时间',
`modified` date DEFAULT NULL COMMENT '修改时间',
`categories` varchar(200) DEFAULT '默认分类' COMMENT '文章分类',
`tags` varchar(200) DEFAULT NULL COMMENT '文章标签',
`allow_comment` tinyint(1) NOT NULL DEFAULT '1' COMMENT '是否允许评论',
`thumbnail` varchar(200) DEFAULT NULL COMMENT '文章缩略图',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of t_article
-- ----------------------------
INSERT INTO `t_article` VALUES ('1', '2018新版Java学习路线图', '    播妞深知广大爱好Java的人学习是多么困难,没视频没资源,上网花钱还老担心被骗。因此专门整理了新版的学习路线图,不管你是不懂电脑的小白,还是已经步入开发的大牛,这套路线图绝对不容错过!12年传智播客黑马程序员分享免费视频教程长达10余万小时,累计下载量3000余万次,受益人数达千万。2018年我们不忘初心,继续前行。 路线图的宗旨就是分享,专业,便利,让喜爱Java的人,都能平等的学习。从今天起不要再找借口,不要再说想学Java却没有资源,赶快行动起来,Java等你来探索,高薪距你只差一步!\r\n\r\n**一、2018新版Java学习路线图---每阶段市场价值及可解决的问题**\r\n\r\n\r\n**二、2018新版Java学习路线图---学习大纲及各阶段知识点**\r\n\r\n\r\n\r\n\r\n**三、2018新版Java学习路线图---升级后新增知识点一览**\r\n\r\n\r\n\r\n\r\n', '2018-10-10', null, '默认分类', '2018,Java,学习路线图', '1', null);
INSERT INTO `t_article` VALUES ('2', '2018新版Python学习线路图', '    12年历经风雨,传智播客黑马程序员已免费分享视频教程长达10万余小时,累计下载量超2000万次,受益人数达千万。2018年我们不忘初心,继续前行。学习路线图的宗旨就是分享,专业,便利,让喜爱Python的人,都能平等的学习。据悉,Python已经入驻小学生教材,未来不学Python不仅知识会脱节,可能与小朋友都没有了共同话题~~所以,从今天起不要再找借口,不要再说想学Python却没有资源,赶快行动起来,Python等你来探索,高薪距你只差一步!\r\n\r\n**一、2018新版Python学习路线图---每阶段市场价值及可解决的问题**\r\n\r\n\r\n\r\n\r\n**二、2018新版Python学习路线图---学习大纲及各阶段知识点**\r\n\r\n\r\n\r\n\r\n**三、2018新版Python学习路线图---升级版Python成长路径**\r\n\r\n\r\n', '2018-10-24', null, '默认分类', '2018,Python,学习线路图', '1', null);
INSERT INTO `t_article` VALUES ('3', '2018新版前端与移动开发学习线路图', '    传智播客黑马程序员作为一个IT学习平台,历经12年的成长,免费分享视频教程长达10万余小时,累计下载量超3000万次,受益人数达千万。2018年我们不忘初心,继续前行!路线图的宗旨就是分享,专业,便利,让更多想要学习IT的人都能系统的学习!从今天起不要再找借口,不要再说想学却没有资源,赶快行动起来,前端与移动开发等你来探索,高薪距你只差一步!注:新版前端与移动开发学习大纲于2018年2月26日完成升级,本学习路线图依据最新升级后的规划制作!\r\n\r\n**一、2018新版前端与移动开发学习路线图---每阶段可掌握的能力及可解决的问题**\r\n\r\n\r\n\r\n\r\n**二、2018新版前端与移动开发学习路线图---学习大纲及各阶段知识点**\r\n\r\n\r\n\r\n\r\n**三、2018新版前端与移动开发学习路线图--升级后新增知识点设计理念**\r\n', '2018-11-13', null, '默认分类', '2018,前端与移动,学习线路图', '1', null);
INSERT INTO `t_article` VALUES ('4', '2018新版PHP学习线路图', '    传智播客黑马程序员作为一个IT学习平台,历经12年的成长,免费分享视频教程长达10万余小时,累计下载量超3000万次,受益人数达千万。2018年我们不忘初心,继续前行!路线图的宗旨就是分享,专业,便利,让更多喜爱PHP的人都能系统的学习!从今天起不要再找借口,不要再说想学PHP却没有资源,赶快行动起来,PHP等你来探索,高薪距你只差一步!\r\n\r\n**一、2018新版PHP学习路线图---每阶段市场价值及可解决的问题**\r\n\r\n\r\n\r\n\r\n**二、2018新版PHP学习路线图---学习大纲及各阶段知识点**\r\n\r\n\r\n\r\n\r\n**三、2018新版PHP学习路线图---升级后新增知识点设计理念**\r\n\r\n', '2018-11-16', null, '默认分类', '2018,PHP,学习线路图', '1', null);
INSERT INTO `t_article` VALUES ('5', '2018版Go语言+区块链学习线路图', '    12年传智播客黑马程序员分享免费视频教程长达10万余小时,累计下载量超3000万次,受益人数达千万。2018年我们不忘初心,继续前行。 路线图的宗旨就是分享,专业,便利,让喜爱Go语言+区块链的人,都能平等的学习。从今天起不要再找借口,不要再说想学Go语言+区块链却没有资源,赶快行动起来,Go语言+区块链等你来探索,高薪距你只差一步!\r\n\r\n**一、2018新版Go语言+区块链学习路线图---每阶段市场价值及可解决的问题**\r\n\r\n\r\n\r\n\r\n**二、2018新版Go语言+区块链学习路线图---每阶段可掌握的核心能力**\r\n\r\n\r\n**三、2018新版Go语言+区块链学习路线图---每阶段的设计理念**\r\n\r\n\r\n**四、2018新版Go语言+区块链学习路线图---学习大纲及各阶段知识点**\r\n\r\n\r\n', '2018-11-27', null, '默认分类', '2018,Go语言,区块链,学习线路图', '1', null);
INSERT INTO `t_article` VALUES ('6', 'JDK 8——Lambda表达式介绍', ' Lambda表达式是JDK 8中一个重要的新特性,它使用一个清晰简洁的表达式来表达一个接口,同时Lambda表达式也简化了对集合以及数组数据的遍历、过滤和提取等操作。下面,本篇文章就对Lambda表达式进行简要介绍,并进行演示说明。\r\n\r\n**1. Lambda表达式入门** \r\n\r\n 匿名内部类存在的一个问题是,如果匿名内部类的实现非常简单,例如只包含一个抽象方法的接口,那么匿名内部类的语法仍然显得比较冗余。为此,JDK 8中新增了一个特性Lambda表达式,这种表达式只针对有一个抽象方法的接口实现,以简洁的表达式形式实现接口功能来作为方法参数。 \r\n 一个Lambda表达式由三个部分组成,分别为参数列表、“->”和表达式主体,其语法格式如下:\r\n```js\r\n ([数据类型 参数名,数据类型 参数名,...]) -> {表达式主体}\r\n``` \r\n 从上述语法格式上看,Lambda表达式的书写非常简单,下面针对Lambda表达式的组成部分进行简单介绍,具体如下: \r\n (1)([数据类型 参数名,数据类型 参数名,...]):用来向表达式主体传递接口方法需要的参数,多个参数名中间必须用英文逗号“,”进行分隔;在编写Lambda表达式时,可以省略参数的数据类型,后面的表达式主体会自动进行校对和匹配;同时,如果只有一个参数,则可以省略括号“()”。 \r\n (2)->:表示Lambda表达式箭牌,用来指定参数数据指向,不能省略,且必须用英文横线和大于号书写。 \r\n (3){表达式主体}:由单个表达式或语句块组成的主体,本质就是接口中抽象方法的具体实现,如果表达式主体只有一条语句,那么可以省略包含主体的大括号;另外,在Lambda表达式主体中允许有返回值,当只有一条return语句时,也可以省略return关键字。 \r\n 了解了Lambda表达式的语法后,接下来编写一个示例文件对Lambda表达式的基本使用进行介绍,具体代码如下所示。\r\n```js\r\n 1 // 定义动物类接口\r\n 2 interface Animal { \r\n 3 void shout(); // 定义方法shout()\r\n 4 }\r\n 5 public class Example22 {\r\n 6 public static void main(String[] args) {\r\n 7 String name = \"小花\"; \r\n 8 // 1、匿名内部类作为参数传递给animalShout()方法\r\n 9 animalShout(new Animal() { \r\n 10 public void shout() { \r\n 11 System.out.println(\"匿名内部类输出:\"+name+\"喵喵...\");\r\n 12 }\r\n 13 });\r\n 14 // 2、使用Lambda表达式作为参数传递给animalShout()方法\r\n 15 animalShout(()-> System.out.println(\"Lambda表达式输出:\"\r\n 16 +name+\"喵喵...\"));\r\n 17 }\r\n 18 // 创建一个animalShout()静态方法,接收接口类型的参数\r\n 19 public static void animalShout(Animal an) {\r\n 20 an.shout(); \r\n 21 }\r\n 22 }\r\n``` \r\n 运行结果下图所示。\r\n\r\n 上述代码示例中,先定义了只有一个抽象方法的接口Animal,然后分别使用匿名内部类和Lambda表达式的方式实现了接口方法。从图中可以看出,使用匿名内部类和Lambda表达式都能实现接口中方法,但很显然使用Lambda表达式更加简洁和清晰。', '2018-11-27', null, '默认分类', '2018,Lambda表达式', '1', null);
INSERT INTO `t_article` VALUES ('7', '函数式接口', '  虽然Lambda表达式可以实现匿名内部类的功能,但在使用时却有一个局限,即接口中有且只有一个抽象方法时才能使用Lamdba表达式代替匿名内部类。这是因为Lamdba表达式是基于函数式接口实现的,所谓函数式接口是指有且仅有一个抽象方法的接口,Lambda表达式就是Java中函数式编程的体现,只有确保接口中有且仅有一个抽象方法,Lambda表达式才能顺利地推导出所实现的这个接口中的方法。 \r\n  在JDK 8中,专门为函数式接口引入了一个@FunctionalInterface注解,该注解只是显示的标注了接口是一个函数式接口,并强制编辑器进行更严格的检查,确保该接口是函数式接口,如果不是函数式接口,那么编译器就会报错,而对程序运行并没有实质上的影响。 \r\n  接下来通过一个案例来演示函数式接口的定义与使用,示例代码如下所示。\r\n```js\r\n 1 // 定义无参、无返回值的函数式接口\r\n 2 @FunctionalInterface\r\n 3 interface Animal {\r\n 4 void shout();\r\n 5 }\r\n 6 // 定义有参、有返回值的函数式接口\r\n 7 interface Calculate {\r\n 8 int sum(int a, int b);\r\n 9 }\r\n 10 public class Example23 {\r\n 11 public static void main(String[] args) {\r\n 12 // 分别两个函数式接口进行测试\r\n 13 animalShout(() -> System.out.println(\"无参、无返回值的函数式接口调用\"));\r\n 14 showSum(10, 20, (x, y) -> x + y);\r\n 15 }\r\n 16 // 创建一个动物叫的方法,并传入接口对象Animal作为参数\r\n 17 private static void animalShout(Animal animal) {\r\n 18 animal.shout();\r\n 19 }\r\n 20 // 创建一个求和的方法,并传入两个int类型以及接口Calculate类型的参数\r\n 21 private static void showSum(int x, int y, Calculate calculate) {\r\n 22 System.out.println(x + \"+\" + y + \"的和为:\" + calculate.sum(x, y));\r\n 23 }\r\n 24 }\r\n``` \r\n  运行结果如下图所示。\r\n\r\n\r\n  上述代码示例中,先定义了两个函数式接口Animal和Calculate,然后在测试类中分别编写了两个静态方法,并将这两个函数式接口以参数的形式传入,最后在main()方法中分别调用这两个静态方法,并将所需要的函数式接口参数以Lambda表达式的形式传入。从图中可以看出,程序中函数式接口的定义和使用完全正确。\r\n', '2018-12-01', null, '默认分类', '接口,函数式接口', '1', null);
INSERT INTO `t_article` VALUES ('8', 'JDK 8——聚合操作', '  在Java8版本中,JDK包含许多聚合操作(如平均值,总和,最小,最大,和计数),返回一个计算流stream的聚合结果。这些聚合操作被称为聚合操作。JDK除返回单个值的聚合操作外,还有很多聚合操作返回一个collection集合实例。很多的reduce操作执行特定的任务,如求平均值或按类别分组元素。 \r\n\r\n**1. 聚合操作简介**\r\n\r\n 在开发中,多数情况下会涉及到对集合、数组中元素的操作,在JDK 8之前都是通过普通的循环遍历出每一个元素,然后还会穿插一些if条件语句选择性的对元素进行查找、过滤、修改等操作,这种原始的操作方法虽然可行,但是代码量较大并且执行效率较低。 \r\n 为此,JDK 8中新增了一个Stream接口,该接口可以将集合、数组的中的元素转换为Stream流的形式,并结合Lambda表达式的优势来进一步简化集合、数组中元素的查找、过滤、转换等操作,这一新功能就是JDK 8中的聚合操作。 \r\n 在程序中,使用聚合操作没有绝对的语法规范,根据实际操作流程,主要可以分为以下3个步骤: \r\n (1)将原始集合或者数组对象转换为Stream流对象; \r\n (2)对Stream流对象中的元素进行一系列的过滤、查找等中间操作(Intermediate Operations),然后仍然返回一个Stream流对象; \r\n (3)对Stream流进行遍历、统计、收集等终结操作(Terminal Operation),获取想要的结果。 \r\n 接下来,就根据上面聚合操作的3个步骤,通过一个案例来演示聚合操作的基本用法,具体示例代码如下所示。\r\n```js\r\n 1 import java.util.*;\r\n 2 import java.util.stream.Stream;\r\n 3 public class Example31 {\r\n 4 public static void main(String[] args) {\r\n 5 // 创建一个List集合对象\r\n 6 List<String> list = new ArrayList<>(); \r\n 7 list.add(\"张三\");\r\n 8 list.add(\"李四\");\r\n 9 list.add(\"张小明\");\r\n 10 list.add(\"张阳\");\r\n 11 // 1、创建一个Stream流对象\r\n 12 Stream<String> stream = list.stream();\r\n 13 // 2、对Stream流中的元素分别进行过滤、截取操作\r\n 14 Stream<String> stream2 = stream.filter(i -> i.startsWith(\"张\"));\r\n 15 Stream<String> stream3 = stream2.limit(2);\r\n 16 // 3、对Stream流中的元素进行终结操作,进行遍历输出\r\n 17 stream3.forEach(j -> System.out.println(j));\r\n 18 System.out.println(\"=======\");\r\n 19 // 通过链式表达式的形式完成聚合操作\r\n 20 list.stream().filter(i -> i.startsWith(\"张\"))\r\n 21 .limit(2)\r\n 22 .forEach(j -> System.out.println(j));\r\n 23 }\r\n 24 }\r\n``` \r\n 运行结果如下图所示。\r\n\r\n 上述示例代码中,先创建了一个List集合,然后根据聚合操作的3个步骤实现了集合对象的聚合操作,对集合中的元素使用Stream流的形式进行过滤(filter)、截取(limit),并进行遍历输出。其中第12~17行代码分步骤详细展示了聚合操作,而第20~22行代码是使用了链式表达式(调用有返回值的方法时不获取返回值而是直接再调用另一个方法)实现了聚合操作,该表达式的语法格式更简洁、高效,这种链式调用也被称为操作管道流。\r\n\r\n**2. 创建Stream流对象** \r\n 在上一小节中,介绍了聚合操作的主要使用步骤,其中首要解决的问题就是创建Stream流对象。聚合操作针对的就是可迭代数据进行的操作,如集合、数组等,所以创建Stream流对象其实就是将集合、数组等通过一些方法转换为Stream流对象。 \r\n 在Java中,集合对象有对应的集合类,可以通过集合类提供的静态方法创建Stream流对象,而数组数据却没有对应的数组类,所以必须通过其他方法创建Stream流对象。针对不同的源数据,Java提供了多种创建Stream流对象的方式,分别如下: \r\n (1)所有的Collections集合都可以使用stream()静态方法获取Stream流对象; \r\n (2)Stream接口的of()静态方法可以获取基本类型包装类数组、引用类型数组和单个元素的Stream流对象; \r\n (3)Arrays数组工具类的stream()静态方法也可以获取数组元素的Stream流对象。 \r\n 接下来,通过一个案例来学习聚合操作中如何创建Stream流对象,具体示例代码如下所示。\r\n```js\r\n 1 import java.util.*;\r\n 2 import java.util.stream.Stream;\r\n 3 public class Example32 {\r\n 4 public static void main(String[] args) {\r\n 5 // 创建一个数组\r\n 6 Integer[] array = { 9, 8, 3, 5, 2 }; \r\n 7 // 将数组转换为List集合\r\n 8 List<Integer> list = Arrays.asList(array); \r\n 9 // 1、使用集合对象的stream()静态方法创建Stream流对象\r\n 10 Stream<Integer> stream = list.stream();\r\n 11 stream.forEach(i -> System.out.print(i+\" \"));\r\n 12 System.out.println();\r\n 13 // 2、使用Stream接口的of()静态方法创建Stream流对象\r\n 14 Stream<Integer> stream2 = Stream.of(array);\r\n 15 stream2.forEach(i -> System.out.print(i+\" \"));\r\n 16 System.out.println();\r\n 17 // 3、使用Arrays数组工具类的stream()静态方法创建Stream流对象\r\n 18 Stream<Integer> stream3 = Arrays.stream(array);\r\n 19 stream3.forEach(i -> System.out.print(i+\" \"));\r\n 20 }\r\n 21 }\r\n``` \r\n 运行结果如下图所示。\r\n\r\n 上述示例代码中,先创建了一个数组和一个集合,然后通过三种方式实现了Stream流对象的创建,并通过Stream流对象的forEach()方法结合Lambda表达式完成了集合和数组中元素的遍历。 \r\n\r\n**小提示:** \r\n 在JDK 8中,只针对单列集合Collections接口对象提供了stream()静态方法获取Stream流对象,并未对Map集合提供相关方法获取Stream流对象,所以想要用Map集合创建Stream流对象必须先通过Map集合的keySet()、values()、entrySet()等方法将Map集合转换为单列Set集合,然后再使用单列集合的stream()静态方法获取对应键、值集合的Stream流对象。\r\n\r\n', '2018-12-02', null, '默认分类', 'JDK 8,聚合操作', '1', null);
INSERT INTO `t_article` VALUES ('9', '虚拟化容器技术——Docker运行机制介绍', ' Docker是一个开源的应用容器引擎,它基于go语言开发,并遵从Apache2.0开源协议。使用Docker可以让开发者封装他们的应用以及依赖包到一个可移植的容器中,然后发布到任意的Linux机器上,也可以实现虚拟化。Docker容器完全使用沙箱机制,相互之间不会有任何接口,这保证了容器之间的安全性。 \r\n\r\n**1. Docker的引擎介绍**\r\n\r\n Docker Engine(Docker引擎)是Docker的核心部分,使用的是客户端-服务器(C/S)架构模式,其主要组成部分如下图所示。\r\n\r\n 从上图可以看出,Docker Engine中包含了三个核心组件(docker CLI、REST API和docker daemon),这三个组件的具体说明如下: \r\n ①docker CLI(command line interface):表示Docker命令行接口,开发者可以在命令行中使用Docker相关指令与Docker守护进程进行交互,从而管理诸如image(镜像)、container(容器)、network(网络)和data volumes(数据卷)等实体。 \r\n ②REST API:表示应用程序API接口,开发者通过该API接口可以与Docker的守护进程进行交互,从而指示后台进行相关操作。 \r\n ③docker daemon:表示Docker的服务端组件,他是Docker架构中运行在后台的一个守护进程,可以接收并处理来自命令行接口及API接口的指令,然后进行相应的后台操作。 \r\n 对于开发者而言,既可以使用编写好的脚本文件通过REST API来实现与Docker进程交互,又可以直接使用Docker相关指令通过命令行接口来与Docker进程交互,而其他一些Docker应用则是通过底层的API和CLI进行交互的。\r\n\r\n**2. Docker的架构介绍**\r\n\r\n 了解了Docker内部引擎及作用后,我们还需要通过Docker的具体架构,来了解Docker的整个运行流程。接下来借助Docker官网的架构图来对Docker架构进行详细说明,如下图所示。\r\n\r\n 从图中可以看出,Docker架构主要包括Client、DOCKER_HOST和Register三部分,关于这三部分的具体说明如下。 \r\n  **(1)Client(客户端)** \r\n Client即Docker客户端,也就是上一小节Docker Engine中介绍的docker CLI。开发者通过这个客户端使用Docker的相关指令与Docker守护进程进行交互,从而进行Docker镜像的创建、拉取和运行等操作。 \r\n  **(2)DOCKER_HOST(Docker主机)** \r\n DOCKER_HOST即Docker内部引擎运行的主机,主要指Docker daemon(Docker守护进程)。可以通过Docker守护进程与客户端还有Docker的镜像仓库Registry进行交互,从而管理Images(镜像)和Containers(容器)等。 \r\n  **(3)Registry(注册中心)** \r\n Registry即Docker注册中心,实质就是Docker镜像仓库,默认使用的是Docker官方远程注册中心Docker Hub,也可以使用开发者搭建的本地仓库。Registry中包含了大量的镜像,这些镜像可以是官网基础镜像,也可以是其他开发者上传的镜像。 \r\n 我们在实际使用Docker时,除了会涉及到图中的三个主要部分外,还会涉及到很多Docker Objects(Docker对象),例如Images(镜像)、Containers(容器)、Networks(网络)、Volumes(数据卷)、Plugins(插件)等。其中常用的两个对象Image和Containers的说明如下。 \r\n ①Images(镜像) \r\n Docker 镜像就是一个只读的模板,包含了一些创建Docker容器的操作指令。通常情况下,一个Docker镜像是基于另一个基础镜像创建的,并且新创建的镜像会额外包含一些功能配置。例如:开发者可以依赖于一个Ubuntu的基础镜像创建一个新镜像,并可以在新镜像中安装Apache等软件或其它应用程序。 \r\n ②Containers(容器) \r\n Docker容器属于镜像的一个可运行实例(镜像与容器的关系其实与Java中的类与对象相似),开发者可以通过API接口或者CLI命令行接口来创建、运行、停止、移动、删除一个容器,也可以将一个容器连接到一个或多个网络中,将数据存储与容器进行关联。\r\n\r\n\r\n\r\n', '2018-12-03', null, '默认分类', '虚拟化容器,Docker,运行机制', '1', null);
INSERT INTO `t_article` VALUES ('10', 'Docker常用客户端指令介绍', ' 在使用Docker之前,首先会为对应的项目编写Dockerfile镜像构建文件,然后通过Docker的相关指令进行镜像构建,完成镜像的构建后,就可以使用这些项目镜像进行启动测试了。所以要想知道如何使用Docker来执行这些Dockerfile镜像构建文件,还需要学习Docker客户端的常用指令,本篇文章将对Docker客户端的常用指令进行详细讲解。 \r\n\r\n**1.列出镜像** \r\n 通过docker images指令可以查看本地镜像列表中已有的镜像,具体使用方式如下。\r\n```js\r\n$ docker images\r\n``` \r\n 执行上述指令后,系统会将所有本地镜像都展示出来,如下图所示。\r\n\r\n 从图中可以看出,系统终端将本地镜像列表中的3个镜像分5列进行了展示,每一列的具体含义如下。 \r\n ●REPOSITORY:镜像名称。 \r\n ●TAG:镜像的参数,类似于版本号,默认是latest。 \r\n ●IMAGE ID:镜像ID,是唯一值。此处看到的是一个长度为12的字符串,实际上它是64位完整镜像ID的缩写形式。 \r\n ●CREATED:距今创建镜像的时间。 \r\n ●SIZE:镜像大小。 \r\n\r\n**2.搜索镜像** \r\n 想知道在Docker Hub中包含了哪些镜像,除了可以登录Docker Hub,在官网中心进行查看外,还可以直接在Docker客户端进行查询。例如想要查询Ubuntu镜像,可以使用如下指令。\r\n```js\r\n$ docker search ubuntu\r\n``` \r\n 执行上述指令后,系统终端就会将搜索到的有关Ubuntu的镜像展示出来,如下图所示。\r\n\r\n 从图所示的结果可以看出,系统终端分5列将搜索到的Ubuntu相关镜像都列举出来了,这5列的具体含义如下。 \r\n ●NAME:表示镜像的名称,这里有两种格式的名称,其中不带有“/”的表示官方镜像,而带有“/”的表示其他用户的公开镜像。公开镜像“/”前面是用户在Docker Hub上的用户名(唯一),后面是对应的镜像名;官方镜像与用户镜像,除了从镜像名称上可以区分外,还可以通过第4列的OFFICIAL声明中看出(该列下内容为OK表示官方镜像)。 \r\n ●DESCRIPTION:表示镜像的描述,这里只显示了一小部分。 \r\n ●STARS:表示该镜像的收藏数,用户可以在Docker Hub上对镜像进行收藏,一般可以通过该数字反应出该镜像的受欢迎程度。 \r\n ●OFFICIAL:表示是否为官方镜像。 \r\n ●AUTOMATED:表示是否自动构建镜像。例如,用户可以将自己的Docker Hub绑定到如Github上,当代码提交更新后,可以自动构建镜像。 \r\n \r\n**3.拉取镜像** \r\n 通过docker pull指令可以拉取仓库镜像到本地(默认都是拉取Docker Hub仓库镜像,也可以指定“IP+端口”拉取某个Docker机器上的私有仓库镜像),具体使用方式如下。\r\n```js\r\n$ docker pull ubuntu\r\n``` \r\n 执行上述指令后,Docker会自动从Docker Hub上下载最新版本的Ubuntu到本地,当然也可以使用以下指令拉取指定版本的镜像到本地,具体指令如下。\r\n```js\r\n$ docker pull ubuntu:14.04\r\n``` \r\n**4.构建镜像** \r\n 除了可以通过docker pull指令从仓库拉取镜像外,还可以通过docker build指令构建Docker镜像,通常情况下都是通过Dockerfile文件来构建镜像的。 \r\n 这里假设linux系统home目录下/shitou/workspace/dockerspace文件夹中编写有对应的Dockerfile文件,则构建镜像直立示例如下所示。 \r\n```js\r\n$ docker build -t hellodocker3 /home/shitou/workspace/dockerspace/.\r\n```\r\n**5.删除镜像** \r\n 当本地存放过多不需要的镜像时,可以通过docker rmi指令将其删除。在删除镜像时,需要指定镜像名称或镜像ID。删除镜像的使用方式如下。\r\n```js\r\n$ docker rmi -f hellodocker2 hellodocker3\r\n``` \r\n 上述指令中,docker rmi表示删除镜像,-f表示进行强制删除,而hellodocker2和hellodocker3分别表示需要删除的镜像名称,这里同时删除两个镜像。除了根据名称删除镜像外,还也可以根据镜像ID来删除镜像,只是这里如果指定了删除ID为23c617a866d4的镜像后,会同时删除hellodocker、hellodocker2和hellodocker3三个镜像。 \r\n 需要特别强调的是,在进行镜像删除操作时,如果是通过镜像ID进行镜像删除,那么由该镜像创建的容器必须提前删除或停止。另外,在通过镜像名称操作镜像时,如果出现镜像重名的情况,必须在镜像名称后面指定镜像标签tag参数来确保唯一性。\r\n\r\n**6.创建并启动容器** \r\n Docker镜像主要用于创建容器,可以使用docker run指令创建并启动容器,具体使用方式如下。\r\n```js\r\n$ docker run -d -p 5000:80 --name test hellodocker\r\n``` \r\n 上述创建并启动容器的指令略微复杂,具体分析如下。 \r\n ●docker run:表示创建并启动一个容器,而后面的hellodocker就表示要启动运行的镜像名称; \r\n ●-d:表示容器启动时在后台运行; \r\n ●-p 5000:80:表示将容器内暴露的80端口映射到宿主机指定的5000端口,也可以将-p 5000:80更改为-P来映射主机的随机端口(注意p字母的大小写); \r\n ●--name test:表示为创建后的容器指定名称为test,如果没有该参数配置,则生成的容器会设置一个随机名称。 \r\n docker run命令是Docker操作中较为复杂的一个,它可以携带多个参数和参数,我们可以通过docker run --help指令进行查看,其中有些参数如-e、-v和-w等都可以在Dockerfile文件中预先声明。 \r\n \r\n**7.列出容器** \r\n 生成容器后,可以通过docker ps指令查看当前运行的所有容器,具体使用方式如下。\r\n```js\r\n$ docker ps\r\n``` \r\n 执行上述命令后,会将所有当前运行的容器都展示出来,具体如下图所示。\r\n\r\n 从图中可以看出,系统终端通过7列对当前的正在运行的一个容器进行了展示,图中每一列的具体含义如下。 \r\n ●CONTAINER ID:表示生成的容器ID; \r\n ●IMAGE:表示生成该容器的镜像名称; \r\n ●COMMAND:表示启动容器时运行的命令,Docker要求在启动容器时必须运行一个命令; \r\n ●CREATED:表示容器创建的时间; \r\n ●STATUS:表示容器运行状态,例如Up表示运行中,Exited表示已停止; \r\n ●PORTS:表示容器内部暴露的端口映射到主机的端口; \r\n ●NAMES:表示生成容器的名称,由Docker引擎自动生成,可以像上述示例中使用--name参数指定生成容器的名称。 \r\n 另外,docker ps指令运行过程中可以指定多个参数,还可以通过docker ps --help指令对ps指令的其他信息进行查看。\r\n\r\n**8.删除容器** \r\n 当不需要使用容器时,则可以使用docker rm指令删除已停止的容器,具体使用方式如下。\r\n```js\r\n$ docker rm f0c9a8b6e8c5\r\n``` \r\n 需要注意的是,上述指令只能删除已经停止运行的容器,而不能删除正在运行的容器。如果想要删除正在运行的容器,则需要添加-f参数强制删除,具体使用方式如下。\r\n```js\r\n$ docker rm -f f0c9a8b6e8c5\r\n``` \r\n 当需要删除的容器过多时,如果还一个个的删除就略显麻烦了,此时可以通过如下指令将全部容器删除。\r\n```js\r\n$ docker rm -f $(docker ps -aq)\r\n``` \r\n 上述指令中,首先会通过$(docker ps -aq)获取所有容器的ID,然后通过docker rm -f指令进行强制删除。如果开发者有自己特殊的删除需求,可以根据前面docker ps指令进行组装来获取需要删除的容器ID。 \r\n Docker提供的操作指令远不止这些,这里就不一一列举了,想要了解更多Docker的操作指令,可以通过docker --help指令进行查看。\r\n\r\n\r\n', '2018-12-05', null, '默认分类', 'Docker,客户端指令', '1', null);
INSERT INTO `t_article` VALUES ('11', 'Docker数据管理介绍', ' 当我们对容器进行相关操作时,产生的一系列数据都会存储在容器中,而Docker内部又是如果管理这些数据的呢?本篇文章将针对Docker数据管理的一些知识进行介绍。\r\n \r\n**1. Docker数据存储机制** \r\n 使用Docker时,我们操作的都是镜像和由镜像生成的容器,所以想要更好的了解Docker内部的数据存储机制,就必须从镜像、容器与数据存储的关系出发。 \r\n Docker镜像是通过读取Dockerfile文件中的指令构建的,Dockerfile中的每条指令都会创建一个镜像层,并且每层都是只读的,这一系列的镜像层就构成了Docker镜像。接下来以一个Dockerfile文件为例进行说明,具体如下列代码示例所示。\r\n```js\r\n 1 FROM ubuntu:16.04\r\n 2 COPY . /app\r\n 3 RUN make /app\r\n 4 CMD python /app/app.py\r\n``` \r\n 上述文件示例中的Dockerfile包含了4条指令,每条指令都会创建一个镜像层,其中每一层与前一层都有所不同,并且是层层叠加的。通过镜像构建容器时,会在镜像层上增加一个容器层(即可写层),所有对容器的更改都会写入容器层,这也是Docker默认的数据存储方式。 \r\n 下面通过一个效果图进行说明,具体如下图所示。\r\n\r\n 从图中可以看出,Docker容器和镜像之间的主要区别是顶部的容器层,而所有对容器中数据的添加、修改等操作都会被存储在容器层中。当容器被删除时,容器层也会被删除,其中存储的数据会被一同删除,而下面的镜像层却保持不变。 \r\n 由于所有的容器都是通过镜像构建的,所以每个容器都有各自的容器层,对于容器数据的更改就会保存在各自的容器层中。也就是说,由同一个镜像构建的多个容器,它们会拥有相同的底部镜像层,而拥有不同的容器层,多个容器可以访问相同的镜像层,并且有自己的独立数据状态。具体说明如下图所示。 \r\n\r\n 从图中可以看出,基于同一个镜像构建的多个容器可以共享该镜像层,但是多个容器想要共享相同的数据,就需要将这些数据存储到容器之外的地方,而这种方式就是下一节要提到的Docker volume数据外部挂载机制。 \r\n\r\n**2. Docker数据存储方式** \r\n 在默认情况下,Docker中的数据都是存放在容器层的,但是这样存储数据却有较多的缺陷,具体表现如下。 \r\n ●当容器不再运行时,容器中的数据无法持久化保存,如果另一个进程需要这些数据,那么将很难从容器中获取数据; \r\n ●容器层与正在运行的主机紧密耦合,不能轻易地移动数据; \r\n ●容器层需要一个存储驱动程序来管理文件系统,存储驱动程序提供了一个使用Linux内核的联合文件系统,这种额外的抽象化降低了性能。 \r\n 基于上述种种原因,多数情况下Docker数据管理都不会直接将数据写入容器层,而是使用另一种叫做Docker volume数据外部挂载的机制进行数据管理。 \r\n 针对Docker volume数据外部挂载机制,Docker提供了三种不同的方式将数据从容器映射到Docker宿主机,他们分别为:volumes(数据卷)、bind mounts(绑定挂载)和tmpfs mounts(tmpfs挂载)。这三种数据管理方式的具体选择,需要结合实际情况进行考虑,其中的volumes数据卷是最常用也是官方推荐的数据管理方式。无论选择使用哪种数据管理方式,数据在容器内看起来都一样的,而在容器外则会被被挂载到文件系统中的某个目录或文件中。 \r\n 下面通过一张图来展示数据卷、绑定挂载和tmpfs挂载之间的差异,如下图所示。 \r\n\r\n 从图中可以看出,Docker提供的三种数据管理方式略有不同,具体分析如下。 \r\n ●volumes:存储在主机文件系统中(在Linux系统下是存在于/var/lib/Docker/volumes/目录),并由Docker管理,非Docker进程无法修改文件系统的这个部分。 \r\n ●bind mounts:可以存储在主机系统的任意位置,甚至可能是重要的系统文件或目录,在Docker主机或容器上的非Docker进程可以对他们进行任意修改。 \r\n ●tmpfs mounts:只存储在主机系统的内存中,并没有写入到主机的文件系统中。\r\n\r\n\r\n', '2018-12-07', null, '默认分类', 'Docker,数据管理', '1', null);
INSERT INTO `t_article` VALUES ('12', 'Spring Boot 2 权威发布', ' 如果这两天登录 [https://start.spring.io/ ](https://start.spring.io/ )就会发现,Spring Boot 默认版本已经升到了 2.1.0。这是因为 Spring Boot 刚刚发布了 2.1.0 版本,我们来看下 Spring Boot 2 发布以来第一个子版本都发布了哪些内容? \r\n\r\n**2.1 中的新特性** \r\n ●将spring-boot-starter-oauth2-oidc-client重命名为spring-boot-starter-oauth2-client命名更简洁 \r\n ●添加 OAuth2 资源服务 starter,OAuth2 一个用于认证的组件 \r\n ●支持 ConditionalOnBean 和 ConditionalOnMissingBean 下的参数化容器 \r\n ●自动配置 applicationTaskExecutor bean 的延迟加载来避免不必要的日志记录 \r\n ●将 DatabaseDriver#SAP 重命名为 DatabaseDriver \r\n ●跳过重启器不仅适用于 JUnit4,也适用于 JUnit5 \r\n ●在 Jest HealthIndicator 中使用集群端点 \r\n ●当 DevTools 禁用重启时添加日志输出 \r\n ●添加注解:@ConditionalOnMissingServletFilter提高 Servlet Filters 的自动装配。\r\n \r\n**2.1 中的组件升级** \r\n ●升级 Hibernate 5.3,Hibernate 的支持升级到了 5.3 \r\n ●升级 Tomcat 9 ,支持最新的 tomcat 9 \r\n ●支持 Java 11,Java 现在更新越来越快,Spring 快赶不上了 \r\n ●升级 Thymeleaf Extras Springsecurity 到 3.0.4.RELEASE ,thymeleaf-extras-springsecurity 是 Thymeleaf 提供集成 Spring Security 的组件 \r\n ●升级 Joda Time 2.10.1,Joda-Time, 面向 Java 应用程序的日期/时间库的替代选择,Joda-Time 令时间和日期值变得易于管理、操作和理解。 \r\n ●升级 Lettuce 5.1.2.RELEASE ,Lettuce 前面说过,传说中 Redis 最快的客户端。 \r\n ●升级 Reactor Californium-SR2 ,Californium 是物联网云服务的 Java COAP 实现。因此,它更专注的是可扩展性和可用性而不是像嵌入式设备那样关注资源效率。不过,Californium 也适合嵌入式的 JVM。 \r\n ●升级 Maven Failsafe Plugin 2.22.1 ,Maven 中的测试插件。 \r\n ●升级 Flyway 5.2.1 , Flyway是一款开源的数据库版本管理工具 \r\n ●升级 Aspectj 1.9.2 ,AspectJ 是 Java 中流行的 AOP(Aspect-oriented Programming)编程扩展框架,是 Eclipse 托管给 Apache 基金会的一个开源项目。 \r\n ●升级 Mysql 8.0.13 ,Mysql 支持到 8。 \r\n ●... \r\n  更多的详细内容可以参考这里:[Spring Boot 2.1 Release Notes](https://github.com/spring-projects/spring-boot/wiki/Spring-Boot-2.1-Release-Notes)\r\n', '2018-12-12', null, '默认分类', 'Spring Boot 2', '1', null);
-- ----------------------------
-- Table structure for `t_comment`
-- ----------------------------
DROP TABLE IF EXISTS `t_comment`;
CREATE TABLE `t_comment` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '评论id',
`article_id` int(11) NOT NULL COMMENT '关联的文章id',
`created` date NOT NULL COMMENT '评论时间',
`ip` varchar(200) DEFAULT NULL COMMENT '评论用户登录的ip地址',
`content` text NOT NULL COMMENT '评论内容',
`status` varchar(200) NOT NULL DEFAULT 'approved' COMMENT '评论状态',
`author` varchar(200) NOT NULL COMMENT '评论用户用户名',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of t_comment
-- ----------------------------
INSERT INTO `t_comment` VALUES ('1', '12', '2018-12-13', '0:0:0:0:0:0:0:1', '很不错,不过这文章排版不太好看啊', 'approved', '李四');
INSERT INTO `t_comment` VALUES ('2', '11', '2018-12-13', '0:0:0:0:0:0:0:1', '很不错的原理分析,受用了!', 'approved', '李四');
INSERT INTO `t_comment` VALUES ('3', '10', '2018-12-13', '0:0:0:0:0:0:0:1', '关于Docker虚拟容器的讲解挺好的额,学习中', 'approved', '李四');
INSERT INTO `t_comment` VALUES ('9', '1', '2018-12-13', '0:0:0:0:0:0:0:1', '非常不错,赞一个!', 'approved', '李四');
INSERT INTO `t_comment` VALUES ('10', '1', '2018-12-13', '0:0:0:0:0:0:0:1', '博主,这资料怎么弄的?有相关资源和教材推荐吗?', 'approved', '李四');
INSERT INTO `t_comment` VALUES ('11', '1', '2018-12-13', '0:0:0:0:0:0:0:1', '很详细,感谢...', 'approved', '东方不败');
INSERT INTO `t_comment` VALUES ('12', '1', '2018-12-13', '0:0:0:0:0:0:0:1', '很全,努力学习中...', 'approved', '东方不败');
INSERT INTO `t_comment` VALUES ('13', '1', '2018-12-13', '0:0:0:0:0:0:0:1', '好东西,先收藏起来,哈哈', 'approved', 'tom');
INSERT INTO `t_comment` VALUES ('14', '8', '2018-12-13', '0:0:0:0:0:0:0:1', 'very good blog', 'approved', 'tom');
-- ----------------------------
-- Table structure for `t_authority`
-- ----------------------------
DROP TABLE IF EXISTS `t_authority`;
CREATE TABLE `t_authority` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`authority` varchar(200) DEFAULT NULL COMMENT '权限',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of t_authority
-- ----------------------------
INSERT INTO `t_authority` VALUES ('1', 'ROLE_admin');
INSERT INTO `t_authority` VALUES ('2', 'ROLE_common');
-- ----------------------------
-- Table structure for `t_statistic`
-- ----------------------------
DROP TABLE IF EXISTS `t_statistic`;
CREATE TABLE `t_statistic` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`article_id` int(11) NOT NULL COMMENT '关联的文章id',
`hits` int(11) NOT NULL DEFAULT '0' COMMENT '文章点击总量',
`comments_num` int(11) NOT NULL DEFAULT '0' COMMENT '文章评论总量',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of t_statistic
-- ----------------------------
INSERT INTO `t_statistic` VALUES ('1', '1', '91', '5');
INSERT INTO `t_statistic` VALUES ('2', '2', '3', '0');
INSERT INTO `t_statistic` VALUES ('3', '3', '4', '0');
INSERT INTO `t_statistic` VALUES ('4', '4', '4', '0');
INSERT INTO `t_statistic` VALUES ('5', '5', '4', '0');
INSERT INTO `t_statistic` VALUES ('6', '6', '15', '0');
INSERT INTO `t_statistic` VALUES ('7', '7', '6', '0');
INSERT INTO `t_statistic` VALUES ('8', '8', '23', '1');
INSERT INTO `t_statistic` VALUES ('9', '9', '18', '0');
INSERT INTO `t_statistic` VALUES ('10', '10', '18', '1');
INSERT INTO `t_statistic` VALUES ('11', '11', '10', '1');
INSERT INTO `t_statistic` VALUES ('12', '12', '39', '1');
-- ----------------------------
-- Table structure for `t_user`
-- ----------------------------
DROP TABLE IF EXISTS `t_user`;
CREATE TABLE `t_user` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`username` varchar(200) DEFAULT NULL,
`password` varchar(200) DEFAULT NULL,
`email` varchar(200) DEFAULT NULL,
`created` date DEFAULT NULL,
`valid` tinyint(1) NOT NULL DEFAULT '1',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of t_user
-- ----------------------------
INSERT INTO `t_user` VALUES ('1', 'admin', '$2a$10$5ooQI8dir8jv0/gCa1Six.GpzAdIPf6pMqdminZ/3ijYzivCyPlfK', '2127269781@qq.com', '2018-10-01', '1');
INSERT INTO `t_user` VALUES ('2', '李四', '$2a$10$5ooQI8dir8jv0/gCa1Six.GpzAdIPf6pMqdminZ/3ijYzivCyPlfK', '1768653040@qq.com', '2018-11-13', '1');
INSERT INTO `t_user` VALUES ('3', '东方不败', '$2a$10$5ooQI8dir8jv0/gCa1Six.GpzAdIPf6pMqdminZ/3ijYzivCyPlfK', '13718391550@163.com', '2018-12-18', '1');
INSERT INTO `t_user` VALUES ('4', 'tom', '$2a$10$5ooQI8dir8jv0/gCa1Six.GpzAdIPf6pMqdminZ/3ijYzivCyPlfK', 'asexeees@sohu.com', '2018-12-03', '1');
-- ----------------------------
-- Table structure for `t_user_authority`
-- ----------------------------
DROP TABLE IF EXISTS `t_user_authority`;
CREATE TABLE `t_user_authority` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`user_id` int(11) NOT NULL COMMENT '关联的用户id',
`authority_id` int(11) NOT NULL COMMENT '关联的权限id',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of t_user_authority
-- ----------------------------
INSERT INTO `t_user_authority` VALUES ('1', '1', '1');
INSERT INTO `t_user_authority` VALUES ('2', '2', '2');
INSERT INTO `t_user_authority` VALUES ('3', '3', '2');
INSERT INTO `t_user_authority` VALUES ('4', '4', '2');
# 选择使用数据库
USE blog_system;
# 创建表t_customer并插入相关数据
DROP TABLE IF EXISTS `t_customer`;
CREATE TABLE `t_customer` (
`id` int(20) NOT NULL AUTO_INCREMENT,
`username` varchar(200) DEFAULT NULL,
`password` varchar(200) DEFAULT NULL,
`valid` tinyint(1) NOT NULL DEFAULT '1',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8;
INSERT INTO `t_customer` VALUES ('1', 'admin', '$2a$10$5ooQI8dir8jv0/gCa1Six.GpzAdIPf6pMqdminZ/3ijYzivCyPlfK', '1');
INSERT INTO `t_customer` VALUES ('2', '李四', '$2a$10$5ooQI8dir8jv0/gCa1Six.GpzAdIPf6pMqdminZ/3ijYzivCyPlfK', '1');
# 创建表t_authority并插入相关数据
DROP TABLE IF EXISTS `t_authority`;
CREATE TABLE `t_authority` (
`id` int(20) NOT NULL AUTO_INCREMENT,
`authority` varchar(20) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8;
INSERT INTO `t_authority` VALUES ('1', 'ROLE_admin');
INSERT INTO `t_authority` VALUES ('2', 'ROLE_common');
# 创建表t_customer_authority并插入相关数据
DROP TABLE IF EXISTS `t_customer_authority`;
CREATE TABLE `t_customer_authority` (
`id` int(20) NOT NULL AUTO_INCREMENT,
`customer_id` int(20) DEFAULT NULL,
`authority_id` int(20) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=5 DEFAULT CHARSET=utf8;
INSERT INTO `t_customer_authority` VALUES ('1', '1', '1');
INSERT INTO `t_customer_authority` VALUES ('2', '2', '2');
# 记住我功能中创建持久化Token存储的数据表
create table persistent_logins (username varchar(64) not null,
series varchar(64) primary key,
token varchar(64) not null,
last_used timestamp not null);
/*
Navicat MySQL Data Transfer
Source Server : localhost
Source Server Version : 80031
Source Host : 127.0.0.1:3306
Source Database : blog_system
Target Server Type : MYSQL
Target Server Version : 80031
File Encoding : 65001
Date: 2023-10-30 15:59:43
*/
SET FOREIGN_KEY_CHECKS=0;
-- ----------------------------
-- Table structure for t_schedule_email
-- ----------------------------
DROP TABLE IF EXISTS `t_schedule_email`;
CREATE TABLE `t_schedule_email` (
`id` int NOT NULL AUTO_INCREMENT,
`toaddress` varchar(255) DEFAULT NULL COMMENT '收件人邮箱地址',
`schedule` bigint DEFAULT NULL COMMENT '定时参数(5位数字,第1位是星期几,第2-3位是几时,第4-5位是几分',
`subject` varchar(255) DEFAULT NULL COMMENT '邮件主题',
`content` text COMMENT '邮件内容',
`status` char(1) DEFAULT NULL COMMENT '0未发送 1发送成功 2发送失败',
`error` text COMMENT '若邮件发送失败,存储失败具体信息',
`create_time` datetime DEFAULT NULL COMMENT '记录创建时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8mb3;
三.系统环境搭建
1.准备数据库资源
创建数据库并导入测试数据
创建一个名称为blog_system的数据库,并选择该数据库,然后将本书资源中所提供的blog_system.sql文件导入到blog_system数据库中。
2.准备项目环境
前端资源引入
后端基础代码导入
四.前台、后台管理模块
1.文章的分页展示、文章详情查看、评论管理
文章的分页展示
创建Service层接口实现类文件(ArticleServiceImpl),selectArticleWithPage(Integer page, Integer count)方法用于分页查询出对应的文章信息,getHeatArticles( )方法用于统计热度前10的文章信息。(具体代码如下)
@Override
public PageInfo<Article> selectArticleWithPage(Integer page, Integer count) {
PageHelper.startPage(page, count);
List<Article> articleList = articleMapper.selectArticleWithPage();
for (int i = 0; i < articleList.size(); i++) {
Article article = articleList.get(i);
Statistic statistic =statisticMapper.selectStatisticWithArticleId(article.getId());
article.setHits(statistic.getHits());
article.setCommentsNum(statistic.getCommentsNum());
}
PageInfo<Article> pageInfo=new PageInfo<>(articleList);
return pageInfo;}
@Override
public List<Article> getHeatArticles( ) {
List<Statistic> list = statisticMapper.getStatistic();
List<Article> articlelist=new ArrayList<>();
for (int i = 0; i < list.size(); i++) {
Article article = articleMapper.selectArticleWithId(list.get(i).getArticleId());
article.setHits(list.get(i).getHits());
article.setCommentsNum(list.get(i).getCommentsNum());
articlelist.add(article);
if(i>=9){
break;
}}
return articlelist;}
创建博客首页处理类IndexController,并编写文章分页查询和热度统计的方法,同时进行了路径映射。另外,对查询出的文章信息articles和热度文章articleList都向Request域中进行了存储,并跳转到项目类目录下client目录中的index.html文件,这样在该前端页面上就可以直接取用。(具体代码如下)
private static final Logger logger = LoggerFactory.getLogger(IndexController.class);
@Autowired
private IArticleService articleServiceImpl;
@GetMapping(value = "/")
private String index(HttpServletRequest request) {
return this.index(request, 1, 5);
}
@GetMapping(value = "/page/{p}")
public String index(HttpServletRequest request, @PathVariable("p") int page,
@RequestParam(value = "count", defaultValue = "5") int count) {
PageInfo<Article> articles =
articleServiceImpl.selectArticleWithPage(page, count);
List<Article> articleList = articleServiceImpl.getHeatArticles();
request.setAttribute("articles", articles);
request.setAttribute("articleList", articleList);
logger.info("分页获取文章信息: 页码 "+page+",条数 "+count);
return "client/index";
}
效果展示
在登录页面输入Security提供的默认用户名user,并输入项目启动时控制台打印的随机密码登录,会自动跳转到博客首页面。
文章详情查看
创建Service层接口实现类文件,实现新增的查询文章详情方法,并在文章详情查询的业务实现中嵌入Redis缓存管理,先使用@Autowired注解注入定制的RedisTemplate类(在项目com.itheima.config包下定制的配置类),然后在文章查询过程中先从Redis缓存中进行查询,如果为空再进行数据库查询,并将结果进行缓存处理。其中,此处缓存管理的文章详情数据的key为“article_” + id的形式。(具体代码如下)
@Autowired
private RedisTemplate redisTemplate;
public Article selectArticleWithId(Integer id){
Article article = null;
Object o = redisTemplate.opsForValue().get("article_" + id);
if(o!=null){article=(Article)o;
}else{article = articleMapper.selectArticleWithId(id);
if(article!=null){
redisTemplate.opsForValue().set("article_" + id,article);}}
return article;}
针对新编写的ICommentService和ISiteService接口文件编写各自的实现类,分别实现了ICommentService和ISiteService接口中的方法,调用对应Mapper接口文件中的方法进行具体的业务实现。(具体代码如下)
@Service
@Transactional
public class CommentServiceImpl implements ICommentService {
@Autowired
private CommentMapper commentMapper;
// 根据文章id分页查询评论
@Override
public PageInfo<Comment> getComments(Integer aid, int page, int count) {
PageHelper.startPage(page,count);
List<Comment> commentList = commentMapper.selectCommentWithPage(aid);
PageInfo<Comment> commentInfo = new PageInfo<>(commentList);
return commentInfo;
}
}
===============================================
@Service
@Transactional
public class SiteServiceImpl implements ISiteService {
@Autowired
private CommentMapper commentMapper;
@Autowired
private ArticleMapper articleMapper;
@Autowired
private StatisticMapper statisticMapper;
@Override
public void updateStatistics(Article article) {
Statistic statistic =
statisticMapper.selectStatisticWithArticleId(article.getId());
statistic.setHits(statistic.getHits()+1);
statisticMapper.updateArticleHitsWithId(statistic);
}
@Override
public List<Comment> recentComments(int limit) {
PageHelper.startPage(1, limit>10 || limit<1 ? 10:limit);
List<Comment> byPage = commentMapper.selectNewComment();
return byPage;
}
@Override
public List<Article> recentArticles(int limit) {
PageHelper.startPage(1, limit>10 || limit<1 ? 10:limit);
List<Article> list = articleMapper.selectArticleWithPage();
// 封装文章统计数据
for (int i = 0; i < list.size(); i++) {
Article article = list.get(i);
Statistic statistic =
statisticMapper.selectStatisticWithArticleId(article.getId());
article.setHits(statistic.getHits());
article.setCommentsNum(statistic.getCommentsNum());
}
return list;
}
@Override
public StaticticsBo getStatistics() {
StaticticsBo staticticsBo = new StaticticsBo();
Integer articles = articleMapper.countArticle();
Integer comments = commentMapper.countComment();
staticticsBo.setArticles(articles);
staticticsBo.setComments(comments);
return staticticsBo;
}
}
=========================================
效果展示
启动项目,登录并进入项目首页,在项目首页随机选择一篇文章单击文章名查看文章详情,或者选择阅读排行榜中的一篇文章进行详情查看。
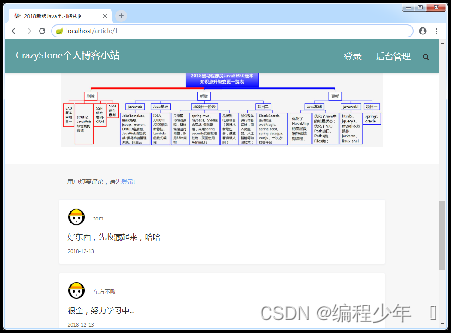
文章评论管理
创建一个用户评论管理的控制类CommentController,并编写相应的请求控制方法,编写了一个评论发布方法,该方法的请求控制路径为“/comments/publish”。在评论发布的方法内部,对用户评论信息进行了获取和封装,然后进行插入操作,最后根据执行结果向原页面返回状态信息。(具体代码如下)
@PostMapping(value = "/publish")
@ResponseBody
public ArticleResponseData publishComment(HttpServletRequest request,
@RequestParam Integer aid, @RequestParam String text) {
text = MyUtils.cleanXSS(text);text = EmojiParser.parseToAliases(text);
User user= (User) SecurityContextHolder.getContext().getAuthentication().getPrincipal();
Comment comments = new Comment();
comments.setArticleId(aid);comments.setIp(request.getRemoteAddr());
comments.setCreated(new Date());comments.setAuthor(user.getUsername());
comments.setContent(text);
try {
commentServcieImpl.pushComment(comments);
logger.info("发布评论成功,对应文章id: "+aid);
return ArticleResponseData.ok();
} catch (Exception e) {
logger.error("发布评论失败,对应文章id: "+aid +";错误描述: "+e.getMessage());
return ArticleResponseData.fail();}}
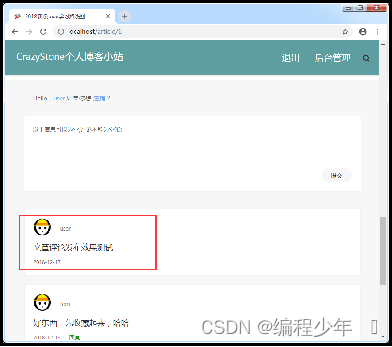
效果展示
启动项目进行测试,登录并进入到某个文章详情页面,在文章底部的评论框中发布评论进行效果测试
2.数据展示
创建一个用于后台管理控制的控制类AdminController(具体代码如下
private static final Logger logger=LoggerFactory.getLogger(AdminController.class);
@Autowired
private ISiteService siteServiceImpl;
@GetMapping(value = {"", "/index"})
public String index(HttpServletRequest request) {
List<Article> articles = siteServiceImpl.recentArticles(5);
List<Comment> comments = siteServiceImpl.recentComments(5);
StaticticsBo staticticsBo = siteServiceImpl.getStatistics();
request.setAttribute("comments", comments);
request.setAttribute("articles", articles);
request.setAttribute("statistics", staticticsBo);
return "back/index";}
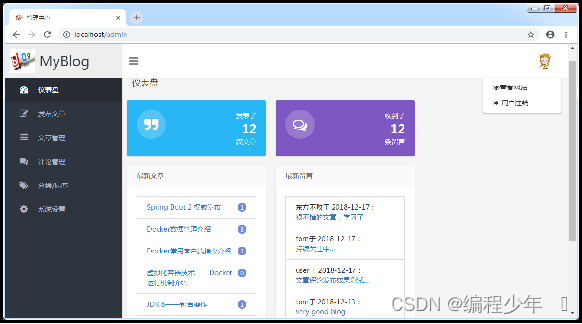
效果展示
启动项目后登录,在项目前端首页单击左上角的“后台管理”链接进入博客系统后台首页
3.文章发布、文章修改、文章删除
文章发布
@PostMapping(value = "/article/publish")
@ResponseBody
public ArticleResponseData publishArticle(Article article) {
if (StringUtils.isBlank(article.getCategories())) {
article.setCategories("默认分类");}
try {articleServiceImpl.publish(article);
logger.info("文章发布成功");
return ArticleResponseData.ok();
} catch (Exception e) {
logger.error("文章发布失败,错误信息: "+e.getMessage());
return ArticleResponseData.fail();}}
@GetMapping(value = "/article")
public String index(@RequestParam(value = "page", defaultValue = "1") int page,
@RequestParam(value = "count", defaultValue = "10") int count,
HttpServletRequest request) {
PageInfo<Article> pageInfo =
articleServiceImpl.selectArticleWithPage(page, count);
request.setAttribute("articles", pageInfo);
return "back/article_list";
}
效果展示
启动项目,先登录,在项目前端首页单击左上角的“后台管理”链接直接进入博客系统后台首页;然后单击页面左侧的“发布文章”面板链接进入到文章编辑页面,并进行新文章的编辑。
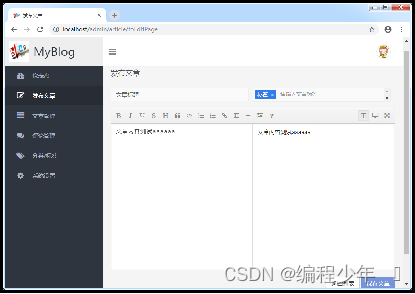
在文章编辑页面对应的编辑框中,分别编辑了文章标题、标签和文章内容。然后,单击下方的“保存文章”按钮提交文章发布请求,处理成功后会在页面出现一个“文章保存成功”的提示框。
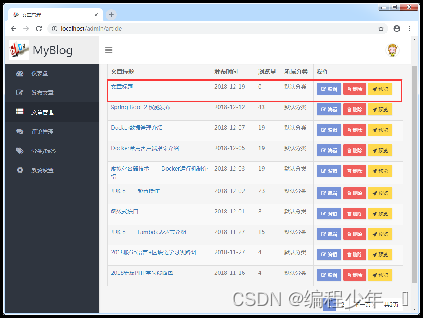
文章修改
// 文章修改处理
@PostMapping(value = "/article/modify")
@ResponseBody
public ArticleResponseData modifyArticle(Article article) {
try {
articleServiceImpl.updateArticleWithId(article);
logger.info("文章更新成功");
return ArticleResponseData.ok();
} catch (Exception e) {
logger.error("文章更新失败,错误信息: "+e.getMessage());
return ArticleResponseData.fail();
}}
// 向文章修改页面跳转
@GetMapping(value = "/article/{id}")
public String editArticle(@PathVariable("id") String id, HttpServletRequest request) {
Article article = articleServiceImpl.selectArticleWithId(Integer.parseInt(id));
request.setAttribute("contents", article);
request.setAttribute("categories", article.getCategories());
return "back/article_edit";
}
效果展示
项目启动成功后,先在浏览器上访问http://localhost/admin/article页面,被拦截并登录成功后直接进入后台文章列表页面;选择页面最上方新发布的任意一篇文章后方的“编辑”链接进入文章编辑页面,对该文章进行编辑修改。
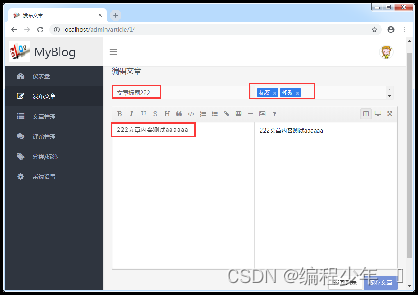
对之前标题为“文章标题”的文章进行了修改。单击下方的“保存文章”按钮提交文章修改请求,处理成功后会在页面出现一个“文章保存成功”的提示框,单击确定后具体效果如图。
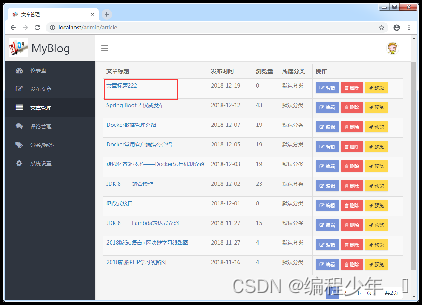
文章删除
打开系统后台管理控制类AdminController,在类中增加文章删除的处理方法
@PostMapping(value = "/article/delete")
@ResponseBody
public ArticleResponseData delete(@RequestParam int id) {
try {
articleServiceImpl.deleteArticleWithId(id);
logger.info("文章删除成功");
return ArticleResponseData.ok();
} catch (Exception e) {
logger.error("文章删除失败,错误信息: "+e.getMessage());
return ArticleResponseData.fail();
}}
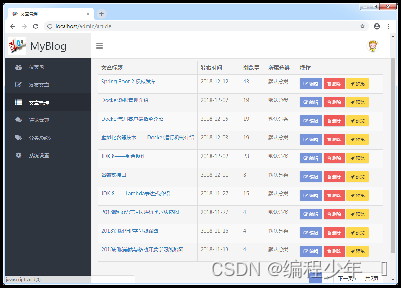
效果展示
启动项目进行效果测试,在浏览器上访问http://localhost/admin/article,被拦截并登录成功后直接进入后台文章列表页面;选择页面最上方修改后的名为“文章标题222”的文章后方“删除”链接对该文章进行删除操作,在弹出的删除提示框中确认后效果如图。
五.用户登录控制及定时邮件发送
用户登录控制
继续在SecurityConfig配置类中编写自定义用户授权管理的实现,自定义用户授权管理方法中主要配置了自定义的用户访问控制、用户登录控制、用户登录后的Cookie设置、用户退出控制和登录用户无权限访问控制。(具体代码如下)
@Value("${COOKIE.VALIDITY}")
private Integer COOKIE_VALIDITY;
// 重写configure(HttpSecurity http)方法,进行用户授权管理
@Override
protected void configure(HttpSecurity http) throws Exception {
// 1、自定义用户访问控制
http.authorizeRequests()
.antMatchers("/","/page/**","/article/**","/login").permitAll()
.antMatchers("/back/**","/assets/**","/user/**","/article_img/**").permitAll()
.antMatchers("/admin/**").hasRole("admin")
.anyRequest().authenticated();
// 2、自定义用户登录控制
http.formLogin()
.loginPage("/login")
.usernameParameter("username").passwordParameter("password")
.successHandler(new AuthenticationSuccessHandler() {
@Override
public void onAuthenticationSuccess(HttpServletRequest httpServletRequest,
HttpServletResponse httpServletResponse, Authentication authentication)
throws IOException, ServletException {
String url = httpServletRequest.getParameter("url");
// 获取被拦截登录的原始访问路径
RequestCache requestCache = new HttpSessionRequestCache();
SavedRequest savedRequest =
requestCache.getRequest(httpServletRequest,httpServletResponse);
if(savedRequest !=null){
// 如果存在原始拦截路径,登录成功后重定向到原始访问路径
httpServletResponse.sendRedirect(savedRequest.getRedirectUrl());
} else if(url != null && !url.equals("")){
// 跳转到之前所在页面
URL fullURL = new URL(url);
httpServletResponse.sendRedirect(fullURL.getPath());
}else {
// 直接登录的用户,根据用户角色分别重定向到后台首页和前台首页
Collection<? extends GrantedAuthority> authorities =
authentication.getAuthorities();
boolean isAdmin = authorities.contains(
new SimpleGrantedAuthority("ROLE_admin"));
if(isAdmin){
httpServletResponse.sendRedirect("/admin");
}else {
httpServletResponse.sendRedirect("/");
}
}
}
})
// 用户登录失败处理
.failureHandler(new AuthenticationFailureHandler() {
@Override
public void onAuthenticationFailure(HttpServletRequest httpServletRequest,
HttpServletResponse httpServletResponse, AuthenticationException e)
throws IOException, ServletException {
// 登录失败后,取出原始页面url并追加在重定向路径上
String url = httpServletRequest.getParameter("url");
httpServletResponse.sendRedirect("/login?error&url="+url);
}
});
// 3、设置用户登录后cookie有效期,默认值
http.rememberMe().alwaysRemember(true).tokenValiditySeconds(COOKIE_VALIDITY);
// 4、自定义用户退出控制
http.logout().logoutUrl("/logout").logoutSuccessUrl("/");
// 5、针对访问无权限页面出现的403页面进行定制处理
http.exceptionHandling().accessDeniedHandler(new AccessDeniedHandler() {
@Override
public void handle(HttpServletRequest httpServletRequest,
HttpServletResponse httpServletResponse, AccessDeniedException e)
throws IOException, ServletException {
// 如果是权限访问异常,则进行拦截到指定错误页面
RequestDispatcher dispatcher =
httpServletRequest.getRequestDispatcher("/errorPage/comm/error_403");
dispatcher.forward(httpServletRequest, httpServletResponse);
}
});
}
注: 自定义用户授权管理方法中主要配置了自定义的用户访问控制、用户登录控制、用户登录后的Cookie设置、用户退出控制和登录用户无权限访问控制。
效果展示
启动项目进行测试,访问项目前端首页,无需登录,如图。
定时邮件发送
创建一个定时任务管理类ScheduleTask,并编写了定时调度方法sendEmail(),并通过“@Scheduled(cron = ”0 0 12 1 * ?“)”注解指定了在每月1日中午12点调用邮件发送任务发送邮件。(具体代码如下)
@Scheduled(cron = "0 0 12 1 * ?")
public void sendEmail(){
// 定制邮件内容
long totalvisit = statisticMapper.getTotalVisit();
long totalComment = statisticMapper.getTotalComment();
StringBuffer content = new StringBuffer();
content.append("博客系统总访问量为:"+totalvisit+"人次").append("\n");
content.append("博客系统总评论量为:"+totalComment+"人次").append("\n");
mailUtils.sendSimpleEmail(mailto,"个人博客系统流量统计情况",content.toString());
}
效果展示
在项目启动成功后,持续关注配置的测试邮箱信息,效果如图
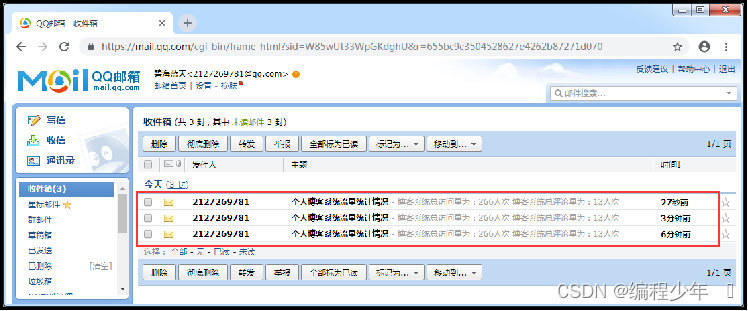


















 1313
1313

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











