







 本文详细讲解了Java中的`==`和`equals()`方法的区别,hashCode的作用,以及成员变量与局部变量的差异。还介绍了try-catch-finally结构的用途和finally块的执行规则,包括哈希冲突和重写equals时hashCode的重要性。适合准备Java面试的朋友学习。
本文详细讲解了Java中的`==`和`equals()`方法的区别,hashCode的作用,以及成员变量与局部变量的差异。还介绍了try-catch-finally结构的用途和finally块的执行规则,包括哈希冲突和重写equals时hashCode的重要性。适合准备Java面试的朋友学习。
注意:文章若有错误的地方,欢迎评论区里面指正 🍭
-
系列文章目录
文章目录
五、说一下try-catch-finally各个部分的作用?
前言
哈喽,小伙伴们,昨天我们回顾了面向对象的定义和三大特性及其从中引申出来的重写、重载、final等一些知识点,我们今天继续来分享几道Java基础的面试题。🌈
提示:以下是本篇文章正文内容,下面案例可供参考
一、说一说==和equals的区别
1. == 运算符:
- 基本数据类型:对基本数据类型(如:int、boolean、char等),
==用于比较两个变量的值是否相等。- 引用数据类型:对于对象引用(即引用数据类型),
==用于比较两个引用是否指向内存中的同一个对象。换句话说,它检查的是两个引用是否指向同一个对象的内存地址。2. equals() 方法:
equals()是Object类的一个方法,所有的 Java 类都继承了这个方法。默认情况下,它的行为与==对于引用类型相似,即比较两个引用是否指向同一个对象。- 但许多类(如
String,Integer等)都重写了equals()方法。例如,对于String类,equals()方法用于比较两个字符串的内容是否相同,而不是比较它们的引用是否相同。
/*
这个是equals()底层源码,我的是jdk11,可能跟jdk1.8不太一样,我觉得应该大差不差
*/
public boolean equals(Object anObject) {
if (this == anObject) {
return true;
}
if (anObject instanceof String) {
String aString = (String)anObject;
if (coder() == aString.coder()) {
return isLatin1() ? StringLatin1.equals(value, aString.value)
: StringUTF16.equals(value, aString.value);
}
}
return false;
}
//StringLatin1的equals方法
public static boolean equals(byte[] value, byte[] other) {
if (value.length == other.length) {
for (int i = 0; i < value.length; i++) {
if (value[i] != other[i]) {
return false;
}
}
return true;
}
return false;
}
//StringUTF16的equals方法
public static boolean equals(byte[] value, byte[] other) {
if (value.length == other.length) {
int len = value.length >> 1;
for (int i = 0; i < len; i++) {
if (getChar(value, i) != getChar(other, i)) {
return false;
}
}
return true;
}
return false;
}
从上面源码我们可以看出,它会根据编码方法是不同,会通过两种方式进行比较,但是,只是实现方式比一样罢了,本质上都是将byte数组里面的字符拿出来一个一个比较,其实还是用的 == ,StringLatin1的equals方法更通用些,StringLatin1的只针对特定编码。
我们可以给面试官这样说,回答完上面二者的区别后,可以加上,我看过equals底层源码,它的底层原理是将byte数组里面的字符拿出来一个一个比较,其实还是用的 == (会给面试官一个不错的印象)😄
给大举一些例子方便大家更好的区分:
String str1 = new String("hello");
String str2 = new String("hello");
String str3 = str1;
System.out.println(str1 == str2); // 输出 false,因为 str1 和 str2 指向不同的对象
System.out.println(str1.equals(str2)); // 输出 true,因为 str1 和 str2 的内容相同
System.out.println(str1 == str3); // 输出 true,因为 str1 和 str3 指向同一个对象
System.out.println(str1.equals(str3)); // 输出 true,因为 str1 和 str3 的内容也相同
二、说说hashCode()的作用?
我们先看一下源码里面的注释怎么解释的,有小伙伴不知道native是干嘛,我给大家简单解释下,native是一个关键字,用它修饰的方法被称为本地方法,其实为了让Java程序能够调用非Java代码(通常是C或C++),尤其是那些用其他语言编写的库
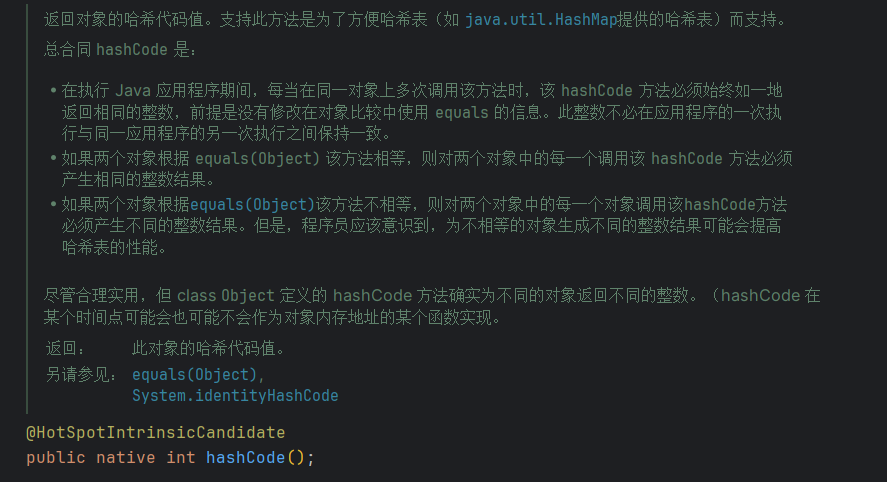
简单来说就是这个本地方法会将对象的内存地址转化为整数之后返回,也就是获取对象的哈希码值,它的作用就是确定该对象在哈希表中的索引位置
🧑💼面试官追问:为什么重写 equals() 时必须重写 hashCode() 方法?
默认的 hashcode() 方法是根据对象的内存地址经哈希算法得来的。如果没有重写 hashCode(),则该 class 的两个对象无论如何都不会相等(即使这两个对象指向相同的数据)
而我们希望的是:
- 如果两个对象相同(用 equals 比较返回true),那么它们的 hashCode 值一定要相同
- 如果两个对象的 hashCode 相同,它们并不一定相同(用 equals 比较返回 false)
简单来说就是:如果 equals 方法判断两个对象是相等的,那这两个对象的 hashCode 值也要相等。
🧑💼面试官继续追问:有没有可能两个不相等的对象有有相同的 hashcode?
可能的,面试官想听到的就是让你解释 Hash冲突 ,所谓Hash冲突就是
hashCode()所使用的哈希算法也许刚好会让多个对象传回相同的哈希值。下面是gpt的回答:
Hash冲突,也称为哈希冲突或碰撞,是在使用哈希函数时发生的一种现象。哈希函数是一种将任意长度的数据(如字符串或数字)映射为固定长度的哈希值(通常是较短的字符串或数字)的算法。哈希函数的主要用途是快速查找和比较数据,例如在哈希表或数据库中。
然而,由于哈希函数的输出空间(即可能的哈希值的范围)通常远小于输入空间(即所有可能输入数据的范围),因此不同的输入数据可能会产生相同的哈希值。这种情况就称为哈希冲突或碰撞。
🧑💼面试官又继续追问:如何解决Hash冲突?
下面还是gpt的回答:
哈希冲突可能会导致一系列问题,特别是在需要唯一标识数据的应用中。例如,在哈希表中,如果两个键(key)的哈希值相同,那么就需要一种机制来处理这种冲突,以便能够正确地存储和检索数据。常见的解决哈希冲突的方法包括链地址法(使用链表存储具有相同哈希值的元素)、开放地址法(当冲突发生时,通过某种规则查找下一个可用位置)等。
为了减少哈希冲突的可能性,设计哈希函数时需要考虑到输入数据的特性和分布,并尽量使哈希函数的结果分布均匀。此外,有些哈希函数还使用“盐”(salt)或其他技术来增加输入数据的随机性,从而降低哈希冲突的概率。
可以简单将上面标注的方法简单回答出来就行了。
三、举几个Object常用的方法
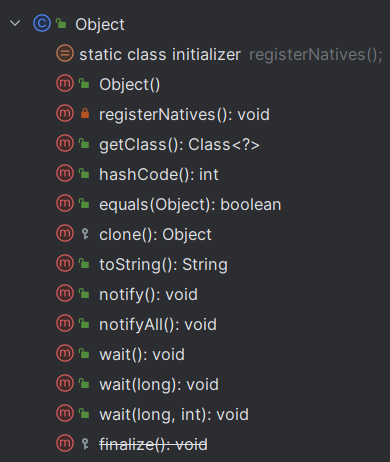
我的是jdk11,我就以jdk11为例,hashCode()、equals()、toString这几个就不再过多叙述了,getClass()用于获取对象的运行时类的
Class对象,反射那一块用的很多,后面几个像notify()、notifyAll()、wait(),是反射那一块的,当时候我会详细说一下,面试也经常会问到,最后一个finalize()方法是实例被垃圾回收器回收的时候触发的操作,这个方法在jdk11被废弃了。说什么会出现性能问题、死锁和挂起等问题,在这里就不过多解释了,好奇的小伙伴可以自己去看看方法上面的解释。
四、成员变量与局部变量的区别有哪些?
定义位置:
- 成员变量:定义在类的方法体之外,但在类的范围内。无论是静态成员变量还是非静态成员变量,它们都是类的属性,与类本身关联。
- 局部变量:定义在方法体或代码块内部,只在定义它的方法或代码块内有效。
生命周期:
- 成员变量:只要对象存在,成员变量就会一直存在。静态成员变量的生命周期是整个程序的运行时间,非静态成员变量的生命周期与对象的存在时间一致。
- 局部变量:当方法或代码块被调用时,局部变量被创建,当方法或代码块执行完毕后,局部变量被销毁。
默认值:
- 成员变量:如果成员变量没有显式地初始化,系统会根据其类型赋予默认值(例如,数值型默认为0,引用类型默认为null)。
- 局部变量:局部变量必须在使用前显式初始化,否则编译器会报错。
访问修饰符:
- 成员变量:可以使用访问修饰符(如public、private、protected)来控制其在其他类或包中的可见性。
- 局部变量:局部变量不能使用访问修饰符,它们的可见性仅限于定义它们的方法或代码块。
存储位置:
- 成员变量:成员变量存储在堆内存中,因为它们是对象的属性。
- 局部变量:局部变量存储在栈内存中,因为它们与特定的方法调用或代码块执行关联。
内存分配:
- 成员变量:随着对象的创建,成员变量会被分配内存。
- 局部变量:当方法或代码块被调用时,局部变量会在栈上为其分配内存。
五、说一下try-catch-finally各个部分的作用?
try部分:
try块用于包含可能抛出异常的代码。这些异常可能是由Java运行时环境抛出的,也可能是由代码中的错误导致的。- 当
try块中的代码执行时,如果发生了异常,那么会立即跳出try块,并查找与之匹配的catch块。catch部分:
catch块用于捕获并处理异常。一个try块后面可以跟随一个或多个catch块。每个catch块都定义了一个它可以处理的异常类型。- 当
try块中的代码抛出异常时,JVM会查找与该异常类型匹配的catch块。一旦找到匹配的catch块,就执行该块中的代码来处理异常。- 如果没有找到匹配的
catch块,那么异常会被继续抛出,直到被更高层的catch块捕获,或者如果没有任何catch块能够处理该异常,那么程序会终止并打印出异常信息。finally部分:
finally块是可选的,但它提供了一种无论是否发生异常都会执行的机制。- 无论
try块中的代码是否抛出异常,finally块中的代码都会执行。这确保了资源(如文件句柄、网络连接等)在程序结束前得到正确的清理。- 需要注意的是,如果在
try或catch块中使用了return语句,那么finally块仍然会执行,但在finally块执行完毕后,程序会返回try或catch块中的return语句指定的值。
🧑💼面试官追问:finally部分的代码一定会被执行吗?
不一定,可以说一下下面三种特殊情况:
- 在
try或finally块中用了System.exit(int)退出程序。但是,如果System.exit(int)在异常语句之后,finally还是会被执行- 如果
try或catch块中的代码正在等待其他线程(例如通过Object.wait()),并且该线程在等待期间被中断,那么可能不会执行finally块。- JVM崩溃
总结
好了,今天的分享就到这里,明天见🥳



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











