







 本文详细介绍了Python中的推导式,包括列表、字典和集合推导式,以及嵌套和三元运算推导。接着探讨了可迭代对象的概念,列举了常见的可迭代类型。进一步讲解了迭代器的定义、判断、转换及其优势。然后,重点阐述了生成器的原理,包括生成器表达式、yield关键字的使用和生成器在处理大量数据时的高效性。最后,总结了可迭代对象、迭代器和生成器的关系及应用场景。
本文详细介绍了Python中的推导式,包括列表、字典和集合推导式,以及嵌套和三元运算推导。接着探讨了可迭代对象的概念,列举了常见的可迭代类型。进一步讲解了迭代器的定义、判断、转换及其优势。然后,重点阐述了生成器的原理,包括生成器表达式、yield关键字的使用和生成器在处理大量数据时的高效性。最后,总结了可迭代对象、迭代器和生成器的关系及应用场景。
目录
1、Python推导式
推导式comprehensions(又称解析式),是Python的一种独有特性。推导式是可以从一 个数据序列构建另一个新的数据序列的结构体。
1.1 列表(list)推导式
用[]生成list ,基本格式:
variable = [out_exp_res for out_exp in input_list if out_exp == 2]
• out_exp_res: 列表生成元素表达式,可以是有返回值的函数。
• for out_exp in input_list:迭代input_list将out_exp传入out_exp_res表达式中。
• if out_exp == 2: 根据条件过滤哪些
例1:打印30以内能被3整除的数,放到一个列表里
# 打印30以内能被3整除的数,放到一个列表里
result = [i for i in range(30) if i%3 == 0]
print(result)
# 30以内能被3整除的数的平方
print([i*i for i in range(30) if i*i%30 == 0])例2:
#列表里的浮点数保留两位小数,整数保持原样
lst = [2.43, 6.666, 9, 10, 5.20, 11.00]
print([round(i, 2) for i in lst])
print([round(i, 2) for i in lst if isinstance(i, float)])例题3:求(xy)其中x是O-5之间的偶数,y是O-5之间的奇数组成的元组列表·期望结果:[(0,1),(O,3),(O,5),(2,1),(2,3).…]
# #2.求(xy)其中x是O-5之间的偶数,y是O-5之间的奇数组成的元组列表·期望结果:[(0,1),(O,3),(O,5),(2,1),(2,3).…]
print([(x,y) for x in range(6) for y in range(6) if x%2 == 0 if y%2 != 0])
输出:
[(0, 1), (0, 3), (0, 5), (2, 1), (2, 3), (2, 5), (4, 1), (4, 3), (4, 5)]1.2 字典(dict)推导式
字典(dict)推导式,字典推导和列表推导的使用方法是类似的,只不中括号该改成大括号。
基本格式:variable = {out_key:out_value for out_key,out_value in input_list if out_exp == 2} • out_key: 返回字典结果的key
• out_value: 返回字典结果的value
• for out_key,out_value in input_list:迭代input_list将out_exp传入out_exp_res表达式中。
• if out_exp == 2:根据条件过滤哪些值可以
str1 = "ffdgrgtbddfasdgfhdkjfid"
result = { i:str1.count(i) for i in str1}
print(result)
print({ j:i for i,j in result.items()})
输出:
{'f': 5, 'd': 6, 'g': 3, 'r': 1, 't': 1, 'b': 1, 'a': 1, 's': 1, 'h': 1, 'k': 1, 'j': 1, 'i': 1}
{5: 'f', 6: 'd', 3: 'g', 1: 'i'}关于字典的items:result.items会将字典以元组的形式输出
dict = {'老大':'15岁',
'老二':'14岁',
'老三':'2岁',
'老四':'还没出生'
}
print(dict.items())
for key,values in dict.items():
print(key + '已经' + values + '了')
输出:
dict_items([('老大', '15岁'), ('老二', '14岁'), ('老三', '2岁'), ('老四', '还没出生')])
老大已经15岁了
老二已经14岁了
老三已经2岁了
老四已经还没出生了例题:合并大小写对应的value值,将k统一成小写期望结果:{'a':5, 'b':9, 'c':3}
# #4.合并大小写对应的value值,将k统一成小写期望结果:{'a':5, 'b':9, 'c':3}
q4 = {'B':3, 'a':1, 'b':6, 'c':3, 'A':4}
print({ i.lower():(q4.get(i.lower(),0) + q4.get(i.upper(), 0) ) for i in q4})
输出:
{'b': 6, 'a': 1, 'c': 3}1.3 集合(set)推导式
它们跟列表推导式也是类似的。 唯一的区别在于它使用大括号。
str1 = "ffadsfsafrbfgt"
print(set(str1))
print({i for i in str1})1.4 嵌套推导式
推导式里面嵌套了推导式。
print([i for lst in lst2 for i in lst if i%2])1.5 三元运算与列表推导式
•print([i//2 if i%2==0 else i for i in range(100) if i % 3 == 0 ])例题:如果输入1则成功,否则为失败
o = int(input("shuru"))
print("成功!" if o == 1 else "失败")
输出:
shuru:1
成功!
shuru:2
失败2、Python可迭代对象
for 后面接可迭代对象,for可用的有哪些?
• list, set, str, dict, tuple
• list(可迭代对象)
• sorted(可迭代对象)
2.1 容器(container)
容器是一种把多个元素组织在一起的数据结构,容器中的元素可以逐个地迭代获取,可以用in, not in关键字判断元素是否包含在容器中。
通常这类数据结构把所有的元素存储在内存中(也有一些特例,并不是所有的元素都放在内存,比如 迭代器和生成器对象)
2.2 什么是可迭代对象
实现了__iter__方法,并且该方法返回一个迭代器,这样子的对象就是迭代对象。
如何确认一个对象是不是可迭代对象:使用Iterable判断
from collections import Iterable
a='abc'
b=[1,2,3]
c=(4,5,6)
d={'name':'tom','age':18}
if isinstance(a,Iterable):
print('a 是可迭代对象')
if isinstance(b,Iterable):
print('b 是可迭代对象')
print(dir(b))
输出:
a 是可迭代对象
b 是可迭代对象
[…… '__init_subclass__', '__iter__', '__le__', ……]2.3 可迭代对象有哪些
1. 容器类型都是可迭代对象
list tuple dict set str
2. range
3. 处于打开状态的files,sockets
4、凡是可以返回一个迭代器(__iter__)的对象都可称之为可迭代对象
3、Python迭代器(iterator)
3.1 什么是迭代器
任何实现了__iter__()和__next__()都是迭代器。
__iter__() 返回自身
__next__() 不断的返回下一个值
for循环中先调用__iter__方法获取一个迭代器,然后执行__next__去获取下一个值,如果容器中没有更多元素了,则抛出StopIteration异常。迭代器是一个懒加载模式,用的时候才加载。
迭代器是有状态的,可以被next()调用,函数调用并不断返回下一 个值的对象称为迭代器(Iterator)。
3.2 判断迭代器
• Iterator判断,参考可迭代对象。
from collections import Iterator,Iterable
ran = range(3)
if isinstance(ran, Iterable):
print("ran shi 可迭代对象")
else:
print("ran no")
if isinstance(ran, Iterator):
print("ran 是迭代器")
else:
print("ran 不是迭代器")
输出:
ran shi 可迭代对象
ran 不是迭代器3.3 可迭代对象与迭代器的转换
列表对象转迭代器:
from collections import Iterator,Iterable
li = [1,2,3,'a']
li2 = iter(li)
print('li的类型:')
print(isinstance(li,Iterator))
print(isinstance(li,Iterable))
print('li2的类型:')
print(isinstance(li2,Iterator))
print(isinstance(li2,Iterator))
输出:
li的类型:
False
True
li2的类型:
True
True迭代器转列表对象:
from collections import Iterator,Iterable
a = iter('abc')
print(a,list(a))
li = [1,3,2]
li2 = iter(li)
print(li,li2)
输出:
<str_iterator object at 0x0000025ACF369FA0> ['a', 'b', 'c']
[1, 3, 2] <list_iterator object at 0x0000025ACF369CA0>3.4 生成无限序列
from itertools import count
counter = count(start=30)
print(counter,type(counter))
print(next(counter))
print(next(counter))
print(next(counter))
print(next(counter))
for i in range(12343234):
print(next(counter))3.5 从一个有限序列中生成无限序列
cycle,让迭代器可以无限循环迭代。
from itertools import cycle
import time
weeks = cycle(['1','2', '3', '4', '5', '6', '7'])
print(type(weeks),weeks)
for i in weeks:
print(i)
time.sleep(1)3.6 从无限的序列中生成有限序列
from itertools import count,islice
# 生成一个无限大的序列,从start开始
counter = count(start=1)
print(counter,type(counter))
s = islice(counter,1,10)
for i in s:
print(i)3.7 迭代器有什么好处
迭代器就像一个懒加载的工厂,等到有人需要的时候才给它生成值返回,没调用的时候就处于休眠状态等待下一次调用。
4、Python生成器(genatator)
4.1 什么是生成器-generator
生成器算得上是Python语言中最吸引人的特性之一,生成器其实是一种特殊的迭代器,不过这种迭代器更加优雅。它不需要手动编写__iter__()和__next__()方法,只需要一个yiled关键字。 • 生成器一定是迭代器(反之不成立) , 因此任何生成器也是以一种懒加载的模式生成值。
4.2 生成器表达式
生成器只有两种表达式:
1.生成器表达式 如:g1 = (x*x for i in range(3))
2.生成器函数 yield 关键字--》生成器函数
4.2.1 推导式
使用()生成generator, 将列表推导式的[]改成()即可得到生成器。列表推导式与生成器表达式,定义和使用非常类似,但是,在(大量数据处理时)性能上相差很大。
# a = [x for x in range(10**9) ]
a = (x for x in range(10**9) )
print(a)
print(dir(a))
print(next(a))
print(next(a))
print(next(a))
输出:
<generator object <genexpr> at 0x0000029B7F4FFDD0>
[…… '__init_subclass__', '__iter__', '_…… '__ne__', '__new__', '__next__', '__qualname__', '……]
0
1
24.2.2 yield关键字
包含yield表达式的函数是特殊的函数,叫做生成器函数(generator function),被调用时将返回一个迭代器(iterator),调用时可以使用next或send(msg)。
一个生成器中可以有多个yield ,一旦遇到yield,就会保存当前状态,然后返回yield后面的值。
当生成器遇到一个yield时,会暂停运行生成器,返回yield后面的值, 当再次调用生成器的时候,会从刚才暂停的地方继续运行,直到下一个yield,yield关键字:保留中间算法,下次继续执行。
def get_content():
print("start yield ...")
yield 3
print("second yield ... ")
yield 4
print("end ...")
a = get_content()
print(dir(a))
print(next(a))
print(next(a))
print(next(a))
print(next(a))
输出:
[…… '__iter__', '_…… '__next__', ……]
start yield ...
3
second yield ...
4
end ...例题:yield生成器来实现斐波那契数列
from itertools import islice
def fib():
prev,curr = 0,1
while True:
yield curr
prev,curr = curr,curr + prev
f = fib()
print(list(islice(f,0,10)))
输出:
[1, 1, 2, 3, 5, 8, 13, 21, 34, 55]生成器 fib() 的执行过程:
当执行f=fib()返回的是一个生成器对象,此时函数体中的代码并不会执行,而是首先返回一个iterable 对象!
只有显示或隐示地调用next的时候才会真正执行函数里面的代码,执行到语句 yield b 时,fab() 函数会返回yield后面(右边)的值,并记住当前执行的状态,下次调用next时,程序流会回到 yield b 的下一条语句继续执行。
看起来就好像一个函数在正常执行的过程中被 yield 中断了数次,每次中断都会通过yield返回当前的迭代值。 由此可以看出,生成器通过关键字 yield 不断的将迭代器返回到内存进行处理,而不会一次性的将对象全部放入内存,从而节省内存空间。
send数据:
除了可以使用 next() 方法来获取下一个生成的值,用户还可以使用send() 方法将一个新的或者是被修改的值返回给生成器。除此之外,还可以使用close() 方法来随时退出生成器。激活生成器,并且像生成器传递值。
def c():
count =1
while True:
val = yield count
print(f"val is {val}")
if val is not None:
count = val
else:
count += 1
count = c()
print(next(count))
print(next(count))
print(next(count))
print(next(count))
print(count.send(10))
输出:
1
val is None
2
val is None
3
val is None
4
val is 10
10def g1(x):
yield range(x)
def g2(x):
yield from range(x)
it1 = g1(5)
it2 = g2(5)
print( [ x for x in it1] )
print( [ x for x in it2] )
输出:
[range(0, 5)]
[0, 1, 2, 3, 4]4.3 使用生成器最好的场景
当你需要以迭代的方式去处理一个巨大的数据集合。比如:一个巨大的文件/一个复杂的数据库查询等。
如果直接对文件对象调用 read() 方法,会导致不可预测的内存占用。好的方法是利用固定长度的缓冲区来不断读取文件的部分内容。通过yield,我们不再需要编写读文件的迭代类,就可以轻松实现文件读取。
4.4 生成器的好处
生成器在Python中是一个非常强大的编程结构
- 可以用更少地中间变量写流式代码
- 相比其它容器对象它更能节省内存
- 可以用更少的代码来实现相似的功能
5、可迭代对象、迭代器、生成器总结
5.1 定义总结
- 可迭代对象:实现了__iter__, 返回了一个迭代器对象。
- 迭代器:Python中一个实现了_iter_方法和_next_方法的类对象,就是迭代器
- 生成器:延迟操作。也就是在需要的时候才产生结果,不是立即产生结果。
- 生成器是只能遍历一次的。
- 生成器是一类特殊的迭代器。
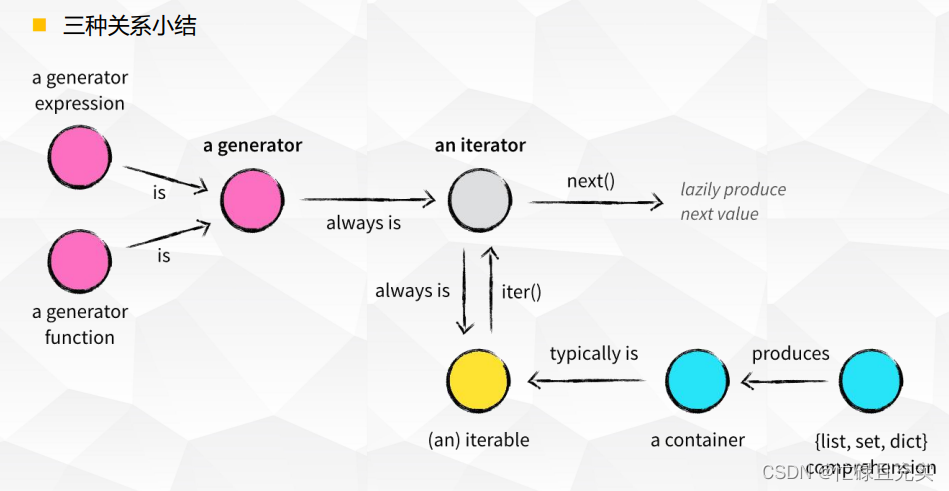
5.2 三种关系小结
- 对象是可迭代对象, 但却不一定是迭代器
- 如果对象属于迭代器, 那么这个对象一定是可迭代的
- 迭代器实现了一个__next__()方法,可以通过next函数每次取出迭代器中的每个元素
- 迭代器对象:__iter__()返回的是迭代器对象自身。
- 生成器是一种特殊的迭代器


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









