






什么是vector

可以看出 vector的一些成员函数其实string是一样的,但string
是特指字符数组,vector就相当于是string。
vector就像是一个可以动态增长的数组,其可以像数组一样采用下标对元素进行访问,和数组一样高效,但其所存储内存的大小却又是可以动改变的,那么vector 空间分配如何增加呢?有没有什么其他副作用?
vector空间分配如何增加
iterator _start;//表示vector起始位置
iterator _finish;//最终位置的下一个地址
//其中_finnish-_start表示的是数组的有效数据个数
iterator _end_of_storage;//_end_of_storage-_start表示的是数组中总容量大小
先看下我模拟实现vector实现的扩容
void reserve(size_t n)
{
//扩容
//仅支持扩容不支持缩
size_t sz = size();
if (n > capacity())
{
T* tmp = new T[n];
//if (_start)//防止是第一次扩容
//{
// memcpy(tmp, _start, sizeof(T) * size());
// delete []_start;
//}
if (_start)
{
for (size_t i = 0; i < sz; i++)
tmp[i] = _start[i];
}
//memcpy 是内存的二进制格式拷贝,将一段内存空间中的内容原封不动
//的拷贝到另外一段内存中
//如果拷贝的是自定义类型的元素,memcpy既高效又不会出错
//但如果拷贝的是自定义类型的元素,并且自定义类型元素中
//涉及到资源管理时,就会出错,因为memcpy的拷贝实际上是浅拷贝
_start = tmp;//注意:此时_start的值要改变
}
//_finish = _start + size();//错误写法
_finish = _start + sz;
_end_of_storage = _start + n;
}
可以看出,其本质是,分配一个新的空间,将原空间上的数据拷贝到新空间上,然后再改变一些数据大小,根据代码可以分析出这是一个代价相对较高的任务,因为一旦出现扩容系统便会动态开辟新的空间,所以为了避免这个,vector一开始就会分配一些额外的空间给vector,使得储存空间比实际需要的存储空间更大,同时不同的库采用不同的策略权衡空间的使用和重新分配。
vector一次增容没有规定,vs下实验之后是1.5倍,Linux下测试后发现是两倍增容,增容太少会多次增容,效率比非常低,增容太多会造成太大的空间浪费,与内存对齐无关
同时,string的增容可能会考虑内存对齐,因为string单个对象是一字节,而系统给内存分配时一般是偶数,例如我们需要的是5字节,系统给我们的可能是8字节,如果我们需要的是6字节,系统分配的空间同样是8字节,但是vector的元素对象大部分都不是一字节,因为vector相当于string 没必要,所以vector的对象大小大部分都是四字节或者八字节,都是偶数字节,所以就不涉及到内存对齐了。
区分两个构造函数
iterator insert(iterator pos, const T& x);
//// 若使用iterator做迭代器,会导致初始化的迭代器区间[first,last)只能是vector的迭代器
// 重新声明迭代器,迭代器区间[first,last)可以是任意容器的迭代器
vector(size_t n, const T& val = T());
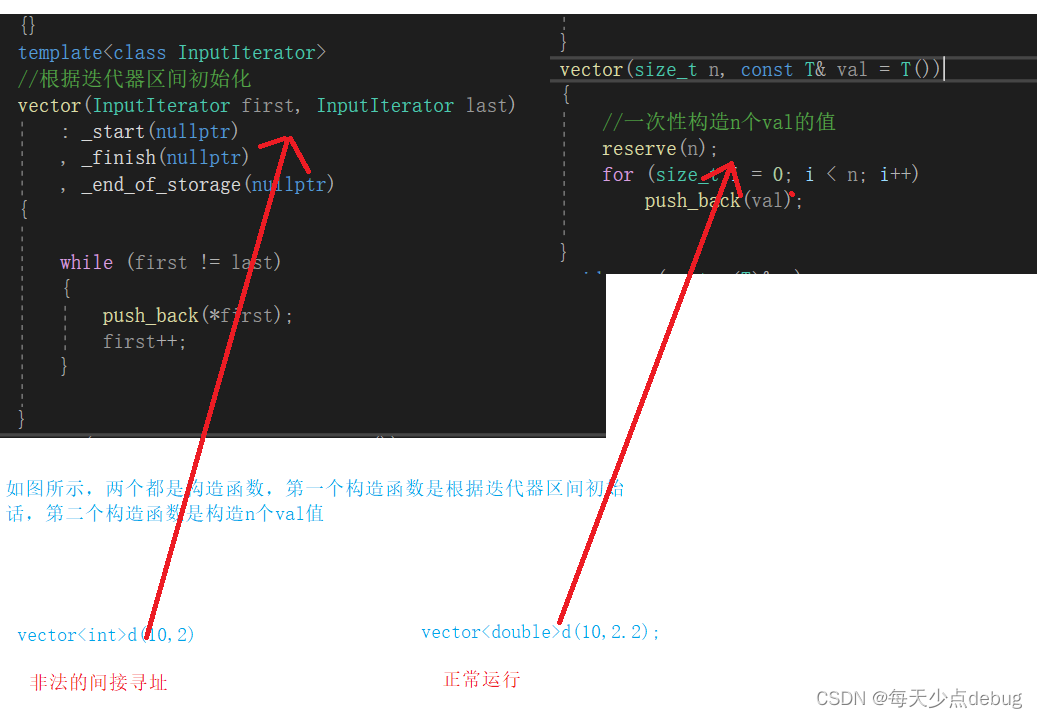
vectord(10,2)两个参数的类型都是int,如果调用第一个函数,此时的模板参数InputIterator被实例化成int,如果调用第二个函数的话,此时第二个函数的第二个参数类型被实例化成int,但是第一个参数类型size_t,如果调用的话还涉及到隐式类型转换,比较下来的话,调用第一个函数更加匹配,但是,此时*this不能解引用,所以会报错出现非法的间接寻址
而vectord(10,2.2),此时vector的参数类型是int double,由于第一个函数的两个参数类型都是相同的,所以不能调用,但此时第二个函数的T被实例化成double,第一个参事size_t隐式类型转换成int。
总结·:编译器调用时时调用与自己最匹配的构造函数
解决方式:
vector(int n, const T& val = T())
将size_t换成int
编译错误和运行时错误
编译错误就是由编译器检查出来的,不符合基本的语法规则,比如语句后面少了;或者 } 不匹配之类的,选择题一般是这样。编译错误可以由编译器检查出来
运行时错误:
1,一种是由于考虑不周或输入错误导致程序异常,比如数组越界访问,除数为0,堆栈溢出等等
2,另一种是由于程序设计思路的错误导致程序异常或难以得到预期的效果
一个
非常重要的运行时错误——迭代器失效
迭代器失效
Stl_vector整体实现
#define _CRT_SECURE_NO_WARNINGS 1
#pragma once
#include<assert.h>
namespace zjt
{
template<class T>
class vector
{
public:
typedef T* iterator;
typedef const T* const_iterator;
size_t size()const
{
return _finish - _start;
}
size_t capacity()//const
{
return _end_of_storage - _start;
}
//上述返回size()和capacity()后面加上const都是好习惯
//避免函数中修改类对象
iterator begin()
{
return _start;
}
iterator end()
{
return _finish;
}
const_iterator begin()const//两种迭代器调用时,编译器调用最匹配的那个
//const_iterator 对象不能改变,没加const可以改变
{
return _start;
}
const_iterator end()const
{
return _finish;
}
vector()//默认构造函数
:_start(nullptr)
,_finish(nullptr)
,_end_of_storage(nullptr)
{}
template<class InputIterator>
//根据迭代器区间初始化
vector(InputIterator first, InputIterator last)
: _start(nullptr)
, _finish(nullptr)
, _end_of_storage(nullptr)
{
while (first != last)
{
push_back(*first);
first++;
}
}
vector(size_t n, const T& val = T())
{
//一次性构造n个val的值
reserve(n);
for (size_t i = 0; i < n; i++)
push_back(val);
}
void swap(vector<T>& x)
{
std::swap(_start, x._start);
std::swap(_finish, x._finish);
std::swap(_end_of_storage, x._end_of_storage);
}
//拷贝构造
vector(const vector<T>& x)
:_start(nullptr)
, _finish(nullptr)
, _end_of_storage(nullptr)
//现代写法
{
//先让tmp根据迭代器区间构造对象tmp
//使tmp与this交换后,让tmp自身去调用析构函数
vector<T>tmp(x.begin().x.end());
swap(tmp);
}
//赋值运算符重载
vector<T>& operator=(const vector<T>x)
{
swap(x);
return *this;
}
//这边只能是传值调用,不能传引用
//因为传值调用的话,此时x是被赋值的临时拷贝
//我们直接拿临时拷贝和*this交换便可
~vector()//析构函数
{
if (_start)//避免未未插入元素就析构
{
delete[]_start;
_finish = _end_of_storage = nullptr;
}
}
void reserve(size_t n)
{
//扩容
//仅支持扩容不支持缩
size_t sz = size();
if (n > capacity())
{
T* tmp = new T[n];
//if (_start)//防止是第一次扩容
//{
// memcpy(tmp, _start, sizeof(T) * size());
// delete []_start;
//}
if (_start)
{
for (size_t i = 0; i < sz; i++)
tmp[i] = _start[i];
}
//memcpy 是内存的二进制格式拷贝,将一段内存空间中的内容原封不动
//的拷贝到另外一段内存中
//如果拷贝的是自定义类型的元素,memcpy既高效又不会出错
//但如果拷贝的是自定义类型的元素,并且自定义类型元素中
//涉及到资源管理时,就会出错,因为memcpy的拷贝实际上是浅拷贝
_start = tmp;//注意:此时_start的值要改变
}
//_finish = _start + size();//错误写法
_finish = _start + sz;
_end_of_storage = _start + n;
}
void resize(size_t n,const T&val = T())//resize是支持扩容与缩容的
{
if (n > capacity())
reserve(n);
if(n>size())
{
/*for (size_t i = size(); i < n; i++)
_start[i] = val;*/
while (_finish < _start + n)
{
*_finish = val;
++_finish;
}
}
//如果此时n<size()
else
{
_finish = _start + n;
}
}
void pop_back()
{
if (_finish > _start)//排除空数组
{
--_finish;
}
}
void push_back(const T& x)
{
if (_finish == _end_of_storage)//表示此时要扩容
{
size_t newcapacity = capacity() == 0 ? 4 : capacity() * 2 + 1;
reserve(newcapacity);//扩容
}
*_finish = x;
++_finish;
}
T&operator[](size_t pos)
{
//有pos位置的一定要判断一下是否越界
assert(pos < size());
return _start[pos];
}
const T& operator[](size_t pos)const
{
//有pos位置的一定要判断一下是否越界
assert(pos < size());
return _start[pos];
}
void clear()
{
//使得容器中有效元素的个数为01
_finish = _start;
}
iterator erase(iterator pos)
{
assert(pos >= _start && pos < _finish);
auto it = pos + 1;
while (it != _finish)
{
_start[it - 1] = _start[it];
it++;
}
_finish--;
return pos;
}
iterator insert(iterator pos, const T& x)
{
assert(pos >= _start && pos < _finish);
//扩容
//扩容以后pos就失效了,需要重新更新一下
if (_finish == _end_of_storage)
{
size_t n = pos - _start;
size_t newcapacity = capacity() == 0 ? 4 : capacity() * 2 + 1;
reserve(newcapacity);
pos = _start + n;
}
iterator end = _finish - 1;
while (end >= pos)
{
*(end + 1) = *end;
end--;
}
*pos = x;
_finish++;
return pos;
}
private:
iterator _start;//表示vector起始位置
iterator _finish;//最终位置的下一个地址
//其中_finnish-_start表示的是数组的有效数据个数
iterator _end_of_storage;//_end_of_storage-_start表示的是数组中总容量大小
};
}


















 3242
3242

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











