




1、前期准备
数据表:轨迹信息表:TRACE_INFO

2、插入数据研究
目前不支持批量插入数据的接口,模拟只能循环插入数据,测试一个批量插入100000条数据,平均时间大概在190s。
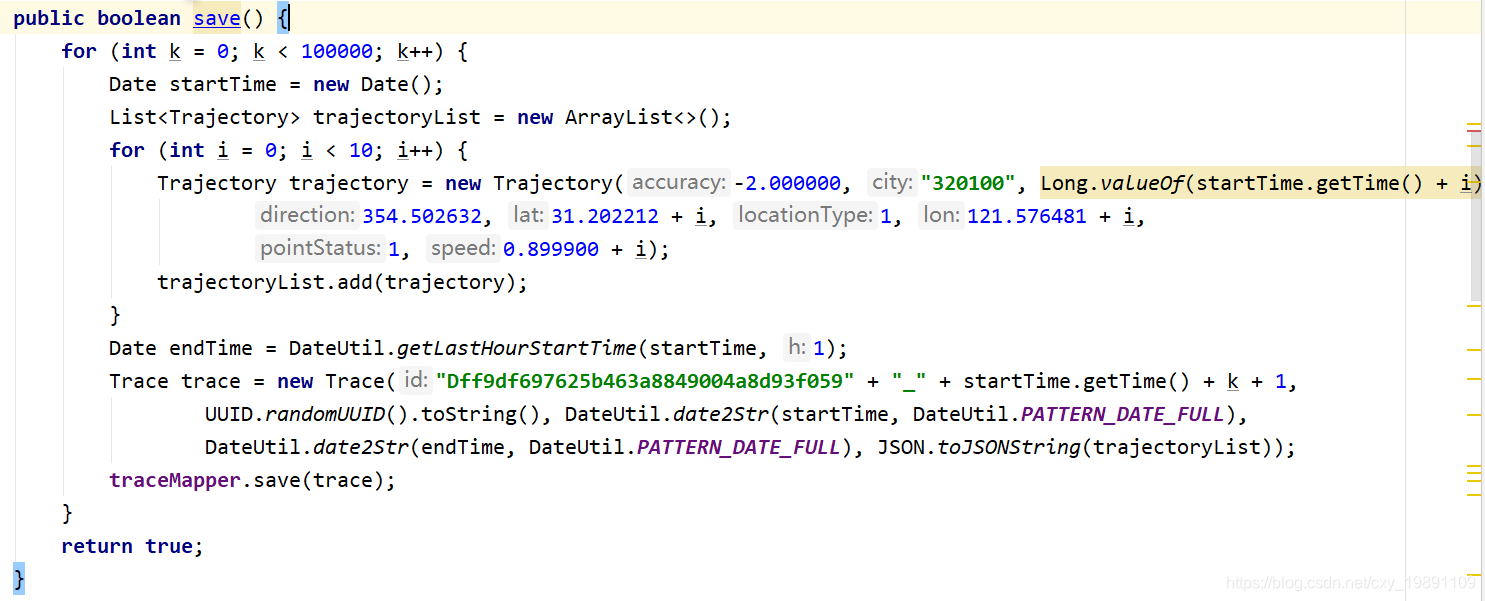

目前表里已经有1000000条数据:
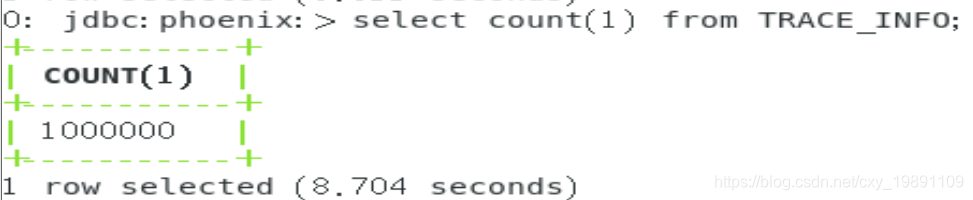
3、根据条数限制查询
查询100条(0.314s):

4、根据某个ID进行查询(0.175s)
ID 是唯一的主键

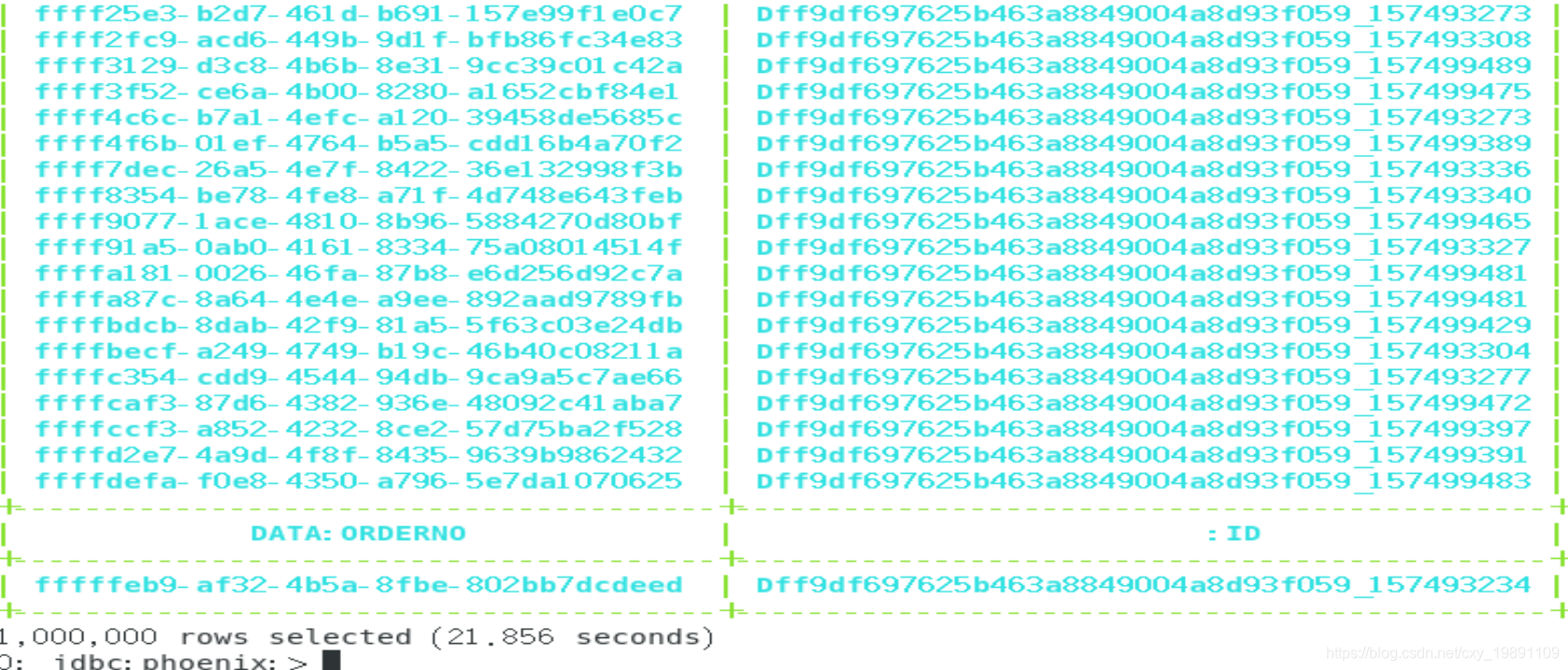
5、根据订单号进行查询(非主键,也无索引)(7.106s)
SELECT orderNo from TRACE_INFO where orderNo=‘59f47f95-a68a-4ab5-9589-a42cad5c4659’;

6、给订单号加个索引再查询
为订单号增加二级索引:
CREATE INDEX DATA_INDEX_ORDER_NO ON TRACE_INFO(ORDERNO);

索引表:
select * from DATA_INDEX_ORDER_NO;
继续查询:
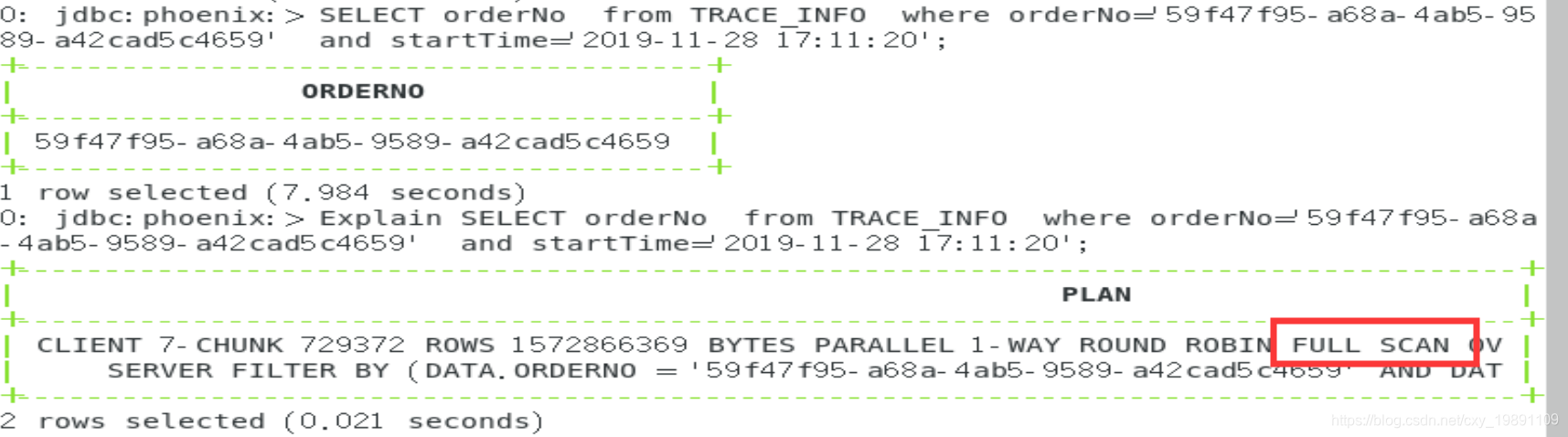
SELECT orderNo from TRACE_INFO where orderNo=‘59f47f95-a68a-4ab5-9589-a42cad5c4659’;

查询计划分析:
EXPLAIN SELECT orderNo from TRACE_INFO where orderNo=‘59f47f95-a68a-4ab5-9589-a42cad5c4659’;
走的是我们刚刚建立的订单号索引:

如果我们把查询内容改成时间,再看看:
SELECT startTime from TRACE_INFO where orderNo=‘59f47f95-a68a-4ab5-9589-a42cad5c4659’;

发现需要7.917s,依旧很慢,为什么我们给订单号加了二级索引,而查询也是根据订单号查询,区别在于查询的不是订单号,而是时间。(第一种情形)
查询计划分析显示:全表扫描

我们再看另一种情况,我们在前面查询订单号的基础上,增加时间的查询条件再看下:7.743s(第二种情形)

依然是全表扫描

分析两种情况的原因:
第一种:
官网索引:Global mutable index will not be used unless all of the columns referenced in the query are contained in the index.
orderNo字段虽然是索引字段但是startTime字段并不是索引字段,也就是说需要查询出来的字段必须都是索引字段
第二种:查询条件startTime不是索引
那么此时把startTime也加入二级索引:
CREATE INDEX DATA_INDEX_START_TIME ON TRACE_INFO(startTime);

再进行前面2种查询:
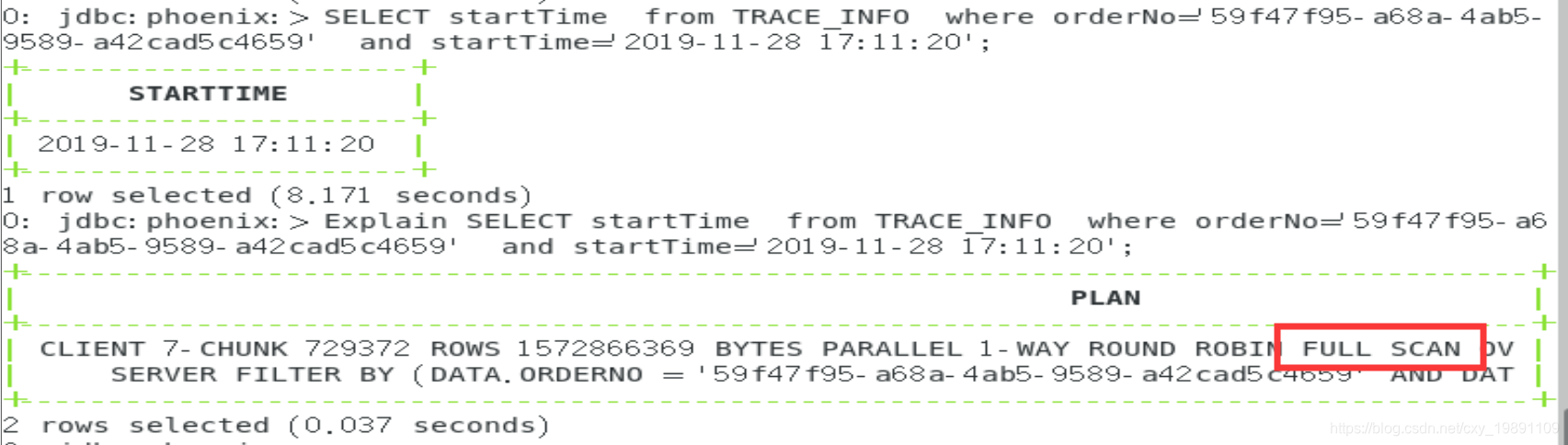
发现没有用到索引,那么我们把建立的索引都删除,建立覆盖索引试试:
drop index DATA_INDEX_ORDER_NO on TRACE_INFO;
drop index DATA_INDEX_START_TIME on TRACE_INFO;

创建覆盖索引:
CREATE INDEX IDX_COVER on TRACE_INFO(orderNo) include (startTime);
再来查询,性能陡然上升:
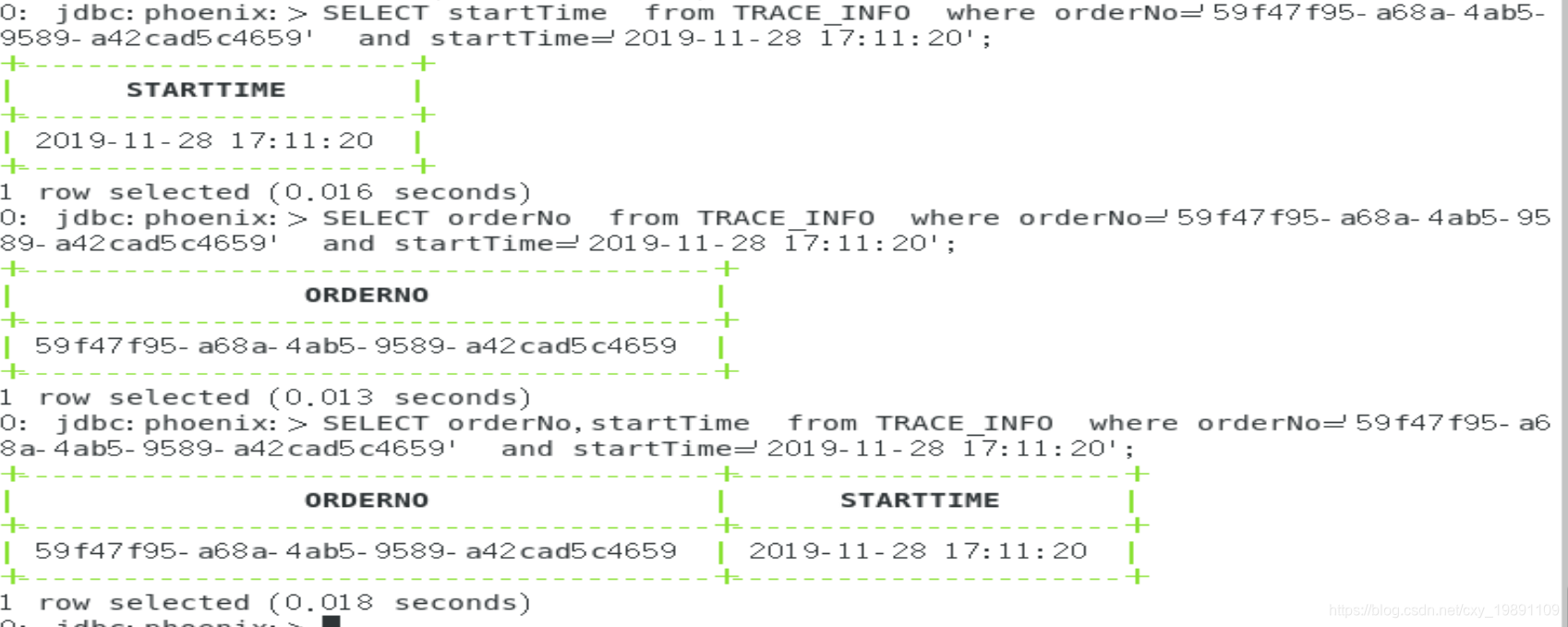
原因:索引覆盖其实就是将INCLUDE里面包含的列都存储到索引表里面,当检索的时候就可以从索引表里直接带回这些列值。要特别注意索引列和索引覆盖列的区别,索引列在索引表里面是以rowkey的形式存在,
多个索引列以某个约定的字节分割然后一起存储在rowkey里面,也就是说当索引列有很多个的时候,rowkey的长度也相应会变长,大小取决于索引列值的大小。而索引覆盖列,是存储在索引表的列族中。但是
使用这种方式创建的所有会导致startTime字段的值被拷贝到索引中,缺点就是会导致索引表大小有一定的增加。
查询索引表my_index结构,增加了startTime这列:

除了建立覆盖索引的优化手段,还可以采用组合索引方式:可以创建组合索引来解决多个条件查询索引命中问题,组合索引的第一个字段必须要在查询条件中
先去掉覆盖索引:
drop index IDX_COVER on TRACE_INFO;
再建立组合索引:
create index IDX_GROUP on TRACE_INFO(orderNo,startTime);
继续查询:
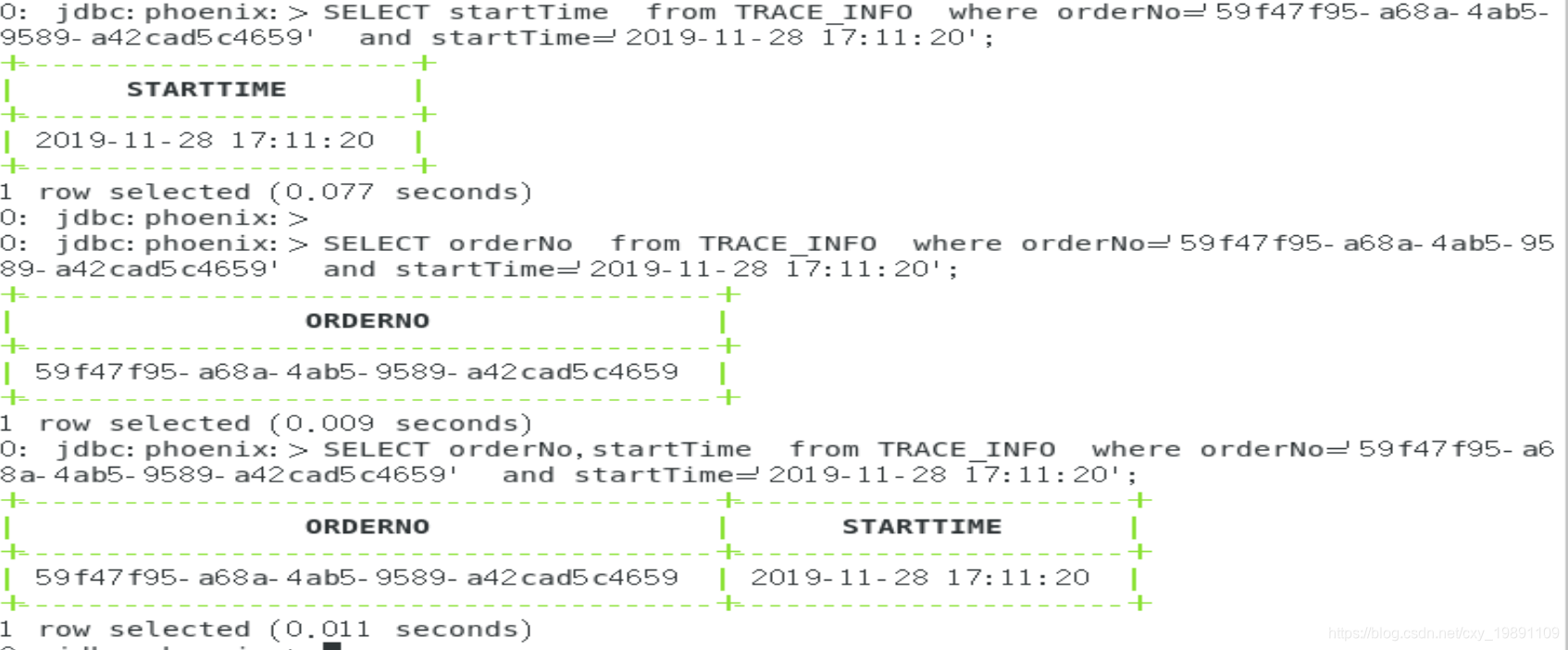
同样有效果!
注意:多列索引在满足前缀式的情况才会用到,如创建了A,B,C顺序的多列索引,当在where条件指定A条件、A B条件或者A B C条件均会走索引,但是 B C条件则无法走索引。(类似MYSQL的最左前缀匹配)
7、结论:
功能页面多一个查询条件,就要多建立好几个二级索引。才能满足速度要求。
比如orderNo 和 startTime,都不是必填项。
用户可能只输入orderNo ,需要1个二级索引;可能只输入startTime,需要1个二级索引;可能同时输入两个,需要1个二级索引。
简单的两个条件,就要3个索引。
比如页面有6个查询条件!!需要多少二级索引!!! 几何倍增长,通常同一张表,索引数量不得超过10,索引表越多,插入数据越慢。
1、从需求方面 (大数据查询,不适合太多条件的查询)。无意义的查询条件,统统去掉。
需要规定一个必填的查询字段,比如最通用的:时间(yyyy-MM-dd)..
2、从表设计方面,row key可以是联合主键。可以利用这点,减少二级索引数量。比如ID 就是主键。
3、从逻辑方面,比如我需要这几个查询条件,需要几个二级索引,可以采用覆盖索引,或者建立联合索引。
8、关于索引
全局索引适用于读频繁的场景。对于全局索引,所有性能消耗都发生在写入时,所有对业务表的更新操作(DELETE, UPSERT VALUES and UPSERT SELECT),会引起索引的更新,
而索引是分布在不同的节点上的,跨节点的数据传输带来了较大的性能消耗。在读数据的时候 Phoenix 会选择最快的索引,把它当作一般的 HBase 表来扫描,而不去扫描业务表。
在默认情况下,没有指定强制使用索引,如果查询的字段没有在索引列的话,这种情况下索引不会被使用。
本地索引适用于写频繁、且存储空间有限的场景。和全局索引一样,Phoenix 会在查询时自动选择是否使用本地索引。使用本地索引,索引数据和表数据会写到同一个 Region Servers 上,
从而避免了写入期间的网络开销。本地索引即使未完全覆盖业务表的所有字段,在查询的时候也会使用索引(Phoenix 会自动检索索引之外的字段,通过点查询业务表获得数据)。
不同于全局索引,在4.8.0版本之前,业务表的所有本地索引都存储在一个单独的共享表中。在4.8.0版本之后,所有的本地索引数据都被存储在同一业务表的单独列族中。
在使用本地索引的读取数据时,因为不能预先确定索引数据的确切区域位置,因而会对读取速度有一定的影响。

















 1155
1155

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









