



数据结构部分
一 摘要
本学期所学内容(按照时间顺序)
引例(复杂度分析),线性结构,树,图,散列 ,排序
二 复杂度分析


三 线性结构
线性表
0.一些例题
1.若某线性表最常用的操作是存取任一指定序号的元素和在最后进行插入和删除运算,则利用顺序表存储最节省时间。
对
2.数组A[1..5,1..6]每个元素占5个单元,将其按行优先次序存储在起始地址为1000的连接内存单元中,则元素A[5,5]的地址为()。
1140 1000+4*6*5+4*5=1140
3.单项链表的反转
List Reverse( List L )
{
Position Old_head, New_head, Temp;
New_head = NULL;
Old_head = L->Next;
while ( Old_head ) {
Temp = Old_head->Next;
Old_head->Next = New_head;
New_head = Old_head;
Old_head = Temp;
}
L->Next=New_head;
return L;
}
4.将N个数据按照从小到大顺序组织存放在一个单向链表中。如果采用二分查找,那么查找的平均时间复杂度是O(logN)。
错,O(N).
5.某线性表中最常用的操作是在最后一个元素之后插入一个元素和删除第一个元素,则采用什么存储方式最节省运算时间?
仅有尾指针的单循环链表。
6.将线性表La和Lb头尾连接,要求时间复杂度为O(1),且占用辅助空间尽量小。应该使用哪种结构?
带尾指针的单循环链表
7.从有N个元素的线性表A中查找第K小的元素,函数的初始调用为Qselect(A, K, 0, N-1)。
ElementType Qselect( ElementType A[], int K, int Left, int Right )
{
ElementType Pivot = A[Left];
int L = Left, R = Right+1;
while (1) {
while ( A[++L] < Pivot );
while(A[--R] > Pivot);
if ( L < R ) Swap( &A[L], &A[R] );
else break;
}
Swap( &A[Left], &A[R] );
if ( K < (L-Left) )
return Qselect(A, K, Left, R-1);
else if ( K > (L-Left) )
return Qselect(A, K-L+Left, R+1, Right);
else
return Pivot;
}
1.通常使用结构的嵌套来定义单向链表结点的数据类型。
typedof struct Node *PtrToNode
struct Node{
ElementType Data;
PtrToNode Next;
};
Typedof PtrToNode List;

2.单向链表的常见操作(所有操作都需要判断其合法性)
(1)插入结点(将t结点插在p结点之后)
t->Next=p->Next;
p->Next=t;
若在链表头上插入结点t
t->Next=head;
head=t;
(2)删除结点
从单向链表head中删除p结点之后的那个结点
t=p->Next;
p->Next=t->Next;
free(t);//释放t结点的空间
(3)单向链表的遍历
p=head
while(p!=NULL)
......
对结点信息进行处理;
......
p=p->Next;
(4)链表的建立
两种方式:头插法,尾插法。
有时为了程序处理方便,会在单向链表的头上加一个空结点,将该点data空置。这种链表成为带头结点的单向链表。
3.双向链表
typedof struct Node *PtrToNode
struct Node{
ElementType Data;
PtrToNode Next;
PtrToNode Previous;
};
Typedof PtrToNode DList;
双向链表基本运算的实现逻辑:
p->prior->next == p == p->next->prior
删除运算
void DELETENODE(DList p){ /*删除结点*p */
p->prior->next = p->next; //*p的前趋指向其后继
p->next->prior = p->prior; //*p的后继指向其前趋
free(p);
}
堆栈
0.一些例题
1.若一个栈的输入序列为1,2,3,…,N,输出序列的第一个元素是 i,则第j个输出元素是 j−i−1。
错,不确定。当j<i,答案为i-j+1,当j>i,栈可以边进边出
2.
若top为指向栈顶元素的指针,判定栈S(最多容纳m个元素)为空的条件是
S->top == -1
1.基本操作
typedef int Position;
typedef struct SNode *PtrToSNode;
struct SNode {
ElementType *Data; /* 存储元素的数组 */
Position Top; /* 栈顶指针 */
int MaxSize; /* 堆栈最大容量 */
};
typedef PtrToSNode Stack;
(1) 堆栈初始化(建立空栈)
/* 构建一个堆栈的头结点,返回该结点指针 */
Stack CreateStack( )
{
Stack S;
S = (PtrToSNode)malloc(sizeof(struct SNode));
S->Next = NULL;
return S;
}
(2) 判断堆栈S是否为空
/* 判断堆栈S是否为空,若是返回true;否则返回false */
bool IsEmpty ( Stack S )
{
return ( S->Next == NULL );
}
(3)将元素压入栈
bool Push( Stack S, ElementType X ) /* 将元素X压入堆栈S */
{ PtrToSNode TmpCell;
TmpCell = (PtrToSNode)malloc(sizeof(struct SNode));
TmpCell->Data = X;
TmpCell->Next = S->Next;
S->Next = TmpCell;
return true;
}
ElementType Pop( Stack S ) /* 删除并返回堆栈S的栈顶元素 */
{
PtrToSNode FirstCell;
ElementType TopElem;
if( IsEmpty(S) ) {
printf("堆栈空"); return ERROR;
}
else {
FirstCell = S->Next;
TopElem = FirstCell->Data;
S->Next = FirstCell->Next;
free(FirstCell);
return TopElem;
}
}
2.堆栈的应用(表达式求值)

队列
0.一些例题
(1)队列是一种插入与删除操作分别在表的两端进行的线性表,是一种先进后出型结构。
错,先进先出
(2)栈和队列的共同点是只允许在端点处插入和删除元素
(3)判断一个循环队列QU(长度为MaxSize)为空的条件:QU->front == (QU->rear+1)% MaxSize
(4)循环队列用数组A[0,m-1]存储,已知头尾指针分别是front和rear,则当前队列中的元素个数是rear-front+1
(5)
在用数组表示的循环队列中,front值一定小于等于rear值。
错,循环队列
1.基本操作
(1)建队列
typedef int Position;
typedef struct QNode *PtrToQNode;
struct QNode{
ElementType *Data;
Position rear, front ;
int MaxSize;
} ;
typedef PtroToQNode Queue;
Queue CreateQueue(int MaxSize){
Queue Q=(Queue)malloc(sizeof(struct QNode));
Q->Data=(ElementType*)malloc(MaxSize*sizeof(ElementType));
Q->Front=Q->Q->Rear=0;
Q->MaxSize=MaxSize;
return Q;
}
(2)其他
/*判断是否为空*/
bool IsEmpty( Queue Q ){
return ( Q->Front == NULL);
}
/*删除元素*/
ElementType DeleteQ( Queue Q )
{ Position FrontCell;
ElementType FrontElem;
if ( IsEmpty(Q) ) {
printf("队列空"); return ERROR;
}
else {
FrontCell = Q->Front;
if ( Q->Front == Q->Rear ) /* 若队列只有一个元素 */
Q->Front = Q->Rear = NULL; /* 删除后队列置为空 */
else
Q->Front = Q->Front->Next;
FrontElem = FrontCell->Data;
free( FrontCell ); /* 释放被删除结点空间 */
return FrontElem;
}
}
/*Push(X,D):将元素X插入到队头*/
if 队满,返回;
D->data[D->front]=X;
D->front=(D->front-1+D->maxsize)%D->maxsize;
/*Pop(D):删除队列的头元素,并返回*/
if 队空,返回;
D->front=(D->front+1+D->maxsize)%D->maxsize;
return D->data[D->front];
/*Inject(X,D):将元素X插入到队尾*/
if 队满,返回;
D->rear=(D->rear+1+D->maxsize)%D->maxsize;
D->data[D->rear]=X;
/*Eject(D):删除队列的尾部元素,并返回*/
if 队空,返回;
y=D->data[D->rear];
D->rear=(D->rear-1+D->maxsize)%D->maxsize;
return y;
2.队列的应用
如何用两个堆栈模拟实现一个队列
入队:1 2 3 4 … n
模拟过程:入栈1,出栈1再入栈2(容量为n)
入队:n+1 n+2 … 2n+1
模拟过程:入栈1
出队:1 2 … 2n+1
模拟过程:栈2 出栈,栈1出栈入栈2 栈1顶出栈, 栈2再出栈
容量:2n+1
四 树
0.一些例题
(1)在一棵二叉搜索树上查找63,序列39、101、25、80、70、59、63是一种可能的查找时的结点值比较序列。
错,不可能出现39,101,25
(2)
一棵有124个结点的完全二叉树,其叶结点个数是确定的。
对
完全二叉树的叶结点问题:设叶子节点个数为n0,度为1的节点个数为n1,度为2的节点个数为n2 ,有n0+n1+n2=n (1) 对于二叉树有:n0=n2+1(2)
由(1)(2) ==>n0=(n+1-n1)/2 由完全二叉树的性质可知:n1=0 或 1
则当n1=0时(即度为1的节点为0时,此时n为奇数)n为奇数时 n0= (n+1)/2;
当n1=1时(即度为1的节点为1个时,此时n为偶数)或者n为偶数 n0= n/2;
即一个具有n个节点的完全二叉树,其叶子节点的个数n0为: n/2 向上取整,或者(n+1)/2 向下取整
(3)若一个结点是某二叉树的中序遍历序列的最后一个结点,则它必是该树的前序遍历序列中的最后一个结点。
错,中序为:左根右,前序为:根左右 。
最后的子树可能不存在右子树,中序遍历里最后一个结点为子树的根结点,前序遍历里的最后一个结点为子树的左结点。
(4)
AVL树是一种平衡的二叉搜索树,树中任一结点具有下列哪一特性:
A.左、右子树的高度均相同 B.左、右子树高度差的绝对值不超过1
C.左子树的高度均大于右子树的高度 D.左子树的高度均小于右子树的高度
B 平衡树性质
(5)若一棵二叉树的后序遍历序列是{ 1, 3, 2, 6, 5, 7, 4 },中序遍历序列是{ 1, 2, 3, 4, 5, 6, 7 },则下列哪句是错的?
A.这是一棵完全二叉树 B.2是1和3的父结点
C.这是一棵二叉搜索树 D.7是5的父结点
A 后序遍历顺序为左右根,中序遍历顺序为左根右。4为根结点。按照中序遍历结果建完全二叉树,按照后序遍历,得到的序列应为{1,3,2,5,7,6,4}
(6)将{ 32, 2, 15, 65, 28, 10 }依次插入初始为空的二叉搜索树。则该树的前序遍历结果是:
D.32, 2, 15, 10, 28, 65 前序遍历:根左右
(7)
在一棵度为 3 的树中,度为 2 的结点个数是 1,度为 0 的结点个数是 6,则度为 3 的结点个数是?
2
设度为0的结点个数为n0,度为1的结点个数为n1,度为2的结点个数为n2,度为3的个数n3
树中结点总数n0+ n1 + n2 + n3,所有边的数量为0 * n0 + 1 * n1 + 2 * n2 + 3 * n3
树中结点比边多1个,合并这两个式子就可以得到:n0 = 1 + n2 + 2 * n3
代入数据可以得到n3 = 2,度为3的结点个数是2
1.一些定义与性质
1.结点的度(Degree):一个结点的度是其子树的个数。
2.树的度:树的所有结点中最大的度数。
3.叶结点(Leaf):是度为0的结点;也称为端结点。
4.父结点(Parent):有子树的结点,是其子树的根结点的父结点。
5.子结点(Child):若A结点是B结点的父结点,则称B结点是A结点的子结点;子结点也称孩子结点。
6.兄弟结点(Sibling):具有同一父结点的各结点彼此是兄弟结点。
7.分支:树中两个相邻结点的连边称为一个分支。
8.路径和路径长度:从结点n1到nk的路径被定义为一个结点序列n1 , n2 ,… , nk ,对于1£ i £ k, ni是 ni+1的父结点。一条路径的长度为这条路径所包含的边(分支)的个数。
9.祖先结点(Ancestor):沿树根到某一结点路径上的所有结点都是这个结点的祖先结点。
10.子孙结点(Descendant):某一结点的子树中的所有结点是这个结点的子孙。
11. 结点的层次(Level):规定根结点在1层,其它任一结点的层数是其父结点的层数加1。12. 树的高度(Height):树中所有结点中的最大层次是这棵树的高度。
二叉树的性质(选择判断会考到)
1.在二叉树的第i层上最多有2 i-1 个节点 。(i>=1)
2.二叉树中如果深度为k,那么最多有2k-1个节点。(k>=1)
3.n0=n2+1 n0表示度数为0的节点 n2表示度数为2的节点
4.在完全二叉树中,具有n个节点的完全二叉树的深度为[log2n]+1,其中[log2n]+1是向下取整。
5.若对含 n 个结点的完全二叉树从上到下且从左至右进行 1 至 n 的编号,则对完全二叉树中任意一个编号为 i 的结点:
(1) 若 i=1,则该结点是二叉树的根,无双亲, 否则,编号为 [i/2] 的结点为其双亲结点;
(2) 若 2i>n,则该结点无左孩子, 否则,编号为 2i 的结点为其左孩子结点;
(3) 若 2i+1>n,则该结点无右孩子结点, 否则,编号为2i+1 的结点为其右孩子结点。
一棵完全二叉树
2.二叉树的链式存储结构
typedef struct TNode *Position;
typedef Position BinTree; /* 二叉树类型 */
struct TNode{
ElementType Data; /* 结点数据 */
BinTree Left; /* 指向左子树 */
BinTree Right; /* 指向右子树 */
};
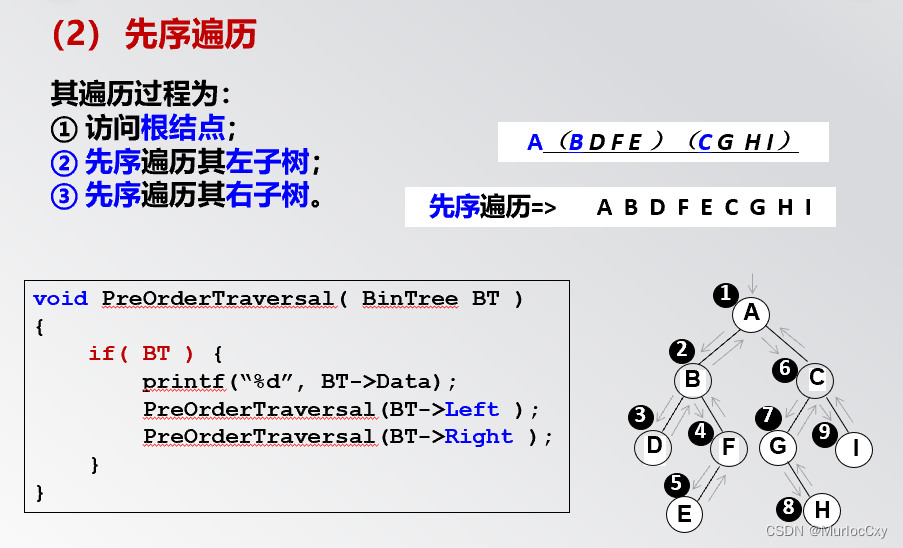
3.二叉树的遍历(★★★)
树的遍历是指访问树的每个结点,且每个结点仅被访问一次。二叉树的遍历可按二叉树的构成以及访问结点的顺序分为四种方式,即先序遍历、中序遍历、后序遍历和层次遍历。





二叉树 非递归遍历



4 二叉搜索树
二分查找
当线性表中的数据元素是有序存放时,可以改进顺序查找算法,以得到更高效率的新算法----二分法 (折半查找)
二分查找是每次在要查找的数据集合中取出中间元素关键字Kmid与要查找的关键字K进行比较,根据比较结果确定是否要进一步查找。
•当 Kmid=K ,查找成功;•否则,将在Kmid的左半部分( 当Kmid>K )或者右半部分( 当Kmid<K )继续下一步查找。以此类推,每步的查找范围都是上一次的一半。
二叉搜索树的一些特殊操作
Position Find( BinTree BST, ElementType X ):从二叉搜索树BST中查找元素X,返回其所在结点的地址;
Position FindMin( BinTree BST ):从二叉搜索树BST中查找并返回最小元素所在结点的地址;
Position FindMax( BinTree BST ) :从二叉搜索树BST中查找并返回最大元素所在结点的地址。
BinTree Insert( BinTree BST, ElementType X )
BinTree Delete( BinTree BST, ElementType X )






树的应用
0.一些例题
(1)设一段文本中包含4个对象{a,b,c,d},其出现次数相应为{4,2,5,1},则该段文本的哈夫曼编码比采用等长方式的编码节省了多少位数?
1*5+2*4+3*3=22,24-22=2
(2)对最小堆(小顶堆){1,3,2,6,7,5,4,15,14,12,9,10,11,13,8} 进行三次删除最小元的操作后,结果序列为: 4,6,5,13,7,10,8,15,14,12,9,11
(3)在并查集问题中,已知集合元素0~8所以对应的父结点编号值分别是{ 1, -4, 1, 1, -3, 4, 4, 8, -2 }(注:−n表示树根且对应集合大小为n),那么将元素6和8所在的集合合并(要求必须将小集合并到大集合)后,该集合对应的树根和父结点编号值分别是多少? 4和-5
堆和并查集
【定义】 “优先队列” (Priority Queue)是特殊的“队列”,从堆中取出元素的顺序是依照元素的优先权(关键字)大小,而不是元素进入队列的先后顺序。采用完全二叉树存储的优先队列 称为堆(Heap)。
类型名称:最大堆(MaxHeap)
数据对象集:一个有N>0个元素的最大堆H是一棵完全二叉树,每个结点上的元素值不小于其子结点元素的值。
操作集:对于任意最多有MaxSize个元素的最大堆H Î MaxHeap,元素 X Î ElementType,主要操作有:
•MaxHeap Create( int MaxSize )•bool IsFull( MaxHeap H )•bool Insert( MaxHeap H, ElementType X )•bool IsEmpty( MaxHeap H )•ElementType DeleteMax( MaxHeap H )
堆排序的基本思路:
a.将无序序列构建成一个堆,根据升序降序需求选择大顶堆或小顶堆;
b.将堆顶元素与末尾元素交换,将最大元素"沉"到数组末端;
c.重新调整结构,使其满足堆定义,然后继续交换堆顶元素与当前末尾元素,反复执行调整+交换步骤,直到整个序列有序。
五 图
0.一些习题
(1)如果无向图G必须进行两次广度优先搜索才能访问其所有顶点,则G中一定有回路。
错,G中一定有两个连通分支。
(2)给定有权无向图的邻接矩阵如下,其最小生成树的总权重是:
最小生成树
两种算法
(1)Prim算法:
Prim算法基本思想:
1.首先,置S={1};
2.然后,只要S是V的真子集,就作如下的贪心选择:选取满足条件i ∈ ∈ S,j ∈ ∈ V-S,且c[i][j]最小的边,将顶点j添加到S中。
3.重复上述过程,直到S=V时为止。

Prim算法实现:
1.初始化,s[1]=1,s[2~n]=0;dist[1]=0,
dist[j]=c[1][j],j=2~n
parent[1]=-1, parent[j]=1,j=2~n
2.循环(n-1)次
{
for (j=2 to n) 找s[j]为0 且dist[j]最小的点j;
s[j]=1;
for (k=2 to n)
找s[k]为0 且dist [k]>c[j][k]的点k,
更新{dist[k]=c[j][k]; parent[k]=j;
}
Prim算法利用MST性质不断加点,构建最小生成树。
Kruskal算法则采用不断加边的方法构建最小生成树。
(2)Kruskal算法:
Kruskal算法中的关键步骤:
1.边按照权值从小到大排序2.依次取出每条边,判断边的两个端点是否在同一个连通分支中,如不是1)合并两个端点所在的分支
2)把边加入最小生成树中
3. 重复第2步,直到边数=n-1为止

最短路径问题
0.一些例题
(1)
(2)

(3)Dijkstra代码填空
typedef struct GNode *PtrToGNode;
struct GNode{
int Nv; /* Number of vertices */
int Ne; /* Number of edges */
WeightType G[MaxVertexNum][MaxVertexNum]; /* adjacency matrix */
};
typedef PtrToGNode MGraph;
void Dijkstra( MGraph Graph, int dist[], int path[], Vertex S )
{
int collected[MaxVertexNum];
Vertex V, W;
for ( V=0; V<Graph->Nv; V++ ) {
dist[V] = Graph->G[S][V];
path[V] = -1;
collected[V] = false;
}
dist[S] = 0;
collected[S] = true;
while (1) {
V = FindMinDist( Graph, dist, collected );
if ( V==ERROR ) break;
collected[V] = true;
for( W=0; W<Graph->Nv; W++ )
if ( collected[W]==false && Graph->G[V][W]<INFINITY ) {
if ( dist[V]+Graph->G[V][W] < dist[W]){
dist[W] =dist[V]+Graph->G[V][W];
path[W] = V;
}
}
} /* end while */
}
Floyd
最短路径问题满足最优子结构性质:
u到v的最短路径包含该路径上任意两点间的最短路径。
定义d[k][i][j] :中间点编号≤k,点i到点j之间的最短路径长度。
对于d[k][i][j] ,可以分为两种情况:
(1)i到j的最短路不经过k:d[k][i][j]=d[k-1][i][j]。
(2)i到j的最短路经过k: d[k][i][j]=d[k-1][i][k]+d[k-1][k][j]。
递归式:d[k][i][j] = min(d[k-1][i][j], d[k-1][i][k]+d[k-1][k][j])
void floyd() { /*Floyd算法求解任意两点间的最短路径*/
/*初始化*/
for(int i = 1; i <= n; i++)
for(int j = 1; j <= n; j++)
d[0][i][j] = graph[i][j];
/*自底向上动态规划求解*/
for(int k = 1; k <= n; k++) {
for(int i = 1; i <= n; i++) {
for(int j = 1; j <= n; j++) {
d[k][i][j] = min(d[k-1][i][j], d[k-1][i][k] + d[k-1][k][j]);
}
}
}
}
拓扑排序与关键路径
0.一些例题
(1)
ans:4
(2)
ans:12和14
(3) 用栈实现拓扑排序
void Topsort(int a[NUM][NUM], int TopNum[NUM])
// a[NUM][NUM] is adjacency matrix of the graph with NUM vertices
// TopNum[NUM] stores the topological orders
{ int S[NUM], Indegree[NUM]; //S[NUM] is a stack
int Counter = 0, top, n, i, j;
int V;
top= -1;
n=NUM;
for (j=0; j<n; j++) {
Indegree[j]=0;
for (i=0; i<n; i++)
if (a[i][j]!=0) Indegree[j]++;
if ( Indegree[j] == 0 ) S[++top]=j;
}
while (top>=0) {
V = S[top--];
TopNum[ V ] = ++ Counter; /* assign next */
for (j=0; j<n; j++)
if ( a[V][j]!=0)
if (--Indegree[j]== 0 ) S[++top]=j;
} /* end-while */
if ( Counter!=n ) printf( "Graph has a cycle" );
}
拓扑排序
拓扑排序是指有向无环图(Directed Acyclic Graph,简称DAG)中各顶点构成的有序序列。
如何求一个拓扑排序
1.不断地找入度为0的点输出;
2.并删除其发出的所有边;
3.循环步骤1~2,直到输出所有的点或者找不到入度为0的点为止。
//借助队列求拓扑排序
bool TopSort( Graph Graph, Vertex TopOrder[] )
{ int Indegree[MaxVertexNum], cnt;
Vertex V, W;
Queue Q = CreateQueue( Graph.Nv );
for (Graph的每个顶点V)
Indegree[V] = 0; /* 初始化Indegree[] */
遍历图,得到Indegree[] ;
for (Graph的每个顶点V)
if ( Indegree[V]==0 ) AddQ(Q, V); /* 将所有入度为0的顶点入列 */
/* 下面进入拓扑排序 */
cnt = 0;
while( !IsEmpty(Q) ){
V = DeleteQ(Q); /* 弹出一个入度为0的顶点 */
TopOrder[cnt++] = V; /* 将之存为结果序列的下一个元素 */
for (V的每个邻接点W)
if ( --Indegree[W] == 0) AddQ(Q, W);
} /* while结束*/
if ( cnt != Graph->Nv ) return false; /* 说明图中有回路 */
else return true;
}

AOV图转为AOE图



关键路径


六 散列查找
0.一些例题
(1)给定散列表大小为11,散列函数为H(Key)=Key%11。采用平方探测法处理冲突:hi(k)=(H(k)±i2)%11将关键字序列{ 6,25,39,61 }依次插入到散列表中。那么元素61存放在散列表中的位置是:
5,画出来
(2)设有一组关键字 { 92,81, 58,21,57,45,161,38,117 },散列函数为 h(key)=key%13,采用下列双散列探测方法解决第 i 次冲突:h(key)=(h(key)+i×h2(key))%13,其中 h2(key)=(key%11)+1。试在 0 到 12 的散列地址空间中对该关键字序列构造散列表,则成功查找的平均查找长度为
1.67,同上
1.散列的构造
“散列(Hashing)” 的基本思想是:
存储位置 = h(key) ,h称为散列函数(哈希函数),key为关键字,按这个思想构造的表称为“散列表”,所以它也是一种存储方法。
冲突:可能将不同的关键字映射到同一个散列地址上,即h(keyi) = h(keyj)(当keyi ≠keyj),这种现象称为“冲突(Collision)”, keyi 和keyj称为“同义词(synonym)”。
v装填因子(Loading Factor):设散列表空间大小为m,填入表中的元素个数是n,则称α= n / m为散列表的装填因子。通常取 α=0.5~0.8为宜。
构造方法
1.直接定址法 h(key) = a *key + b
2.除留余数法 h(key) = key mod p
3.数字分析法 h(key) = atoi(key+7)
2.处理的冲突
常用的处理冲突的方法有两种:开放地址法和链地址法。
处理冲突的方法
开放地址法
1. 线性探测法(Linear Probing)
hi(key) = (h(key)+di) mod TableSize, di = 1,2,…,(TableSize -1)
[例] 设关键词序列为 {47,7,29,11,9,84,54,20,30},TableSize =13,h(key) = key mod 11。用线性探测法处理冲突,列出依次插入后的散列表,并估算查找性能。
2. 平方探测法(Quadratic Probing)
以增量序列1^2,-1^2,2^2,-2^2,……,q^2,-q^2且q ≤ TableSize/2 循环试探下一个存储地址。
有定理显示:如果散列表长度TableSize是某个4k+3(k是正整数)形式的素数时,平方探测法就可以探查到整个散列表空间。
[例] 设关键词序列为 {47,7,29,11,9,84,54,20,30},TableSize = 11(即满足4×2+3形式的素数),h(key) = key mod 11。
ASLs= (1+4+4+1+3+1+2+1+1)/ 9 = 18/9=2
3.双散列探测法(Double Hashing)
di 选为i*h2(key)
探测序列还应该保证所有的散列存储单元都应该能够被探测到。选择以下形式有良好的效果:
h2(key) = p - (key mod p)
分离链接法
4.分离链接法
将所有关键词为同义词的数据对象通过结点链接存储在同一个单链表中。




七 排序
0.一些例题
(1)要从50个键值中找出最大的3个值,选择排序比堆排序快。
对,O(n)<O(nlogn)
(2)将序列{ 2, 12, 16, 88, 5, 10, 34 }排序。若前2趟排序的结果如下:
- 第1趟排序后:2, 12, 16, 10, 5, 34, 88
- 第2趟排序后:2, 5, 10, 12, 16, 34, 88
则可能的排序算法是:快速排序,每趟选择基准放其在左右
(3)对初始数据序列{ 8, 3, 9, 11, 2, 1, 4, 7, 5, 10, 6 }进行希尔排序。若第一趟排序结果为( 1, 3, 7, 5, 2, 6, 4, 9, 11, 10, 8 ),第二趟排序结果为( 1, 2, 6, 4, 3, 7, 5, 8, 11, 10, 9 ),则两趟排序采用的增量(间隔)依次是:
5,3 观察其每次排序交换数字的位置
1.一些排序(有点EZ,不写了)
选择排序
一简单选择排序 一堆排序
插入排序
一简单插入排序 一希尔排序
交换排序
一冒泡排序
归并排序


















 3116
3116

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









