



 本文介绍了NumPy数组创建及属性使用、随机数生成、索引与切片操作、矩阵运算等内容,并详细讲解了如何利用Pandas进行文本文件与Excel文件的读写操作以及数据框的构建和访问。
本文介绍了NumPy数组创建及属性使用、随机数生成、索引与切片操作、矩阵运算等内容,并详细讲解了如何利用Pandas进行文本文件与Excel文件的读写操作以及数据框的构建和访问。
numpy
- numpy创建数组及基础属性
numpy是数据处理的基础,pandas也是基于numpy的,首先是numpy数组的创建。
一般我们默认导入了一下库
import numpy as np
import pandas as pd1.numpy创建数组及基础属性
arr=np.array([[1,2,3],[4,5,6],[7,8,9]])numpy的核心特征之一就是N-维数组对象----ndarray。一个ndarray的每个元素均为相同类型
numpy的基础属性:shape ,dtype ,ndim, size
每一个数组都有一个shape属性用来表征数组每一维度的数量;每个数组都有一个dtype属性用来描述数组的数据类型。ndim返回数组的维数。size返回数组元素个数。

- 生成随机数
生成无约束条件的随机数

生成指定shape的均匀随机数

生成符合正太分布的随机数

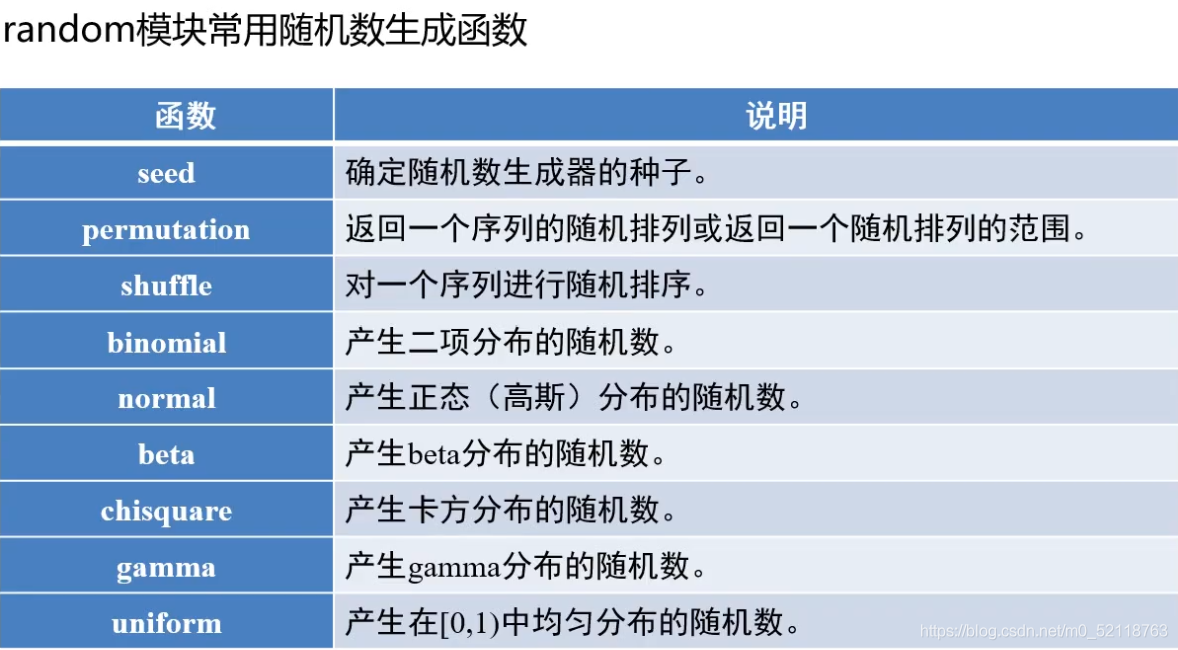
- random具体函数用法
- 一维数组索引
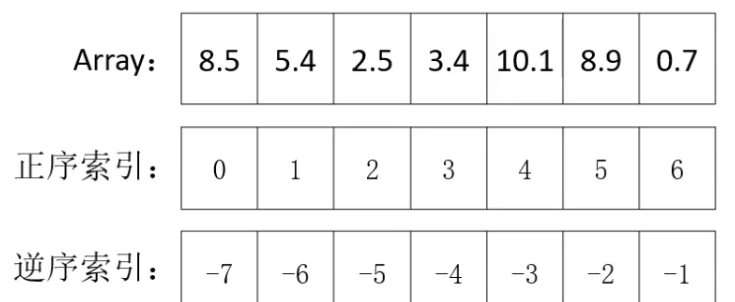
- 布尔索引

只有索引为True的会返回,所以可以根据这一特点筛选想要的数据

- 多维数组的索引

这是一个二维数组,假如我们要取12这个元素,那么我们要找出12所在的行列索引,中间用逗号隔开

对二维数组的切片与一维数组类似

也可以逻辑索引和切片混合

- Numpy矩阵介绍
矩阵的生成

矩阵运算

- Numpy读写二进制文件

- Numpy读写文本文件

pandas
- pandas读取文本文件
一般使用pd.read_csv读取csv文件,read_table读取文本文件。两者的参数基本相同
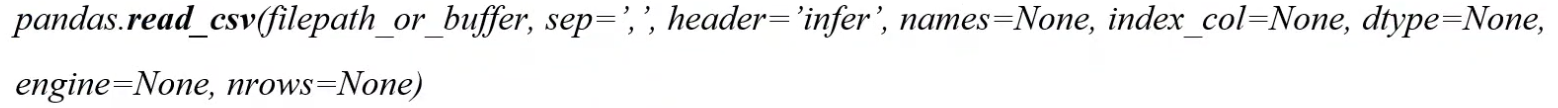

- pandas读取excel文件
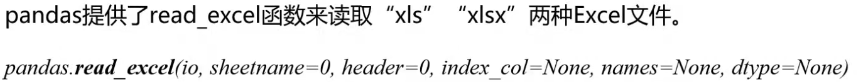

- 将数据框存储为excel文件
这样保存数据左边也会出现一列从0开始的index,可以加参数index

- 构建数据框

创建DataFrame,可以用列表充当data

- 按行列名称访问数据框中的元素
当数据框的数量较大的时候,按顺序访问较为麻烦,这时后可以采用按行列名称访问数据框中的元素。
先构建一个新的数据框
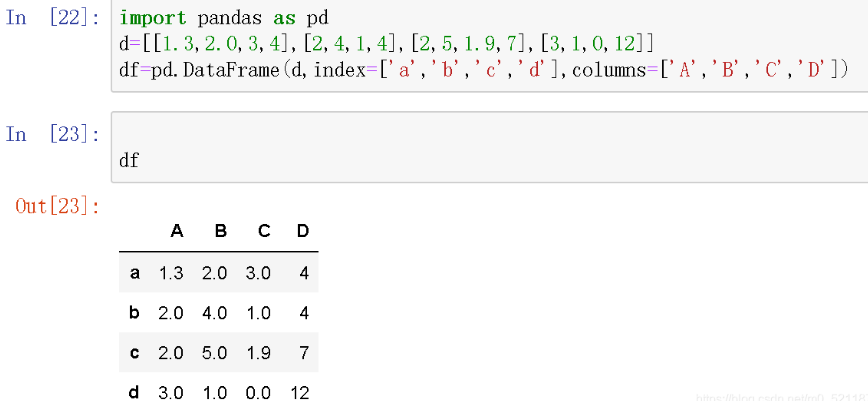
使用loc函数进行名称的访问

- 转换成时间类型数据

- groupby分组操作
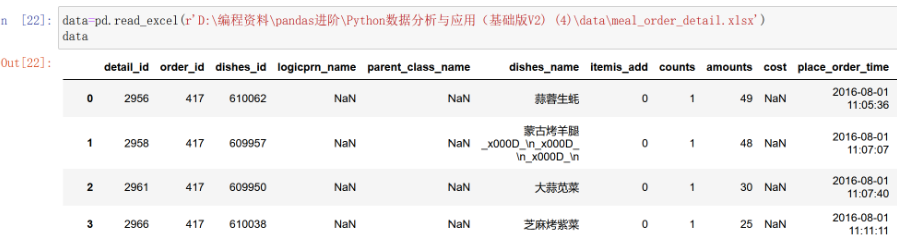
从中提取三列数据,以’order_id’为分组依据


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









