





缓存处理流程:前端发起请求,后端先从缓存中取数据,取到直接返回结果,取不到时从数据库中取,数据库取到更新缓存,并返回结果,数据库也没取到,那直接返回空结果。
缓存穿透:某个key对应的数据在缓存和数据库中都不存在,每次针对此key的请求从缓存获取不到,请求都会到数据库,高并发的对该key的请求可能会压垮数据库。比如用一个不存在的用户id获取用户信息,不论缓存还是数据库都没有,若黑客利用此漏洞进行攻击可能压垮数据库。
缓存击穿:某个key对应的数据在缓存中不存在或在缓存中已过期,但在数据库中存在,此时若有大量并发对该key进行请求,这些请求发现缓存过期一般都会从后端DB加载数据并回设到缓存(该过程需要时间),这个时候大并发的请求可能会瞬间把后端DB压垮。
缓存雪崩:当缓存服务器重启或者大量缓存集中在某一个时间段失效,这样在失效的时候,若有大量并发对数据请求,也会给后端系统(比如DB)带来很大压力。
缓存击穿指并发查同一条数据,缓存雪崩是不同数据都过期了,很多数据都查不到从而查数据库。
1、缓存穿透解决方案
一个一定不存在缓存且在数据库查询不到的数据,由于缓存是不命中时被动写的,并且出于容错考虑,如果从存储层查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到存储层去查询,失去了缓存的意义。
有很多种方法可以有效地解决缓存穿透问题,最常见的则是采用布隆过滤器,将所有可能存在的数据哈希到一个足够大的bitmap中,一个一定不存在的数据会被这个bitmap拦截掉,从而避免了对底层存储系统的查询压力。另外也有一个更为简单粗暴的方法,如果一个查询返回的数据为空(不管是数据不存在,还是系统故障),仍然把这个空结果进行缓存,但它的过期时间会很短,最长不超过五分钟。这种方法有个问题:如果黑客在短时间内使用多个在数据库中不存在的数据发起请求,会导致在缓存中存放大量的空值,从而使得缓存中没有足够的空间存放有效的数据。因此,最合适的方法还是使用布隆过滤器。
粗暴方式伪代码:
public object GetProductListNew() {
int cacheTime = 30;
String cacheKey = "product_list";
String cacheValue = CacheHelper.Get(cacheKey);
if (cacheValue != null) {
return cacheValue;
} else {
//数据库查询不到,为空
cacheValue = GetProductListFromDB();
if (cacheValue == null) {
//如果发现为空,设置个默认值,也缓存起来
cacheValue = string.Empty;
}
CacheHelper.Add(cacheKey, cacheValue, cacheTime);
return cacheValue;
}
}
2、缓存击穿解决方案
key可能会在某些时间点被超高并发地访问,是一种非常“热点”的数据。这个时候,需要考虑一个问题:缓存被“击穿”的问题。有一种解决方法是将热点数据的过期时间设置的长一点,或者设置为永不过期。另一种解决方法是使用互斥锁mutex。
业界比较常用的做法,是使用互斥锁(mutex key)。简单来说,就是在缓存失效的时候(判断拿出来的值为空),不是立即去load db,而是先使用缓存工具的某些带成功操作返回值的操作(比如Redis的SETNX或者Memcache的ADD)去set一个mutex key,当操作返回成功时,再进行load db的操作并回设缓存;否则,就重试整个get缓存的方法。
SETNX,是「SET if Not eXists」的缩写,也就是只有不存在的时候才设置,可以利用它来实现锁的效果。setnx(key,value,timeout)方法表示当key不存在时,给key设置value值,同时给key设置超时时间timeout,设置成功就返回1,否则key已存在时返回0(这一点与ReentrantLock获取锁时通过设置state属性的值是一个道理,若某个线程通过CAS操作将state的值从0改为了1,说明该线程获取到了锁)。为什么要设置超时时间?如果没有设置超时时间,某个线程获取锁后到最终释放锁需要经历从数据库加载数据并存放到redis中,若在释放锁之前该线程挂掉了,就无法释放锁。即使该线程在挂掉之前将数据缓存到redis中,数据总有过期的时候,等到数据过期了,其他线程就会尝试获取锁,然后从数据库获取数据并放到redis中。但是由于该线程在释放锁之前就挂掉了,一直没有释放锁,所以其他所有线程都会被阻塞,无法加载数据放到缓存中。因此需要设置超时时间。
Redis伪代码:
public String get(key) {
//从redis缓存中获取值
String value = redis.get(key);
if (value == null) { //代表缓存中没有该值,或者缓存值过期
//设置超时是为了防止线程在释放锁之前挂掉,而缓存过期后其他线程无法获取锁
if (redis.setnx(key_mutex, 1, 3 * 60) == 1) { //代表设置成功
//从数据库获取数据需要时间,如果线程在此处挂掉了,超时时间到了就会自动释放锁
value = db.get(key);
redis.set(key, value, expire_secs);
redis.del(key_mutex); //释放锁
} else {
//某个线程执行这段代码,说明有其他线程通过setnx获取到了锁,
//在查询数据库并将数据回写缓存,此时重试获取缓存值即可
sleep(50);
get(key); //重试,递归调用
}
} else {
return value; //缓存值没有过期,则直接返回
}
}
3、缓存雪崩解决方案
与缓存击穿的区别在于:缓存雪崩是针对很多key缓存同时过期,缓存击穿是某一个key过期导致的。对于缓存雪崩可以使用以下方法解决:
1、设置热点数据永远不过期。
2、缓存数据的过期时间设置随机,防止同一时间大量数据过期现象发生。
3、加锁或使用队列让多个线程排队请求
加锁排队,伪代码如下:
public object GetProductListNew() {
int cacheTime = 30;
String cacheKey = "product_list";
String lockKey = cacheKey;
String cacheValue = CacheHelper.get(cacheKey);
if (cacheValue != null) {
return cacheValue;
} else {
synchronized(lockKey) { //可能多个线程同时阻塞在这里
cacheValue = CacheHelper.get(cacheKey);
if (cacheValue != null) {
return cacheValue;
} else {
//这里一般是sql查询数据
cacheValue = GetProductListFromDB();
CacheHelper.Add(cacheKey, cacheValue, cacheTime);
}
}
return cacheValue;
}
}
加锁排队只是为了减轻数据库的压力,并没有提高系统吞吐量。假设在高并发下,缓存重建期间key是锁着的,这时过来1000个请求,999个都在阻塞的。同样会导致用户等待超时,这是个治标不治本的方法!线程被阻塞,用户体验很差!因此,在真正的高并发场景下很少使用!
4、布隆过滤器的原理和实现
布隆过滤器(Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都比一般的算法要好得多,缺点是有一定的误识别率和删除困难。
布隆过滤器本质上是一种数据结构,比较巧妙的概率型数据结构(probabilistic data structure),特点是高效地插入和查询,可以用来判断 “某样东西一定不存在或者可能存在”。相比于传统的 List、Set、Map 等数据结构,它更高效、占用空间更少,但是缺点是其返回的结果是概率性的,而不是确切的。
在什么场景下需要使用布隆过滤器呢?
当判断一个元素是否存在一个集合中,尤其当集合中的数据量特别大时,就非常适合使用布隆过滤器。
例如,从1000万条记录甚至1亿条记录中判断某条数据记录是否存在,这个时候常规的数据结构的问题就凸显出来了。数组、链表、树等数据结构会存储元素的内容,一旦数据量过大,消耗的内存也会呈现线性增长,最终达到瓶颈。虽然哈希表查询效率可以达到O(1),但是哈希表需要消耗的内存依然很高。假如使用哈希表存储一亿个垃圾 email 地址,哈希表的做法:哈希函数将一个email地址映射成8字节信息指纹,考虑到哈希表存储效率通常小于50%(哈希冲突),因此消耗的内存是8 * 2 * 1亿 字节 = 1.6G,普通计算机是无法提供如此大的内存。这个时候,布隆过滤器(Bloom Filter)就应运而生。
在介绍布隆过滤器之前,先简单了解一下哈希函数。
哈希函数的概念是:将任意大小的数据转换成特定大小的数据的函数,转换后的数据称为哈希值或哈希编码。下面是一幅示意图:
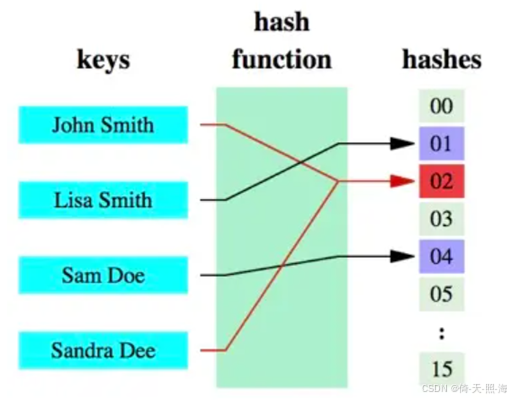
可以看到,原始数据经过哈希函数的映射后变成了一个个的哈希编码,数据得到压缩。哈希函数是实现哈希表和布隆过滤器的基础。
布隆过滤器原理和简单实现
布隆过滤器(Bloom Filter)的核心实现是一个超大的位数组和几个哈希函数。假设位数组的长度为m,哈希函数的个数为k。

以上图为例,具体的操作流程:假设集合里面有3个元素{x, y, z},哈希函数的个数为3。首先将位数组进行初始化,将里面每个位都设置为0。对于集合里面的每一个元素,将元素依次通过3个哈希函数进行映射,每次映射都会产生一个哈希值,这个值对应数组上面的一个点,然后将位数组对应的位置标记为1。当查询w元素是否存在集合中时,同样的方法将w通过3个哈希函数分别映射到位数组上的3个点。如果3个点中有一个点不为1,则可以判断w元素一定不存在集合中。反之,如果3个点都为1,则该元素可能存在集合中。注意:此处不能判断该元素是否一定存在集合中,可能存在一定的误判率。从图中可以看到:假设某个元素通过映射对应下标为4,5,6这3个点。虽然这3个点都为1,但是很明显这3个点是不同元素经过哈希得到的位置,因此这种情况说明元素虽然不在集合中,也可能对应的都是1,这是误判率存在的原因。
添加元素:将要添加的元素给k个哈希函数,得到对应于位数组上的k个位置,将这k个位置设为1。
查询元素:将要查询的元素给k个哈希函数,得到对应于位数组上的k个位置,如果k个位置有一个为0,则肯定不在集合中,如果k个位置全部为1,则可能在集合中。
import java.util.BitSet;
public class SimpleBloomFilter {
private static final int DEFAULT_SIZE = 2 << 24;
private static final int[] seeds = new int[] {7, 11, 13, 31, 37, 61,};
private BitSet bits = new BitSet(DEFAULT_SIZE);
private SimpleHash[] func = new SimpleHash[seeds.length];
public static void main(String[] args) {
String value = "125162136@qq.com";
SimpleBloomFilter filter = new SimpleBloomFilter();
System.out.println(filter.contains(value));
filter.add(value);
System.out.println(filter.contains(value));
}
public SimpleBloomFilter() {
for (int i = 0; i < seeds.length; i++) {
func[i] = new SimpleHash(DEFAULT_SIZE, seeds[i]);
}
}
public void add(String value) {
for (SimpleHash f : func) {
bits.set(f.hash(value), true);
}
}
public boolean contains(String value) {
if (value == null) {
return false;
}
boolean ret = true;
for (SimpleHash f : func) {
ret = ret && bits.get(f.hash(value));
}
return ret;
}
public static class SimpleHash {
private int cap;
private int seed;
public SimpleHash(int cap, int seed) {
this.cap = cap;
this.seed = seed;
}
public int hash(String value) {
int result = 0;
int len = value.length();
for (int i = 0; i < len; i++) {
result = seed * result + value.charAt(i);
}
return (cap - 1) & result;
}
}
}

















 4309
4309

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









