



ai瞎起的标题名字······
第一次尝试一下Star法则来写笔记:
1. 随着项目微服务化/容器化,日志分散在各个docker容器,一旦报错排查起来效率低
2.状态黑盒,各种指标:线程池状态,JVM堆内存等等都观测不到,出现“慢接口”(这里指的是一个或多个处理用户请求的 API(Application Programming Interface)或服务接口,其响应时间(延迟)显著高于预期的性能阈值,从而导致用户体验下降或系统资源被长时间占用。)时无法判断是GC,网络还是DB问题
3. ai缺乏运行时的上下文,无法给出更深层次的建议
1. 构建一套全链路可观测性平台,实现日志聚合检索、指标监控报警和链路追踪。
2. 引入 MCP Server,打通 IDE/AI 与项目运行时数据的壁垒,提升研发排查效率。
3. 确保监控组件本身轻量化,不影响核心交易链路的性能。
该怎么做呢?
日志架构:先搭建了ELK (Elasticsearch, Logstash, Kibana) 栈。配置 Logstash 管道,将业务应用的 Logback 输出通过 TCP/Socket 异步发送至 Logstash,最终落库 ES。
logstash.conf
input {
tcp {
mode => "server"
host => "0.0.0.0"
port => 4560
codec => json_lines
}
}
logback-spring.xml
<?xml version="1.0" encoding="UTF-8"?>
<···省略···>
<!-- 上报日志;ELK -->
<springProperty name="LOG_STASH_HOST" scope="context" source="logstash.host" defaultValue="127.0.0.1"/>
<!--输出到logstash的appender-->
<appender name="LOGSTASH" class="net.logstash.logback.appender.LogstashTcpSocketAppender">
<!--可以访问的logstash日志收集端口-->
<destination>${LOG_STASH_HOST}:4560</destination>
<encoder charset="UTF-8" class="net.logstash.logback.encoder.LogstashEncoder"/>
</appender>
<root level="info">
<···省略···>
<!-- 上报日志-ELK -->
<appender-ref ref="LOGSTASH"/>
</root>
</configuration>
监控架构: 部署 Prometheus + Grafana。(这个暂时没配置好,应该搞多几组压测)
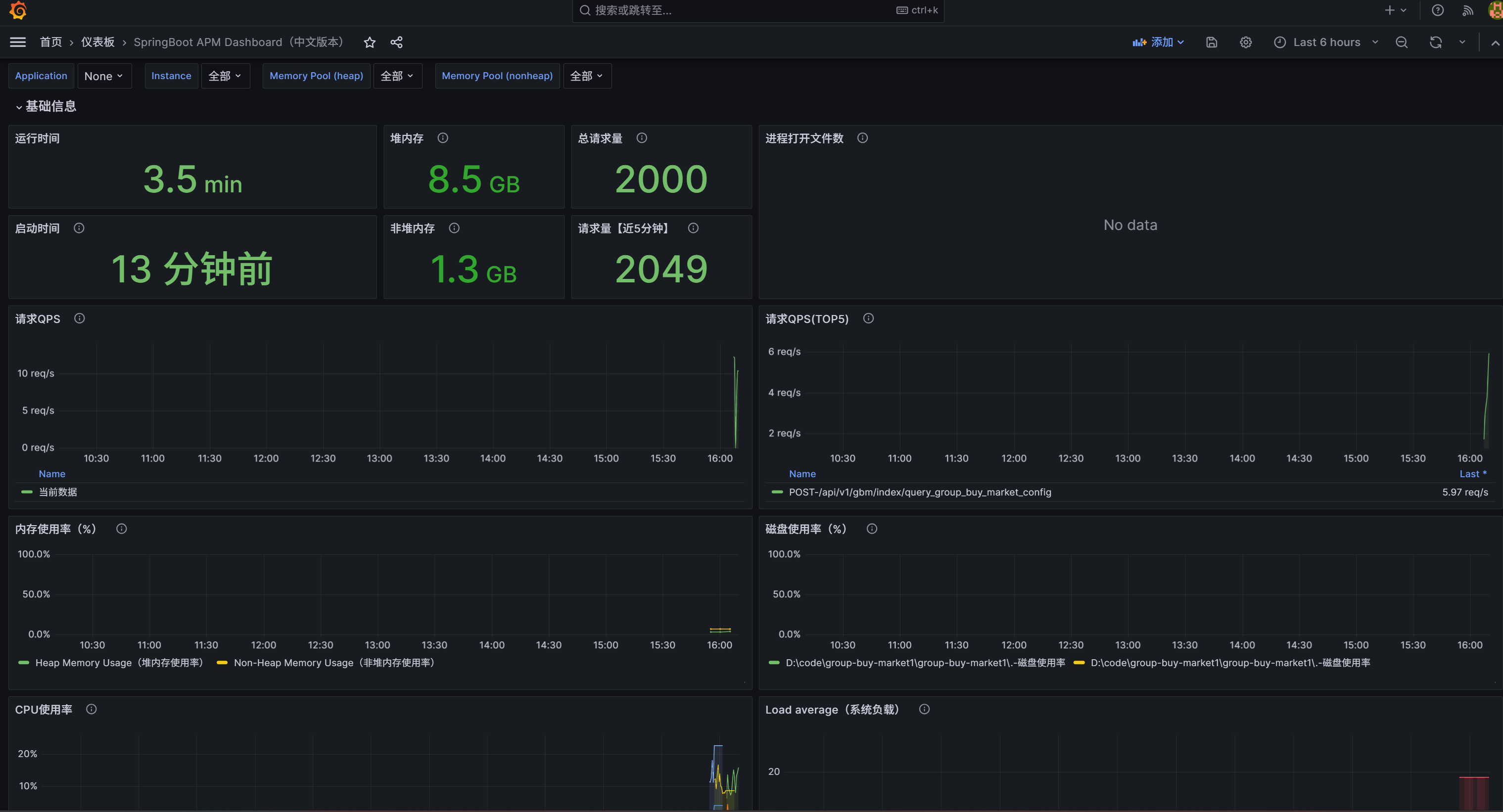

AI 增强: 部署并配置 MCP Server,使其能够读取本地日志文件、数据库 和 Prometheus 指标,允许 AI Agent 直接查询“当前系统报错最多的异常是什么”
(这个暂未上报)

Bug 定位时间缩短,实现了对 JVM GC 次数、接口 P99 延迟的实时监控。其他有点偏运维

















 952
952

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









