



 本文探讨了一种将配置直接以类型安全的方式融入源代码的方法,使用Scala语言作为示例。配置随软件演进,通过版本管理和编译时验证提高系统的一致性和可靠性。编译配置提供了静态的、易于测试和版本控制的系统配置,但也存在如静态配置不灵活、编译需求等缺点。该方法适用于替换XML等文本配置,可扩展到其他可编译语言,并可通过DSL增强用户体验。
本文探讨了一种将配置直接以类型安全的方式融入源代码的方法,使用Scala语言作为示例。配置随软件演进,通过版本管理和编译时验证提高系统的一致性和可靠性。编译配置提供了静态的、易于测试和版本控制的系统配置,但也存在如静态配置不灵活、编译需求等缺点。该方法适用于替换XML等文本配置,可扩展到其他可编译语言,并可通过DSL增强用户体验。
分布式编译
In this post we'd like to share an interesting way of dealing with configuration of a distributed system. The configuration is represented directly in Scala language in a type safe manner. An example implementation is described in details. Various aspects of the proposal are discussed, including influence on the overall development process.
在本文中,我们希望分享一种有趣的方式来处理分布式系统的配置。 该配置以一种类型安全的方式直接用Scala语言表示。 详细描述示例实现。 讨论了提案的各个方面,包括对整个开发过程的影响。
( нарусском )
介绍 (Introduction)
Building robust distributed systems requires the use of correct and coherent configuration on all nodes. A typical solution is to use a textual deployment description (terraform, ansible or something alike) and automatically generated configuration files (often — dedicated for each node/role). We would also want to use the same protocols of the same versions on each communicating nodes (otherwise we would experience incompatibility issues). In JVM world this means that at least the messaging library should be of the same version on all communicating nodes.
构建健壮的分布式系统需要在所有节点上使用正确且一致的配置。 一个典型的解决方案是使用文本部署描述(terraform,ansible或类似内容)和自动生成的配置文件(通常-每个节点/角色专用)。 我们还希望在每个通信节点上使用相同版本的相同协议(否则我们将遇到不兼容问题)。 在JVM世界中,这意味着在所有通信节点上至少消息传递库应具有相同的版本。
What about testing the system? Of course, we should have unit tests for all components before coming to integration tests. To be able to extrapolate test results on runtime, we should make sure that the versions of all libraries are kept identical in both runtime and testing environments.
那测试系统呢? 当然,在进行集成测试之前,我们应该对所有组件进行单元测试。 为了能够在运行时推断测试结果,我们应该确保在运行时和测试环境中所有库的版本保持相同。
When running integration tests, it's often much easier to have the same classpath on all nodes. We just need to make sure that the same classpath is used on deployment. (It is possible to use different classpaths on different nodes, but it's more difficult to represent this configuration and correctly deploy it.) So in order to keep things simple we will only consider identical classpaths on all nodes.
运行集成测试时,在所有节点上具有相同的类路径通常会容易得多。 我们只需要确保在部署中使用相同的类路径即可。 (可以在不同的节点上使用不同的类路径,但是要表示此配置并正确部署它更困难。)因此,为了使事情变得简单,我们仅在所有节点上考虑相同的类路径。
Configuration tends to evolve together with the software. We usually use versions to identify various stages of software evolution. It seems reasonable to cover configuration under version management and identify different configurations with some labels. If there is only one configuration in production, we may use single version as an identifier. Sometimes we may have multiple production environments. And for each environment we might need a separate branch of configuration. So configurations might be labeled with branch and version to uniquely identify different configurations. Each branch label and version corresponds to a single combination of distributed nodes, ports, external resources, classpath library versions on each node. Here we'll only cover the single branch and identify configurations by a three component decimal version (1.2.3), in the same way as other artifacts.
配置倾向于与软件一起发展。 我们通常使用版本来识别软件演进的各个阶段。 在版本管理下覆盖配置并用一些标签标识不同的配置似乎是合理的。 如果生产中只有一种配置,我们可以使用单一版本作为标识符。 有时我们可能有多个生产环境。 对于每种环境,我们可能需要一个单独的配置分支。 因此,配置可能会标有分支和版本,以唯一地标识不同的配置。 每个分支标签和版本对应于每个节点上的分布式节点,端口,外部资源和类路径库版本的单个组合。 在这里,我们将仅覆盖单个分支,并以与其他工件相同的方式,通过三部分十进制版本(1.2.3)识别配置。
In modern environments configuration files are not modified manually anymore. Typically we generate config files at deployment time and never touch them afterwards. So one could ask why do we still use text format for configuration files? A viable option is to place the configuration inside a compilation unit and benefit from compile-time configuration validation.
在现代环境中,不再手动修改配置文件。 通常,我们在部署时生成配置文件,以后再也不会碰它们 。 所以有人会问为什么我们仍然对配置文件使用文本格式? 一个可行的选择是将配置放置在编译单元中,并从编译时配置验证中受益。
In this post we will examine the idea of keeping the configuration in the compiled artifact.
在本文中,我们将研究将配置保留在已编译工件中的想法。
编译配置 (Compilable configuration)
In this section we will discuss an example of static configuration. Two simple services — echo service and the client of the echo service are being configured and implemented. Then two different distributed systems with both services are instantiated. One is for a single node configuration and another one for two nodes configuration.
在本节中,我们将讨论静态配置的示例。 正在配置和实现两个简单的服务-回声服务和回声服务的客户端。 然后,实例化具有两种服务的两个不同的分布式系统。 一个用于单节点配置,另一个用于两个节点配置。
A typical distributed system consists of a few nodes. The nodes could be identified using some type:
典型的分布式系统由几个节点组成。 可以使用某些类型来标识节点:
sealed trait NodeId
case object Backend extends NodeId
case object Frontend extends NodeIdor just
要不就
case class NodeId(hostName: String)or even
甚至
object Singleton
type NodeId = Singleton.typeThese nodes perform various roles, run some services and should be able to communicate with the other nodes by means of TCP/HTTP connections.
这些节点执行各种角色,运行某些服务,并且应该能够通过TCP / HTTP连接与其他节点通信。
For TCP connection at least a port number is required. We also want to make sure that client and server are talking the same protocol. In order to model a connection between nodes let's declare the following class:
对于TCP连接,至少需要一个端口号。 我们还想确保客户端和服务器正在使用相同的协议。 为了对节点之间的连接建模,让我们声明以下类:
case class TcpEndPoint[Protocol](node: NodeId, port: Port[Protocol])where Port is just an Int within the allowed range:
其中Port只是允许范围内的Int :
type PortNumber = Refined[Int, Closed[_0, W.`65535`.T]]See refined library. In short, it allows to add compile time constraints to other types. In this case Int is only allowed to have 16-bit values that can represent port number. There is no requirement to use this library for this configuration approach. It just seems to fit very well.
请参阅精炼库。 简而言之,它允许将编译时间约束添加到其他类型。 在这种情况下,仅允许Int具有可表示端口号的16位值。 无需将此库用于此配置方法。 看起来非常合适。
For HTTP (REST) we might also need a path of the service:
对于HTTP(REST),我们可能还需要服务的路径:
type UrlPathPrefix = Refined[String, MatchesRegex[W.`"[a-zA-Z_0-9/]*"`.T]]
case class PortWithPrefix[Protocol](portNumber: PortNumber, pathPrefix: UrlPathPrefix)In order to identify protocol during compilation we are using the Scala feature of declaring type argument Protocol that is not used in the class. It's a so called phantom type. At runtime we rarely need an instance of protocol identifier, that's why we don't store it. During compilation this phantom type gives additional type safety. We cannot pass port with incorrect protocol.
为了在编译期间识别协议,我们使用了Scala功能,该功能声明了类中未使用的类型实参Protocol 。 这就是所谓的幻影类型 。 在运行时,我们很少需要协议标识符的实例,这就是为什么我们不存储它的原因。 在编译期间,此幻像类型提供了附加的类型安全性。 我们无法使用错误的协议传递端口。
One of the most widely used protocols is REST API with Json serialization:
使用Json序列化的REST API是最广泛使用的协议之一:
sealed trait JsonHttpRestProtocol[RequestMessage, ResponseMessage]where RequestMessage is the base type of messages that client can send to server and ResponseMessage is the response message from server. Of course, we may create other protocol descriptions that specify the communication protocol with the desired precision.
其中RequestMessage是客户端可以发送到服务器的消息的基本类型, ResponseMessage是来自服务器的响应消息。 当然,我们可以创建其他协议描述,这些协议描述以所需的精度指定通信协议。
For the purposes of this post we'll use a simpler version of the protocol:
出于本文的目的,我们将使用该协议的更简单版本:
sealed trait SimpleHttpGetRest[RequestMessage, ResponseMessage]In this protocol request message is appended to url and response message is returned as plain string.
在此协议中,请求消息附加到url,响应消息作为纯字符串返回。
A service configuration could be described by the service name, a collection of ports and some dependencies. There are a few possible ways of how to represent all these elements in Scala (for instance, HList, algebraic data types). For the purposes of this post we'll use Cake Pattern and represent combinable pieces (modules) as traits. (Cake Pattern is not a requirement for this compilable configuration approach. It just one possible implementation of the idea.)
服务配置可以通过服务名称,端口集合和某些依赖项来描述。 有几种方法可以表示Scala中的所有这些元素(例如HList ,代数数据类型)。 出于本文的目的,我们将使用Cake Pattern并将可组合的块(模块)表示为特征。 (Cake Pattern不是这种可编译配置方法的要求。它只是该思想的一种可能实现。)
Dependencies could be represented using the Cake Pattern as endpoints of other nodes:
可以使用Cake Pattern作为其他节点的端点来表示依赖关系:
type EchoProtocol[A] = SimpleHttpGetRest[A, A]
trait EchoConfig[A] extends ServiceConfig {
def portNumber: PortNumber = 8081
def echoPort: PortWithPrefix[EchoProtocol[A]] = PortWithPrefix[EchoProtocol[A]](portNumber, "echo")
def echoService: HttpSimpleGetEndPoint[NodeId, EchoProtocol[A]] = providedSimpleService(echoPort)
}Echo service only needs a port configured. And we declare that this port supports echo protocol. Note that we do not need to specify a particular port at this moment, because trait's allows abstract methods declarations. If we use abstract methods, compiler will require an implementation in a configuration instance. Here we have provided the implementation (8081) and it will be used as the default value if we skip it in a concrete configuration.
回声服务仅需要配置一个端口。 并且我们声明此端口支持echo协议。 请注意,我们此时无需指定特定端口,因为trait允许抽象方法声明。 如果使用抽象方法,则编译器将需要在配置实例中实现。 在这里,我们提供了实现( 8081 ),如果在具体配置中跳过它,它将用作默认值。
We can declare a dependency in the configuration of the echo service client:
我们可以在echo服务客户端的配置中声明一个依赖项:
trait EchoClientConfig[A] {
def testMessage: String = "test"
def pollInterval: FiniteDuration
def echoServiceDependency: HttpSimpleGetEndPoint[_, EchoProtocol[A]]
}Dependency has the same type as the echoService. In particular, it demands the same protocol. Hence, we can be sure that if we connect these two dependencies they will work correctly.
依赖项与echoService具有相同的类型。 特别是,它需要相同的协议。 因此,我们可以确定,如果我们连接这两个依赖关系,它们将正常工作。
A service needs a function to start and gracefully shutdown. (Ability to shutdown a service is critical for testing.) Again there are a few options of specifying such a function for a given config (for instance, we could use type classes). For this post we'll again use Cake Pattern. We can represent a service using cats.Resource which already provides bracketing and resource release. In order to acquire a resource we should provide a configuration and some runtime context. So the service starting function might look like:
服务需要启动和正常关闭的功能。 (关闭服务的能力对于测试至关重要。)同样,有一些选项可以为给定的配置指定这样的功能(例如,我们可以使用类型类)。 在这篇文章中,我们将再次使用Cake Pattern。 我们可以使用cats.Resource表示服务,该服务已经提供了包围和资源释放。 为了获得资源,我们应该提供配置和一些运行时上下文。 因此,服务启动功能可能类似于:
type ResourceReader[F[_], Config, A] = Reader[Config, Resource[F, A]]
trait ServiceImpl[F[_]] {
type Config
def resource(
implicit
resolver: AddressResolver[F],
timer: Timer[F],
contextShift: ContextShift[F],
ec: ExecutionContext,
applicative: Applicative[F]
): ResourceReader[F, Config, Unit]
}where
哪里
Config— type of configuration that is required by this service starterConfig此服务启动程序所需的配置类型AddressResolver— a runtime object that has the ability to obtain real addresses of other nodes (keep reading for details).AddressResolver—运行时对象,能够获取其他节点的真实地址(请继续阅读以获取详细信息)。
the other types comes from cats:
其他类型则来自cats :
F[_]— effect type (In the simplest caseF[A]could be just() => A. In this post we'll usecats.IO.)F[_]—效果类型(在最简单的情况下,F[A]可能只是() => A在本文中,我们将使用cats.IO)Reader[A,B]— is more or less a synonym for a functionA => BReader[A,B]—或多或少是函数A => B的同义词A => Bcats.Resource— has ways to acquire and releasecats.Resource具有获取和释放的方法Timer— allows to sleep/measure timeTimer-允许睡眠/测量时间ContextShift— analog ofExecutionContextContextShift—类似ExecutionContextApplicative— wrapper of functions in effect (almost a monad) (we might eventually replace it with something else)Applicative-有效的函数包装器(几乎是monad)(我们最终可能会用其他东西代替它)
Using this interface we can implement a few services. For instance, a service that does nothing:
使用此接口,我们可以实现一些服务。 例如,什么都不做的服务:
trait ZeroServiceImpl[F[_]] extends ServiceImpl[F] {
type Config <: Any
def resource(...): ResourceReader[F, Config, Unit] =
Reader(_ => Resource.pure[F, Unit](()))
}(See Source code for other services implementations — echo service, echo client and lifetime controllers.)
(请参阅其他服务实现的源代码 -echo服务 , echo客户端和生存期控制器 。)
A node is a single object that runs a few services (starting a chain of resources is enabled by Cake Pattern):
节点是运行几个服务的单个对象(通过Cake Pattern启用启动资源链):
object SingleNodeImpl extends ZeroServiceImpl[IO]
with EchoServiceService
with EchoClientService
with FiniteDurationLifecycleServiceImpl
{
type Config = EchoConfig[String] with EchoClientConfig[String] with FiniteDurationLifecycleConfig
}Note that in the node we specify the exact type of configuration that is needed by this node. Compiler won't let us to build the object (Cake) with insufficient type, because each service trait declares a constraint on the Config type. Also we won't be able to start node without providing complete configuration.
注意,在节点中,我们指定此节点所需的确切配置类型。 编译器不会让我们构建类型不足的对象(Cake),因为每个服务特征都声明了对Config类型的约束。 同样,如果不提供完整的配置,我们将无法启动节点。
In order to establish a connection we need a real host address for each node. It might be known later than other parts of the configuration. Hence, we need a way to supply a mapping between node id and it's actual address. This mapping is a function:
为了建立连接,我们需要每个节点的真实主机地址。 可能比配置的其他部分晚。 因此,我们需要一种在节点ID和它的实际地址之间提供映射的方法。 此映射是一个功能:
case class NodeAddress[NodeId](host: Uri.Host)
trait AddressResolver[F[_]] {
def resolve[NodeId](nodeId: NodeId): F[NodeAddress[NodeId]]
}There are a few possible ways to implement such a function.
有几种可能的方法可以实现这种功能。
If we know actual addresses before deployment, during node hosts instantiation, then we can generate Scala code with the actual addresses and run the build afterwards (which performs compile time checks and then runs integration test suite). In this case our mapping function is known statically and can be simplified to something like a
Map[NodeId, NodeAddress].如果我们在部署前知道实际地址,则在节点主机实例化期间,我们可以使用实际地址生成Scala代码,然后运行构建(执行编译时检查,然后运行集成测试套件)。 在这种情况下,我们的映射功能是静态已知的,可以简化为
Map[NodeId, NodeAddress]。- Sometimes we obtain actual addresses only at a later point when the node is actually started, or we don't have addresses of nodes that haven't been started yet. In this case we might have a discovery service that is started before all other nodes and each node might advertise it's address in that service and subscribe to dependencies. 有时,我们仅在节点实际启动时才获取实际地址,或者我们没有尚未启动的节点的地址。 在这种情况下,我们可能有一个发现服务,该服务在所有其他节点之前启动,并且每个节点可能会在该服务中通告其地址并订阅依赖项。
If we can modify
/etc/hosts, we can use predefined host names (likemy-project-main-nodeandecho-backend) and just associate this name with ip address at deployment time.如果可以修改
/etc/hosts,则可以使用预定义的主机名(例如my-project-main-node和echo-backend),只需在部署时将此名称与ip地址关联即可。
In this post we don't cover these cases in more details. In fact in our toy example all nodes will have the same IP address — 127.0.0.1.
在这篇文章中,我们不会更详细地介绍这些情况。 实际上,在我们的玩具示例中,所有节点都将具有相同的IP地址— 127.0.0.1 。
In this post we'll consider two distributed system layouts:
在本文中,我们将考虑两种分布式系统布局:
- Single node layout, where all services are placed on the single node. 单节点布局,其中所有服务都放置在单个节点上。
- Two node layout, where service and client are on different nodes. 两节点布局,其中服务和客户端位于不同的节点上。
The configuration for a single node layout is as follows:
单节点布局的配置如下:
object SingleNodeConfig extends EchoConfig[String]
with EchoClientConfig[String] with FiniteDurationLifecycleConfig
{
case object Singleton // identifier of the single node
// configuration of server
type NodeId = Singleton.type
def nodeId = Singleton
/** Type safe service port specification. */
override def portNumber: PortNumber = 8088
// configuration of client
/** We'll use the service provided by the same host. */
def echoServiceDependency = echoService
override def testMessage: UrlPathElement = "hello"
def pollInterval: FiniteDuration = 1.second
// lifecycle controller configuration
def lifetime: FiniteDuration = 10500.milliseconds // additional 0.5 seconds so that there are 10 requests, not 9.
}Here we create a single configuration that extends both server and client configuration. Also we configure a lifecycle controller that will normally terminate client and server after lifetime interval passes.
在这里,我们创建一个扩展服务器和客户端配置的配置。 我们还配置了一个生命周期控制器,该控制器通常会在lifetime间隔过去后终止客户端和服务器。
The same set of service implementations and configurations can be used to create a system's layout with two separate nodes. We just need to create two separate node configs with the appropriate services:
可以使用同一组服务实现和配置来创建具有两个单独节点的系统布局。 我们只需要使用适当的服务创建两个单独的节点配置 :
object NodeServerConfig extends EchoConfig[String] with SigTermLifecycleConfig
{
type NodeId = NodeIdImpl
def nodeId = NodeServer
override def portNumber: PortNumber = 8080
}
object NodeClientConfig extends EchoClientConfig[String] with FiniteDurationLifecycleConfig
{
// NB! dependency specification
def echoServiceDependency = NodeServerConfig.echoService
def pollInterval: FiniteDuration = 1.second
def lifetime: FiniteDuration = 10500.milliseconds // additional 0.5 seconds so that there are 10 request, not 9.
def testMessage: String = "dolly"
}See how we specify the dependency. We mention the other node's provided service as a dependency of the current node. The type of dependency is checked because it contains phantom type that describes protocol. And at runtime we'll have the correct node id. This is one of the important aspects of the proposed configuration approach. It provides us with the ability to set port only once and make sure that we are referencing the correct port.
看看我们如何指定依赖关系。 我们将另一个节点提供的服务称为当前节点的依存关系。 因为依赖项包含描述协议的幻像类型,所以检查了依赖项的类型。 在运行时,我们将获得正确的节点ID。 这是建议的配置方法的重要方面之一。 它使我们能够只设置一次端口,并确保引用了正确的端口。
For this configuration we use exactly the same services implementations. No changes at all. However, we create two different node implementations that contain different set of services:
对于此配置,我们使用完全相同的服务实现。 完全没有变化。 但是,我们创建了两个包含不同服务集的不同节点实现:
object TwoJvmNodeServerImpl extends ZeroServiceImpl[IO] with EchoServiceService with SigIntLifecycleServiceImpl {
type Config = EchoConfig[String] with SigTermLifecycleConfig
}
object TwoJvmNodeClientImpl extends ZeroServiceImpl[IO] with EchoClientService with FiniteDurationLifecycleServiceImpl {
type Config = EchoClientConfig[String] with FiniteDurationLifecycleConfig
}The first node implements server and it only needs server side config. The second node implements client and needs another part of config. Both nodes require some lifetime specification. For the purposes of this post service node will have infinite lifetime that could be terminated using SIGTERM, while echo client will terminate after the configured finite duration. See the starter application for details.
第一个节点实现服务器,并且只需要服务器端配置。 第二个节点实现客户端,并且需要配置的另一部分。 两个节点都需要一些生命周期规范。 出于此目的,此服务节点将具有无限生存期,可以使用SIGTERM终止此生命周期,而echo客户端将在配置的有限持续时间后终止。 有关详细信息,请参见入门应用程序 。
总体发展过程 (Overall development process)
Let's see how this approach changes the way we work with configuration.
让我们看看这种方法如何改变我们的配置工作方式。
The configuration as code will be compiled and produces an artifact. It seems reasonable to separate configuration artifact from other code artifacts. Often we can have multitude of configurations on the same code base. And of course, we can have multiple versions of various configuration branches. In a configuration we can select particular versions of libraries and this will remain constant whenever we deploy this configuration.
作为代码的配置将被编译并产生工件。 将配置工件与其他代码工件分开似乎是合理的。 通常,我们可以在同一代码库上进行多种配置。 当然,我们可以具有各种配置分支的多个版本。 在配置中,我们可以选择特定版本的库,并且在部署此配置时,它将保持不变。
A configuration change becomes code change. So it should be covered by the same quality assurance process:
配置更改变为代码更改。 因此,它应该包含在相同的质量保证过程中:
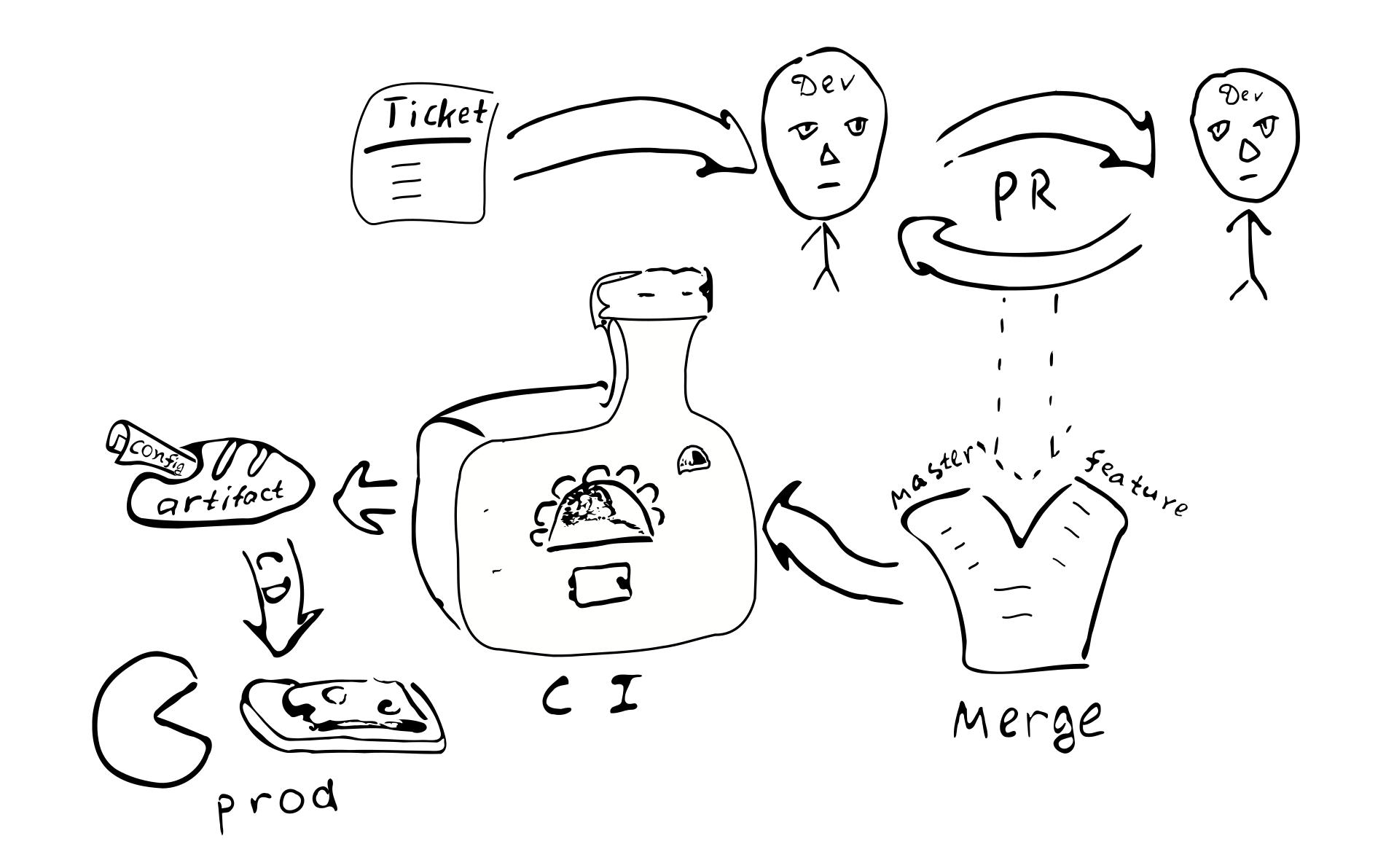
Ticket -> PR -> review -> merge -> continuous integration -> continuous deployment
工单->公关->评论->合并->持续集成->持续部署
There are the following consequences of the approach:
该方法具有以下后果:
The configuration is coherent for a particular system's instance. It seems that there is no way to have incorrect connection between nodes.
该配置对于特定系统的实例是一致的。 似乎没有办法在节点之间建立不正确的连接。
It's not easy to change configuration just in one node. It seems unreasonable to log in and change some text files. So configuration drift becomes less possible.
仅在一个节点上更改配置并不容易。 登录并更改一些文本文件似乎是不合理的。 因此,配置漂移变得不太可能。
Small configuration changes are not easy to make.
较小的配置更改不容易进行。
Most of the configuration changes will follow the same development process, and it will pass some review.
大多数配置更改将遵循相同的开发过程,并且将通过一些审查。
Do we need a separate repository for production configuration? The production configuration might contain sensitive information that we would like to keep out of reach of many people. So it might worth keeping a separate repository with restricted access that will contain the production configuration. We may split the configuration into two parts — one that contains most open parameters of production and one that contains the secret part of configuration. This would enable access to most of the developers to the vast majority of parameters while restricting access to really sensitive things. It's easy to accomplish this using intermediate traits with default parameter values.
我们需要用于生产配置的单独存储库吗? 生产配置可能包含敏感信息,而我们希望这些信息不会被许多人接触。 因此,可能值得保留一个包含生产配置的受限制访问权限的单独存储库。 我们可以将配置分为两部分-一部分包含大多数生产的开放参数,另一部分包含配置的秘密部分。 这将使大多数开发人员可以访问绝大多数参数,同时限制对真正敏感内容的访问。 使用带有默认参数值的中间特征来完成此操作很容易。
变化 (Variations)
Let's see pros and cons of the proposed approach compared to the other configuration management techniques.
让我们看看与其他配置管理技术相比,该方法的优缺点。
First of all, we'll list a few alternatives to the different aspects of the proposed way of dealing with configuration:
首先,我们将列出一些提议的配置方式的不同方面的替代方案:
- Text file on the target machine. 目标计算机上的文本文件。
Centralized key-value storage (like
etcd/zookeeper).集中式键值存储(例如
etcd/zookeeper)。- Subprocess components that could be reconfigured/restarted without restarting process. 无需重新启动流程即可重新配置/重新启动的子流程组件。
- Configuration outside artifact and version control. 在工件和版本控制之外进行配置。
Text file gives some flexibility in terms of ad-hoc fixes. A system's administrator can login to the target node, make a change and simply restart the service. This might not be as good for bigger systems. No traces are left behind the change. The change is not reviewed by another pair of eyes. It might be difficult to find out what have caused the change. It has not been tested. From distributed system's perspective an administrator can simply forget to update the configuration in one of the other nodes.
文本文件在临时修复方面具有一定的灵活性。 系统管理员可以登录到目标节点,进行更改,然后只需重新启动服务即可。 对于较大的系统,这可能不那么好。 更改后没有任何痕迹。 另一只眼睛没有审查此更改。 可能很难找出导致更改的原因。 尚未测试。 从分布式系统的角度来看,管理员可以简单地忘记更新其他节点之一中的配置。
(Btw, if eventually there will be a need to start using text config files, we'll only have to add parser + validator that could produce the same Config type and that would be enough to start using text configs. This also shows that the complexity of compile-time configuration is a little smaller that the complexity of text-based configs, because in text-based version we need some additional code.)
(顺便说一句,如果最终有必要开始使用文本配置文件,我们只需要添加解析器+验证器即可产生相同的Config类型,并且足以开始使用文本配置。这也表明编译时配置的复杂度比基于文本的配置的复杂度小一点,因为在基于文本的版本中,我们需要一些其他代码。)
Centralized key-value storage is a good mechanism for distributing application meta parameters. Here we need to think about what we consider to be configuration values and what is just data. Given a function C => A => B we usually call rarely changing values C "configuration", while frequently changed data A — just input data. Configuration should be provided to the function earlier than the data A. Given this idea we can say that it's expected frequency of changes what could be used to distinguish configuration data from just data. Also data typically comes from one source (user) and configuration comes from a different source (admin). Dealing with parameters that can be changed after process initialization leads to an increase of application complexity. For such parameters we'll have to handle their delivery mechanism, parsing and validation, handling incorrect values. Hence, in order to reduce program complexity, we'd better reduce the number of parameters that can change at runtime (or even eliminate them altogether).
集中式键值存储是一种用于分发应用程序元参数的良好机制。 在这里,我们需要考虑什么我们认为是配置值以及什么是数据。 给定一个函数C => A => B我们通常将很少更改的值C称为“配置”,而将频繁更改的数据A称为输入数据。 应该在数据A之前为功能提供配置。 有了这个想法,我们可以说预期的更改频率可以用来区分配置数据和数据。 同样,数据通常来自一个来源(用户),而配置则来自其他来源(管理员)。 处理在流程初始化后可以更改的参数会导致应用程序复杂性增加。 对于此类参数,我们将必须处理其传递机制,解析和验证,处理不正确的值。 因此,为了减少程序的复杂性,我们最好减少运行时可以更改的参数数量(甚至完全消除它们)。
From the perspective of this post we should make a distinction between static and dynamic parameters. If service logic requires rare change of some parameters at runtime, then we may call them dynamic parameters. Otherwise they are static and could be configured using the proposed approach. For dynamic reconfiguration other approaches might be needed. For example, parts of the system might be restarted with the new configuration parameters in a similar way to restarting separate processes of a distributed system. (My humble opinion is to avoid runtime reconfiguration because it increases complexity of the system. It' might be more straightforward to just rely on OS support of restarting processes. Though, it might not always be possible.)
从这篇文章的角度来看,我们应该区分静态参数和动态参数。 如果服务逻辑在运行时需要很少更改某些参数,那么我们可以将它们称为动态参数。 否则它们是静态的,可以使用建议的方法进行配置。 对于动态重新配置,可能需要其他方法。 例如,系统部分可以使用新的配置参数重新启动,类似于重新启动分布式系统的单独进程。 (我的愚见是避免重新配置运行时,因为这会增加系统的复杂性。仅依靠操作系统对重启进程的支持可能会更直接。尽管并非总是如此。)
One important aspect of using static configuration that sometimes makes people consider dynamic configuration (without other reasons) is service downtime during configuration update. Indeed, if we have to make changes to static configuration, we have to restart the system so that new values become effective. The requirements for downtime vary for different systems, so it might not be that critical. If it is critical, then we have to plan ahead for any system restarts. For instance, we could implement AWS ELB connection draining. In this scenario whenever we need to restart the system, we start a new instance of the system in parallel, then switch ELB to it, while letting the old system to complete servicing existing connections.
使用静态配置的一个重要方面(有时会导致人们考虑动态配置(无其他原因))是配置更新期间的服务停机时间。 确实,如果必须更改静态配置,则必须重新启动系统,以使新值生效。 停机时间要求因系统不同而异,因此并不是那么关键。 如果这很关键,那么我们必须为重新启动系统提前计划。 例如,我们可以实现AWS ELB连接耗尽 。 在这种情况下,无论何时需要重新启动系统,我们都会并行启动系统的新实例,然后将ELB切换到该实例,同时让旧系统完成对现有连接的服务。
What about keeping configuration inside versioned artifact or outside? Keeping configuration inside an artifact means in most of the cases that this configuration has passed the same quality assurance process as other artifacts. So one might be sure that the configuration is of good quality and trustworthy. On the contrary configuration in a separate file means that there are no traces of who and why made changes to that file. Is this important? We believe that for most production systems it's better to have stable and high quality configuration.
如何将配置保留在版本控制的工件内或外部? 将配置保留在工件中意味着在大多数情况下,此配置已通过与其他工件相同的质量保证过程。 因此,可以肯定的是,该配置质量良好且值得信赖。 相反,在一个单独的文件中进行配置意味着没有跟踪谁和为什么对该文件进行了更改的痕迹。 这重要吗? 我们认为,对于大多数生产系统而言,最好具有稳定和高质量的配置。
Version of the artifact allows to find out when it was created, what values it contains, what features are enabled/disabled, who was responsible for making each change in the configuration. It might require some effort to keep configuration inside an artifact and it's a design choice to make.
该工件的版本可以确定何时创建,包含哪些值,启用/禁用了哪些功能,由谁负责配置中的每项更改。 可能需要付出一些努力才能将配置保留在工件中,这是设计选择。
优点缺点 (Pros & cons)
Here we would like to highlight some advantages and to discuss some disadvantages of the proposed approach.
在这里,我们要强调一些优点,并讨论该方法的一些缺点。
优点 (Advantages)
Features of the compilable configuration of a complete distributed system:
完整的分布式系统的可编译配置的功能:
- Static check of configuration. This gives a high level of confidence, that the configuration is correct given type constraints. 静态检查配置。 在给定类型约束的情况下,此配置具有正确的置信度,因此具有很高的置信度。
Rich language of configuration. Typically other configuration approaches are limited to at most variable substitution.
丰富的配置语言。 通常,其他配置方法最多限于变量替换。
Using Scala one can use wide range of language features to make configuration better. For instance, we can use traits to provide default values, objects to set different scope, we can refer to
使用Scala可以使用多种语言功能来改善配置。 例如,我们可以使用traits提供默认值,使用对象设置不同的作用域,我们可以参考
vals defined only once in the outer scope (DRY). It's possible to use literal sequences, or instances of certain classes (Seq,Map, etc.).val在外部范围(DRY)中仅定义一次。 可以使用文字序列或某些类的实例(Seq,Map等)。- DSL. Scala has decent support for DSL writers. One can use these features to establish a configuration language that is more convenient and end-user friendly, so that the final configuration is at least readable by domain users. DSL。 Scala对DSL编写器提供了不错的支持。 可以使用这些功能来建立一种更方便和最终用户友好的配置语言,以便最终配置至少对域用户可读。
- Integrity and coherence across nodes. One of the benefits of having configuration for the whole distributed system in one place is that all values are defined strictly once and then reused in all places where we need them. Also type safe port declarations ensures that in all possible correct configurations the system's nodes will speak the same language. There are explicit dependencies between nodes which makes it hard to forget to provide some services. 跨节点的完整性和一致性。 在一个地方为整个分布式系统进行配置的好处之一是,仅严格定义一次所有值,然后在需要它们的所有地方重复使用。 同样,类型安全端口声明可确保在所有可能的正确配置中,系统节点将使用相同的语言。 节点之间存在明确的依赖关系,这使得很难忘记提供某些服务。
- High quality of changes. The overall approach of passing configuration changes through normal PR process establishes high standards of quality also in configuration. 高质量的变更。 通过正常的PR过程传递配置更改的总体方法在配置中也建立了高质量的标准。
- Simultaneous configuration changes. Whenever we make any changes in the configuration automatic deployment ensures that all nodes are being updated. 同时进行配置更改。 每当我们对配置进行任何更改时,自动部署都将确保所有节点都被更新。
- Application simplification. The application doesn't need to parse and validate configuration and handle incorrect configuration values. This simplifies the overall application. (Some complexity increase is in the configuration itself, but it's a conscious trade-off towards safety.) It's pretty straightforward to return to ordinary configuration — just add the missing pieces. It's easier to get started with compiled configuration and postpone implementation of additional pieces to some later times. 简化应用程序。 该应用程序不需要解析和验证配置,也不需要处理错误的配置值。 这简化了整个应用程序。 (配置本身会增加一些复杂性,但这是对安全性的自觉权衡。)返回普通配置非常简单,只需添加缺少的部分即可。 开始进行编译配置和将其他部分的实现推迟到以后的时间比较容易。
- Versioned configuration. Due to the fact that configuration changes follow the same development process, as a result we get an artifact with unique version. It allows us to switch configuration back if needed. We can even deploy a configuration that was used a year ago and it will work exactly the same way. Stable configuration improves predictability and reliability of the distributed system. The configuration is fixed at compile time and cannot be easily tampered on a production system. 版本化配置。 由于配置更改遵循相同的开发过程,因此我们获得了具有唯一版本的工件。 如果需要,它使我们可以将配置切换回去。 我们甚至可以部署一年前使用的配置,它的工作方式完全相同。 稳定的配置提高了分布式系统的可预测性和可靠性。 该配置在编译时是固定的,不能在生产系统上轻易篡改。
Modularity. The proposed framework is modular and modules could be combined in various ways to
模块化。 拟议的框架是模块化的,模块可以通过各种方式组合以实现
support different configurations (setups/layouts). In particular, it's possible to have a small scale single node layout and a large scale multi node setting. It's reasonable to have multiple production layouts.
支持不同的配置(设置/布局)。 特别是,可能具有较小规模的单节点布局和较大规模的多节点设置。 具有多个生产布局是合理的。
- Testing. For testing purposes one might implement a mock service and use it as a dependency in a type safe way. A few different testing layouts with various parts replaced by mocks could be maintained simultaneously. 测试。 为了进行测试,可以实现模拟服务,并以一种类型安全的方式将其用作依赖项。 可以同时维护一些不同的测试布局,其中各个部分被模拟替换。
Integration testing. Sometimes in distributed systems it's difficult to run integration tests. Using the described approach to type safe configuration of the complete distributed system, we can run all distributed parts on a single server in a controllable way. It's easy to emulate the situation
集成测试。 有时在分布式系统中,很难运行集成测试。 使用所描述的方法来键入完整分布式系统的安全配置,我们可以以可控制的方式在单个服务器上运行所有分布式部件。 模仿情况很容易
when one of the services becomes unavailable.
当其中一项服务不可用时。
缺点 (Disadvantages)
The compiled configuration approach is different from "normal" configuration and it might not suit all needs. Here are some of the disadvantages of the compiled config:
编译后的配置方法不同于“常规”配置,并且可能无法满足所有需求。 以下是编译后的配置的一些缺点:
- Static configuration. It might not be suitable for all applications. In some cases there is a need of quickly fixing the configuration in production bypassing all safety measures. This approach makes it more difficult. The compilation and redeployment are required after making any change in configuration. This is both the feature and the burden. 静态配置。 它可能不适合所有应用程序。 在某些情况下,需要绕过所有安全措施在生产中快速固定配置。 这种方法使它更加困难。 进行任何配置更改后,都需要进行编译和重新部署。 这既是功能,又是负担。
- Configuration generation. When config is generated by some automation tool this approach requires subsequent compilation (which might in turn fail). It might require additional effort to integrate this additional step into the build system. 配置生成。 当某些自动化工具生成config时,此方法需要后续编译(否则可能会失败)。 可能需要付出更多的努力才能将此额外的步骤集成到构建系统中。
Instruments. There are plenty of tools in use today that rely on text-based configs. Some of them
仪器。 如今,有很多工具都依赖于基于文本的配置。 他们中的几个
won't be applicable when configuration is compiled.
编译配置时将不适用。
- A shift in mindset is needed. Developers and DevOps are familiar with text configuration files. The idea of compiling configuration might appear strange to them. 需要转变观念。 开发人员和DevOps熟悉文本配置文件。 对他们而言,编译配置的想法可能看起来很奇怪。
- Before introducing compilable configuration a high quality software development process is required. 在引入可编译配置之前,需要高质量的软件开发过程。
There are some limitations of the implemented example:
实现的示例存在一些局限性:
If we provide extra config that is not demanded by the node implementation, compiler won't help us to detect the absent implementation. This could be addressed by using
HListor ADTs (case classes) for node configuration instead of traits and Cake Pattern.如果我们提供了节点实现不需要的额外配置,则编译器将无法帮助我们检测缺少的实现。 这可以通过使用
HList或ADT(案例类)进行节点配置(而不是特征和Cake Pattern)来解决。We have to provide some boilerplate in config file: (
package,import,objectdeclarations;我们必须在配置文件中提供一些样板:(
package,import,object声明;override def's for parameters that have default values). This might be partially addressed using a DSL.对于具有默认值的参数,请
override def)。 使用DSL可以部分解决此问题。- In this post we do not cover dynamic reconfiguration of clusters of similar nodes. 在这篇文章中,我们不会介绍相似节点集群的动态重新配置。
结论 (Conclusion)
In this post we have discussed the idea of representing configuration directly in the source code in a type safe way. The approach could be utilized in many applications as a replacement to xml- and other text- based configs. Despite that our example has been implemented in Scala, it could also be translated to other compilable languages (like Kotlin, C#, Swift, etc.). One could try this approach in a new project and, in case it doesn't fit well, switch to the old fashioned way.
在本文中,我们讨论了以类型安全的方式直接在源代码中表示配置的想法。 该方法可以在许多应用程序中用作xml和其他基于文本的配置的替代。 尽管我们的示例已在Scala中实现,但也可以将其翻译为其他可编译语言(例如Kotlin,C#,Swift等)。 可以在新项目中尝试这种方法,如果不合适,请改用老式的方法。
Of course, compilable configuration requires high quality development process. In return it promises to provide equally high quality robust configuration.
当然,可编译的配置需要高质量的开发过程。 作为回报,它承诺提供同样高质量的坚固配置。
This approach could be extended in various ways:
该方法可以通过多种方式扩展:
- One could use macros to perform configuration validation and fail at compile time in case of any business-logic constraints failures. 一个人可以使用宏执行配置验证,并且在任何业务逻辑约束失败的情况下在编译时失败。
- A DSL could be implemented to represent configuration in a domain-user-friendly way. 可以实现DSL,以域用户友好的方式表示配置。
- Dynamic resource management with automatic configuration adjustments. For instance, when we adjust the number of cluster nodes we might want (1) the nodes to obtain slightly modified configuration; (2) cluster manager to receive new nodes info. 具有自动配置调整功能的动态资源管理。 例如,当我们调整群集节点的数量时,我们可能希望(1)节点获得稍微修改的配置; (2)集群管理器接收新的节点信息。
谢谢 (Thanks)
I would like to say thank you to Andrey Saksonov, Pavel Popov, Anton Nehaev for giving inspirational feedback on the draft of this post that helped me make it clearer.
我想对Andrey Saksonov,Pavel Popov和Anton Nehaev表示感谢,感谢他们对这篇文章的草稿提供了鼓舞性的反馈,这使我更加清楚了。
分布式编译

















 1447
1447

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









