






序言
ChunJun主要是基于Flink实时计算框架,封装了不同数据源之间的数据导入与导出功能.我们只需要按照ChunJun的要求提供原始与目标数据源的相关信息给Chunjun,然后它会帮我们生成能运行与Flink上的算子任务执行,这样就避免了我们自己去根据不同的数据源重新编辑读入与读出的方案了cuiyaonan2000@163.com
参考资料:
- GitHub - DTStack/chunjun: A data integration framework 源码仓库
- 纯钧 官网API
- GitHub - alibaba/DataX: DataX是阿里云DataWorks数据集成的开源版本。 对比阿里的DataX离线集成组件
简介
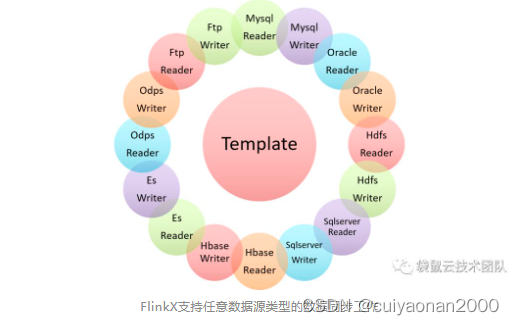
FlinkX将不同的数据源库抽象成不同的Reader插件,目标库抽象成不同的Writer插件,具有以下特点
- 基于Flink开发,支持分布式运行;
- 双向读写,某数据库既可以作为源库,也可以作为目标库;
- 支持多种异构数据源,可实现MySQL、Oracle、SQLServer、Hive、Hbase等20多种数据源的双向采集。
- 高扩展性,强灵活性,新扩展的数据源可与现有数据源可即时互通。
应用场景
FlinkX数据同步插件主要应用于大数据开发平台的数据同步/数据集成模块,通常采用将底层高效的同步插件和界面化的配置方式相结合的方式,使大数据开发人员可简洁、快速的完成数据同步任务开发,实现将业务数据库的数据同步至大数据存储平台,从而进行数据建模开发,以及数据开发完成后,将大数据处理好的结果数据同步至业务的应用数据库,供企业数据业务使用。
实现原理
ChunJun采用了一种插件式的架构:
-
不同的源数据库被抽象成不同的Reader插件;
-
不同的目标数据库被抽象成不同的Writer插件;
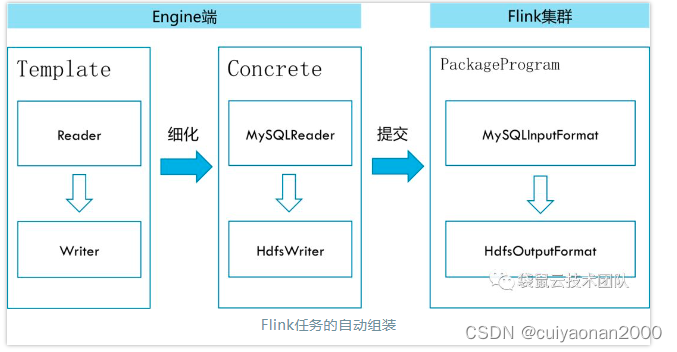
整个数据同步任务共有的处理逻辑被抽象在Template模块中,该模块根据数据同步任务配置加载对应的Reader和Writer插件,组装Flink任务,并提交到Flink集群执行(因此我们实际操作过程中就是根据数据源选择不同的插件cuiyaonan2000@163.com);
Template模块根据同步任务的配置信息加载源数据库和目的数据库对应的Reader插件和Writer插件;
- Reader插件实现了InputFormat接口,从源数据库中获取DataStream对象;
- Writer插件实现了OutputFormat接口,将目的数据库与DataStream对象相关联;
Template模块通过DataStream对象将Reader和Writer串接在一起,组装成一个Flink任务,并提交到Flink集群上执行。工作原理如下(因此ChunJun开发者只需要关注InputFormat和OutputFormat接口实现即可cuiyaonan2000@163.com):
Chunjun API
任务配置格式
一个完整的 ChunJun 任务脚本配置包含 content, setting 两个部分。content 用于配置任务的输入源与输出源,其中包含 reader,writer。而 setting 则配置任务整体的环境设定,其中包含 speed,errorLimit,metricPluginConf,restore,log,dirty。总体结构如下所示:
{
"job": {
"content": [
{
"reader": {},
"writer": {}
}
],
"setting": {
"speed": {},
"errorLimit": {},
"metricPluginConf": {},
"restore": {},
"log": {},
"dirty": {}
}
}
}ChunJun 环境生成
这个相当于就是生成一个jar ,然后我们可以根据Shell 来向这个Jar来提交任务cuiyaonan2000@163.com
压缩包
纯钧提供了已经编译好的插件压缩包(chunjun-dist.tar),里面包含目前所有的脚本案例,任务提交脚本,插件包等内容,使得用户可以直接下载,根据需要配置任务,开箱即用。
纯钧提供的压缩包(chunjun-dist.tar)里包含四部分内容:bin(包含任务提交脚本),chunjun-dist(纯钧任务插件包),chunjun-example(纯钧任务脚本模版),lib(任务提交客户端),用户可以通过bin里的提交脚本,使用已经编译好的插件jar包直接提交任务,无需关心插件编译过程,适合调研使用。
源码编译
首先使用git工具把项目clone到本地
git clone https://github.com/DTStack/chunjun.git
cd chunjun
然后在chunjun目录下执行
mvn clean package -DskipTests
或者执行
sh build/build.sh
打包结束后再output目录下 有个chunjun-dist-master.tar.gz文件就是我们要用的结果文件了如下图所示cuiyaonan2000@163.com:
解压后的路径文件夹如下所示:
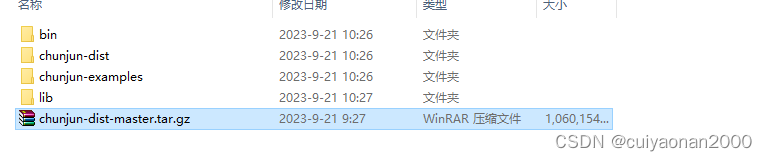
- bin : 包含任务提交脚本
- chunjun-dist: 纯钧任务插件包
- chunjun-example: 纯钧任务脚本模版
- lib: 务提交客户端,用户可以通过bin里的提交脚本,使用已经编译好的插件jar包直接提交任务,无需关心插件编译过程,适合调研使用。
多平台兼容
chunjun目前支持tdh和开源hadoop平台,对不同的平台有需要使用不同的maven命令打包
| 平台类型 | 含义 | |
|---|---|---|
| tdh | mvn clean package -DskipTests -P default,tdh | 打包出inceptor插件以及default支持的插件 |
| default | mvn clean package -DskipTests -P default | 除了inceptor插件之外的所有插件 |
常见问题
编译找不到DB2、达梦、Gbase、Ojdbc8等驱动包
解决办法:在$CHUNJUN_HOME/jars目录下有这些驱动包,可以手动安装,也可以使用插件提供的脚本安装:
## windows平台
./$CHUNJUN_HOME/bin/install_jars.bat
## unix平台
./$CHUNJUN_HOME/bin/install_jars.sh如果下载源文件中没有可以在如下的路径中下载相关jar
flinkx: 基于flink的分布式数据同步工具 - Gitee.com
启动
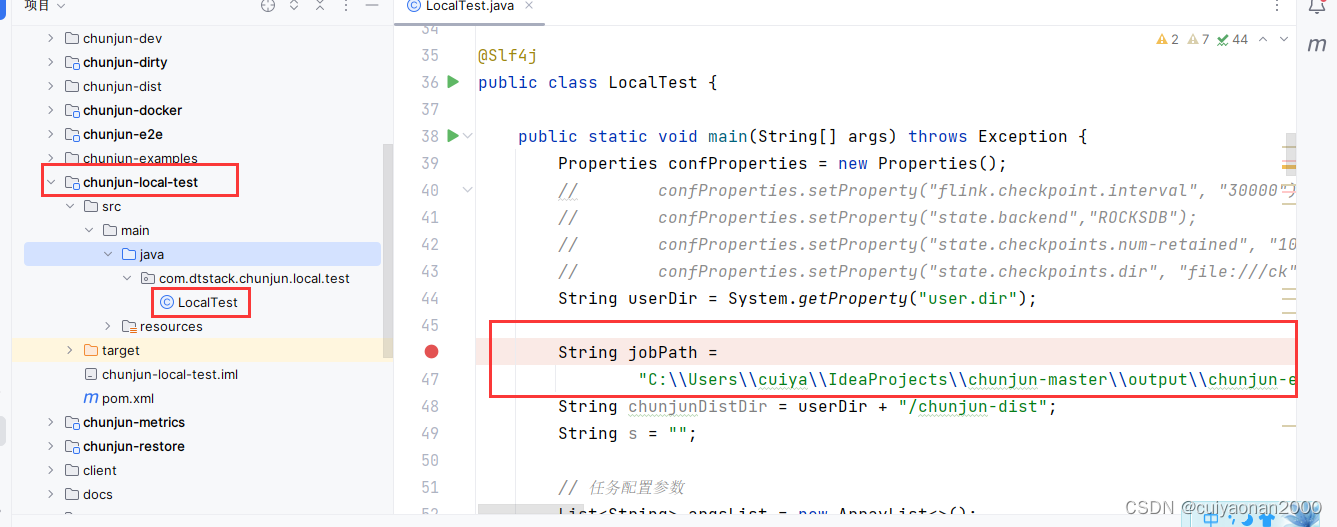
local-test
这个模式就是在本地编辑json然后测试验证json格式是否正确,另外也是我们自定义连接器后必然要测试的一个环境cuiyaonan2000@163.com
其实很简单就是按照官方下载的测试模块,改下Json路径就行了
Standalone
顾名思义就是发布到以Standalone模式启动的Flink集群上.
同时需要注意的是Flink的版本变化太大,一定要按照官网适配的flink版本cuiyaonan2000@163.com

- 首先将打包后的chunjun-dist-1.12-SNAPSHOT.tar.gz 上传并解压
- 设置环境变量Flink_HOME
-
cp -r chunjun-dist $FLINK_HOME/lib
-
sh $FLINK_HOME/bin/start-cluster.sh
-
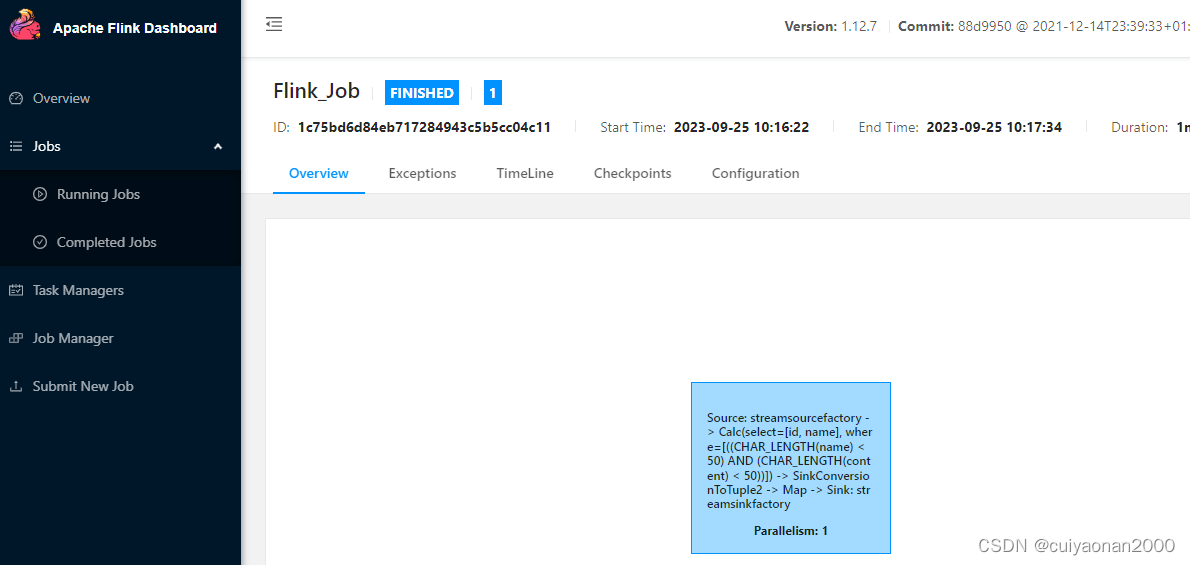
sh bin/chunjun-standalone.sh -job chunjun-examples/json/stream/stream.json
然后就能在flink的管理界面看到提交的任务如下图所示:
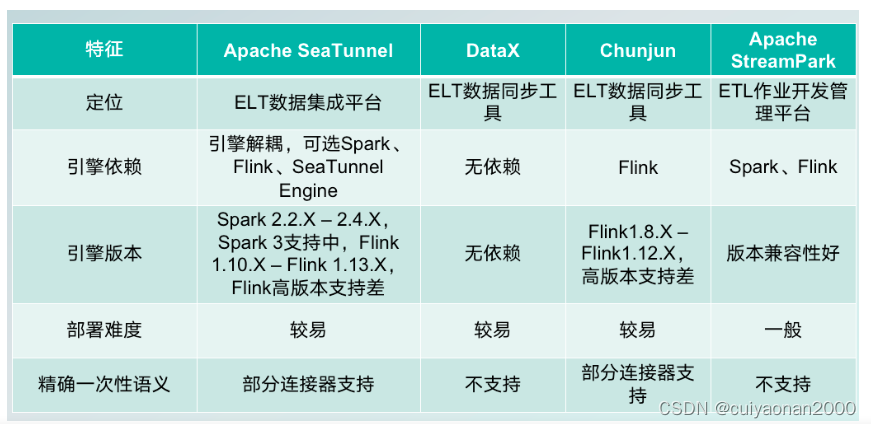
其它集成工具对比
人推荐使用DataX,因为不依赖计算资源



















 2522
2522

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











