 Flink大数据计算:Parallelism与Slot的配置与优化
Flink大数据计算:Parallelism与Slot的配置与优化





序言
因为所以.
Flink大数据计算的横向扩展是一定要考虑Parallelism 和Slot的.
slot决定了parallelism的可行性以及数量.如果强行分配很多的Paralelism则会报错显示资源不够cuiyaonan2000@163.com
Parallelism
Parallelism是我们算子的并行度的设置,默认是1.即启动多少个线程并行执行.
同时有3个层级可以设置他们的关系是:
算子设置并行度 > env 设置并行度 > 配置文件默认并行度
算子设置并行度
data.keyBy(new xxxKey())
.flatMap(new XxxFlatMapFunction()).setParallelism(5)
.map(new XxxMapFunction).setParallelism(5)
.addSink(new XxxSink()).setParallelism(1)
Env设置并行度
这里没用代码直接用管理平台的配置设置
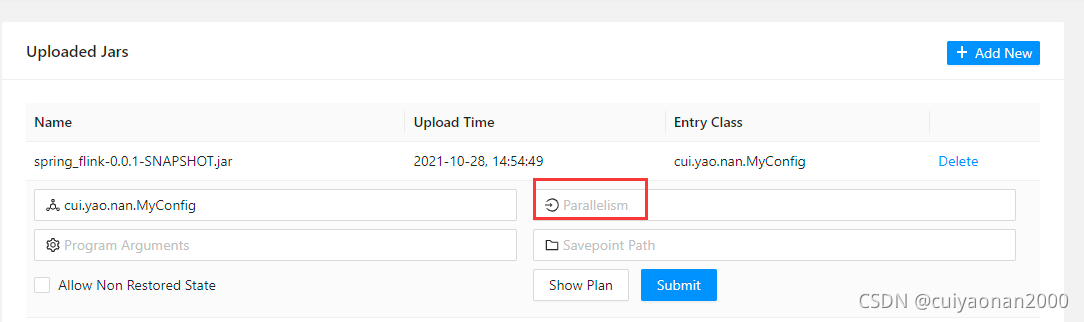
Slot
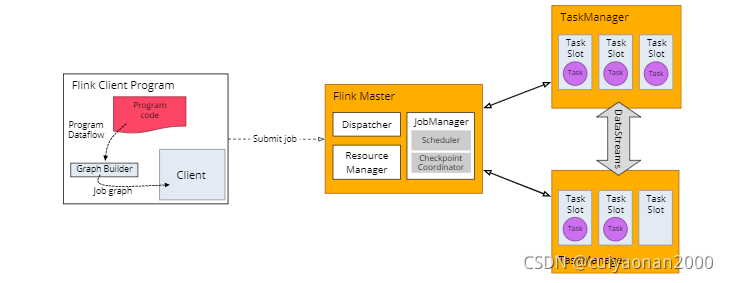
- slot指的是插槽的意思(计算资源),flink中任务的并行性由每个 Task Manager 上可用的 slot 决定。
- slot的数量跟CPU的内核的数量成正比,一台机器有多少个内核就配置多少个slot
总结
Non-Keyed
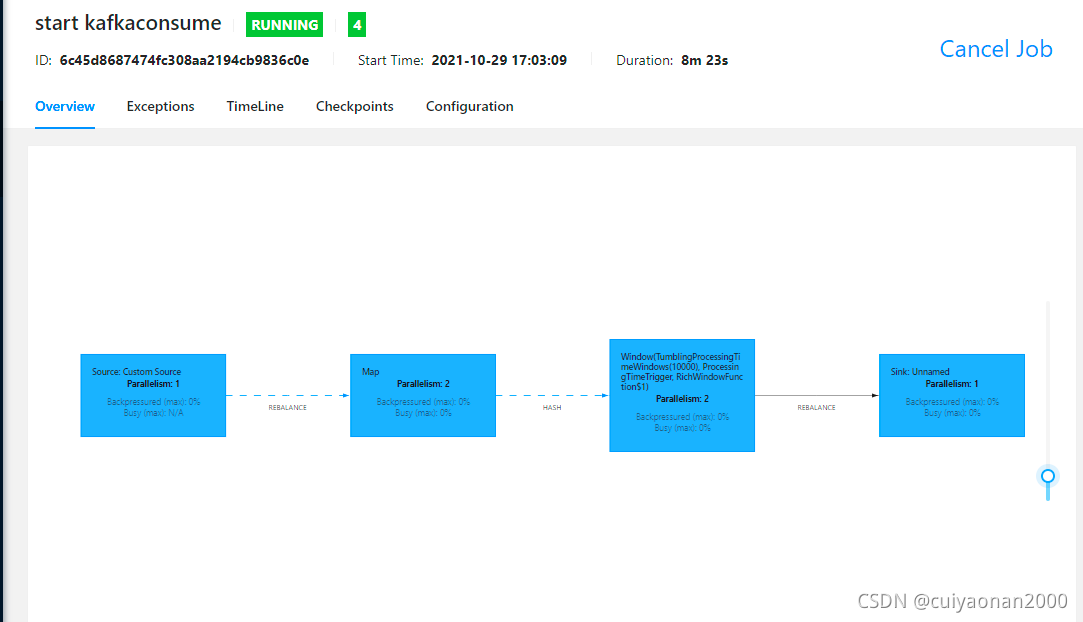
首先Parallelism 必须要根据slot的数量来程序上或者配置上控制,否则报错显示资源不够.有点不完美的是程序不能动态的去识别算子应该有多少Parallelism.
在这如果算子设置了Parallelism那要特别注意分发的机制,下游选自子的子任务可能分发的任务量并不均匀造成了资源有的特别紧张,有的特别宽松.比如使用dataStream.rebalance() 则当前的算子会把任务均匀的分发给下游算子.cuiyaonan2000@163.com
如上的是根据Non-Keyed的情况做的说明.即没有使用窗口.特别注意:cuiyaonan2000@163.com
Keyed
那如果对应Keyed的流我们就可以使用窗口,窗口的意思其实就是批量处理(类似kafka的批量).且要使用窗口则必须Keyed的流才能支持大于1的并发.否则所有窗口计算都是单线程的.
这里举个例子说明个情况 即:keyed的流,在设置窗口后,则针对window的算子只能以hash的形式被分配到数据.且不能使用reblance来负载均衡.其它的没啥特别的.
另外有一点是keyed的window并不会自动的去创建多个并发度.这个亲身经历~~~~
目前业务上的相关需要的点都搞清楚了.来劈个叉吧



















 677
677

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











