




 本文介绍如何在YARN集群上部署Spark环境,包括Scala与Spark的安装配置步骤,以及如何提交Spark任务到YARN集群进行运行。文中还涵盖了Standalone模式下Spark的配置与启动过程。
本文介绍如何在YARN集群上部署Spark环境,包括Scala与Spark的安装配置步骤,以及如何提交Spark任务到YARN集群进行运行。文中还涵盖了Standalone模式下Spark的配置与启动过程。
序言
搭建个spark on yarn的环境。
官方网址:http://spark.apache.org/downloads.html
下载Spark的版本的时,首先选择对应的Hadoop版本,然后注意需要的scala版本
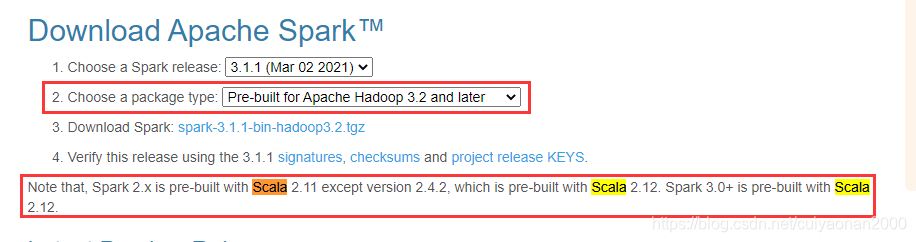
Scala环境搭建
官方下载网址https://www.scala-lang.org/download/2.12.13.html
确保你本地已经安装了 JDK 1.5 以上版本,并且设置了 JAVA_HOME 环境变量及 JDK 的 bin 目录。
#下载spark 注意要选择对应的hadoop版本
[root@cuiyaonan2000 scala] wget https://downloads.lightbend.com/scala/2.12.13/scala-2.12.13.tgz
[root@cuiyaonan2000 scala] vi /etc/profile
#增加如下内容
export SCALA_HOME=/soft/scala/scala-2.12.13
export PATH=$PATH:$SCALA_HOME/bin
#生效配置文件
[root@cuiyaonan2000 scala] source /etc/profile验证
#输入命令
[root@cuiyaonan2000 scala] scala
#展示如下内容即可
Welcome to Scala 2.12.13 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_271).
Type in expressions for evaluation. Or try :help.
#输入命令:q 表示退出scala命令模式
scala> :qSpark安装
#下载scala-2.12版本,注意要与spark的版本关联
[root@cuiyaonan2000 spark] wget https://downloads.lightbend.com/scala/2.12.13/scala-2.12.13.tgz
[root@cuiyaonan2000 spark] tar -zxvf spark-3.1.1-bin-hadoop3.2.tgz
[root@cuiyaonan2000 spark] vi /etc/profile
#增加如下内容
export SPARK_HOME=/soft/spark/spark-3.1.1-bin-hadoop3.2
export PATH=$PATH:$SPARK_HOME/bin
#命令进入pyspark 交互界面,验证是否成功
[root@cuiyaonan2000 spark] pyspark
#exit()表示退出spark 交互界面
>>> exit()
显示如下内容表示成功:
本地模式启动
#启动本地spark交互界面,且使用了4个线程
pyspark --master local[4]
#查看当前的运行模式 ,同时可以显示进程数
sc.master Spark on yarn
spark on yarn,就是把spark任务提交到yarn 集群上运行。
提交spark任务的地方,就是客户端,所以客户端一台即可。但需要保证客户端可以正常连接到hdfs集群和yarn集群。--------提交的时候通过命令来提交是client模式,还是cluster模式。
Spark本身的Master节点和Worker节点不需要启动,Spark On Yarn集群的部署不依赖Standalone集群。
因为spark on yarn 不需要启动spark自身的计算资源服务和管理资源服务,而是依赖yarn的nodemanager和resourcesmanager所以,spark需要知道yarn和hdfs的配置文件位置。
[root@cuiyaonan2000 spark] vi /etc/profile
#如果hadoop的配置文件中指明了就可以不用洗饿了
# Hadoop 的配置文件目录
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
# YARN 的配置文件目录
export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop命令
启动命令就是spark-submit 进行spark程序的提交,关于yarn-cluster 和yarn-client的启动其实就是命令的不同,影响不大。cuiyaonan2000@163.com
可以使用spark自带的sample进行环境测试
./spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode cluster --driver-memory 4g --executor-memory 2g --e
xecutor-cores 1 --queue default ../examples/jars/spark-examples*.jar 10
Standalone模式
修完完成后,将spark包scp到不同的服务器上就行。
worker(必)
[root@cuiyaonan2000 scala] cd /soft/spark/spark-3.1.1-bin-hadoop3.2/conf
#在worker文件里增加 work的服务器,可以填写ip 也可以填写机器名
vi workers
spark-config.sh(必)
[root@cuiyaonan2000 spark] vi sbin/spark-config.sh
#增加如下内容,否则work启动不了
export JAVA_HOME=/soft/jdk1.8.0_171
spark-env.sh(非必须)
[root@cuiyaonan2000 spark] cp spark-env.sh.template spark-env.sh
[root@cuiyaonan2000 spark] vi spark-env.sh
#add如下内容
#master服务器的ip 或者名称
export SPARK_MASTER_IP=master
#worker使用的CPU核心
export SPARK_WORKER_CORES=1
#worker 使用的内存
export SPARK_WORKER_MEMORY=512m
#设置的实例数 这块挺有意思 每个系统上的spark 会启动4个worker
export SPARK_WORKER_INSTANCES=4
启动
- start-all.sh #启动所有的
- start-master.sh #master服务器的ip,master启动后通过,通过IP:8080 来访问管理界面
- start-slaves.sh #启动slaves服务器
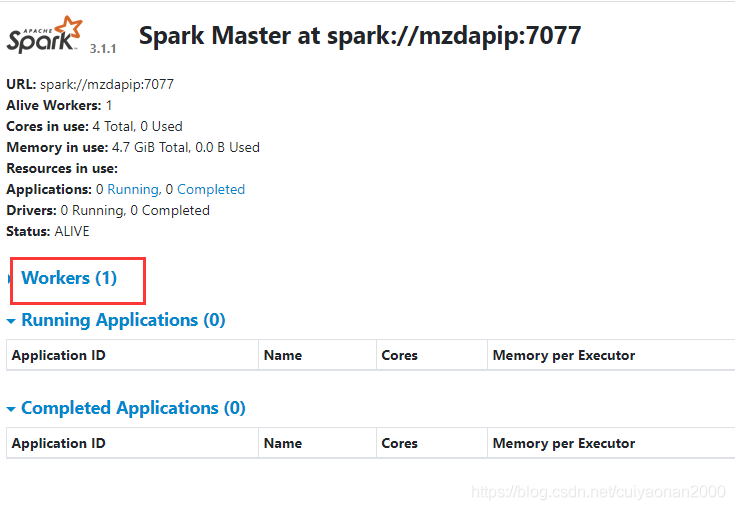
访问spark管理平台的界面如下所示:同时可以看到第一行的内容 指出了连接spark master的地址为 ip:7077



















 5487
5487




 到【灌水乐园】发言
到【灌水乐园】发言









