




序言
大数据绕不开这2个东西。
- Hbase是大数据技术的实时查询数据库(相对于传统数据库,速度和效率肯定要低,但是它是基于大数据的)。
- Hive是数据仓库,查询效率更低,因为它的查询都是基于全表扫描(目前已知的是可以把表进行分区,这样不用进行全表扫描,以进行优化),同时造成Hive慢的原因是,它提供的类SQL类工具可以把,任务拆解成MapReduce任务,在不同的HDFS进行计算,然后收集(MapReduce是一种计算框架,目前Flink也宣称可以帮助Hive进行任务拆解和运算cuiyaonan2000@163.com)
HBASE
Hbase:Hadoop database 的简称,也就是基于Hadoop数据库,是一种NoSQL数据库,主要适用于海量明细数据(十亿、百亿)的随机实时查询,如日志明细、交易清单、轨迹行为等。
HBase通过存储key/value来工作。它支持四种主要的操作:增加或者更新行,查看一个范围内的cell,获取指定的行,删除指定的行、列或者是列的版本。
版本信息用来获取历史数据(每一行的历史数据可以被删除,然后通过Hbase compactions就可以释放出空间)。虽然HBase包括表格,但是schema仅仅被表格和列簇所要求,列不需要schema。Hbase的表格包括增加/计数功能。
HBase 则非常 适合用来进行大数据的实时查询,例如 Facebook 用 HBase 进行消息和实时的分析。
HIVE
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。运行Hive查询会花费很长时间,因为它会默认遍历表中所有的数据。
Hive 适合用来对一段时间内的数据进行分析查询(即离线批量数据进行查询),例如,用来计算趋势或者网站的日志。Hive 不应该用来进行 实时的查询(Hive 的设计目的,也不是支持实时的查询)
HBASE与HIVE的应用情况
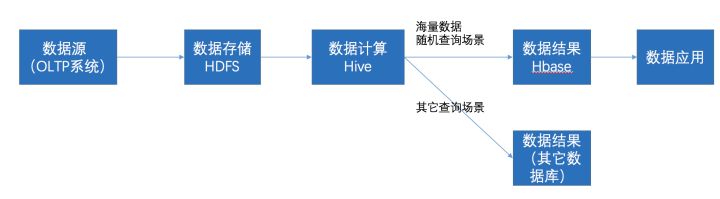
HBASE作为实施查询,HIVE用于数据清洗
- 通过ETL工具将数据源抽取到HDFS存储;
- 通过Hive清洗、处理和计算原始数据;
- HIve清洗处理后的结果,如果是面向海量数据随机查询场景的可存入Hbase
- 数据应用从HBase查询数据;
Hive集成Hbase
HBase 本身只提供了 Java 的 API 接口,并不直接支持 SQL 的语句查询。Hive 则可以直接使用 HQL(一种类SQL 语言)。
如果想要在 HBase 上使用 SQL,则需要联合使用 Apache Phonenix,或者联合使用 Hive 和HBase。
如果集成使用 Hive 查询 HBase 的数据,则无法绕过 MapReduce, 那么实时性还是有一定的损失。
Phoenix 加 HBase 的组合则不经过 MapReduce 的框架,因此当使用 Phoneix 加 HBase 的组成,实时性上会优于 Hive 加 HBase 的组合。



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











