







 本文总结了Hive、Tez和Yarn在资源管理方面的问题,提供了详细的解决方案。内容包括内存调试、map/reduce优化,以及内存配置和容器设置的调整。通过对tez.am.resource.memory.mb、hive.tez.container.size等关键参数的调整,解决了由于资源不足或冲突导致的任务执行问题。
本文总结了Hive、Tez和Yarn在资源管理方面的问题,提供了详细的解决方案。内容包括内存调试、map/reduce优化,以及内存配置和容器设置的调整。通过对tez.am.resource.memory.mb、hive.tez.container.size等关键参数的调整,解决了由于资源不足或冲突导致的任务执行问题。
Hive、Tez、Yarn资源问题总结以及优化参数
- 问题解决
Hadoop版本:2.7.3
Hive版本: 2.1.1
Tez版本: 0.9.1
问题描述:Hive集成Tez后,配置默认选择的执行引擎为tez,如下hive-site.xml配置截图。

在服务器上直接执行hive命令,可以正常进入hive客户端,
执行 set hive.execution.engine;

当set hive.execution.engine=mr;以mr作为执行引擎时,执行一些聚合,统计类的sql,比如count(1) ,会直接报以下错误:DEFAULT_MR_AM_ADMIN_USER_ENV。

咋看这种不明确的错误很懵逼,后查阅资料则是jar包冲突。
解决方法:
https://blog.youkuaiyun.com/cuichunchi/article/details/108611831
其中包括spark 的问题解决。
- 出现如下图异常:


表示没有可用的container容器分配了,由于container资源被抢占或者资源不足,而task最大的失败重试次数默认是4。故需要调整以下参数:
| 参数:用set 设置 | 值 | 描述 |
| tez.am.task.max.failed.attempts | 10 | Task任务的重试次数 |
| tez.am.max.app.attemps | 5 | AM自己失败的最大重试次数,默认2次,可能因为一些系统原因导致失联 |
| hive.tez.container.size | 不小于 yarn.scheduler.minimum-allocation-mb或者是等于 yarn.scheduler.maximum-allocation-mb的倍数 | Tez AppMaster向RM申请的container大小,单位M |
注意:hive.tez.container.size也不能过大,设置太大执行直接会以下错误:

- 出现如下图异常报错信息:

因为在mapred-sit.xml文件中配置的mapreduce.task.io.sort.mb=307,表示环形缓冲区的大小,
而上图上设置了tez.java.opts为128M,明显小于307M,从报错提示也能看出,故重新设置hive.tez.java.opts为307/0.8即可。
- 优化参数详解
背景
tez是hive的常用引擎之一,本文介绍tez常用的调试参数。主要是内存,map/reduce数量方面的调试。
Tez内存分布图:

Mapreduce内存分布图:

1.内存调试
tez.am.resource.memory.mb
| 默认值 | 参数说明 | 详细解释 |
| 128 | Application Master分配的container大小,单位为M |
|
tez.am.launch.cmd-opts
| 默认值 | 参数说明 | 详细解释 |
| -Dlog4j.configurationFile=tez-container-log4j2.properties -Dtez.container.log.level=INFO -Dtez.container.root.logger=CLA | Tez AppMaster进程启动期间提供的命令行选项。 不要在这些启动选项中设置任何Xmx或Xms,以便Tez可以自动确定它们 | 不需要主动设置 |
hive.tez.container.size
| 默认值 | 参数说明 | 详细解释 |
| 128 | Tez AppMaster向RM申请的container大小,单位M | 不需要主动设置TEZ的AppMaster占用的container大小由TEZ自动跳转,但是向AM申请出来的container大小则需要本参数管理 |
hive.tez.java.opts(可以直接设置–XX:NewRatio=8)
及( set hive.tez.java.opts=-XX:NewRatio=8;)
| 默认值 | 参数说明 | 详细解释 |
| -Dlog4j.configurationFile=tez-container-log4j2.properties -Dtez.container.log.level=INFO -Dtez.container.root.logger=CLA | container进程启动期间提供的命令行选项。可以在默认参数后续添加内存参数选项,比如:-Xmx7500m -Xms 7500m | 该参数大小一般为hive.tez.container.size的80%,不建议直接在该参数中直接添加Xmx/Xms,而是使用下面的参数调参opts大小 |
tez.container.max.java.heap.fraction
| 默认值 | 参数说明 | 详细解释 |
| 0.8 | 如果hive.tez.java.ops参数中没有设置Xmx/Xms指标的话,TEZ将选择该参数来确定Xmx/Xms的值,值得大小为0.8*hive.tez.container.size | 建议使用该值来调整opts |
tez.runtime.io.sort.mb
| 默认值 | 参数说明 | 详细解释 |
| 512 | 排序输出时的排序缓冲区大小,单位M | 可以将tez.runtime.io.sort.mb设置为hive.tez.container.size的40%, 但该值不能超过2GB。 |
hive.auto.convert.join.noconditionaltask.size
| 默认值 | 参数说明 | 详细解释 |
| 10000000 | 如果hive.auto.convert.join.noconditionaltask已关闭,则此参数不会生效。但是,如果它打开,并且n路连接的表/分区的n-1的大小总和小于此大小,连接直接转换为mapjoin(没有条件任务)。 默认值为10MB | 该值能将多个JOIN的表的n-1个表合成一个大表,然后将该表转为mapjoin|可以将该值设置为hive.tez.container.size的1/3。 |
tez.am.task.max.failed.attempts=10;
任务之间重试失败次数,默认4次
set tez.am.max.app.attemps=5;
DAGAM失败重试次数
2.map/reduce优化
2.1 map数量设置
tez.grouping.min-size
tez.grouping.max-size
| 默认值 | 参数说明 | 详细解释 |
| 50M,1G | 分组拆分大小的下限,默认值为 50 MB分组拆分大小的上限,默认值为 1 GB | 减小这两个参数可以改善延迟,增大这两个参数可以提高吞吐量。例如,若要为数据大小 128 MB设置四个映射器任务,可将每个任务的这两个参数设置为 32 MB(33,554,432 字节)。。 |
hive.tez.input.format
| 默认值 | 参数说明 | 详细解释 |
| org.apache.hadoop. hive.ql.io.HiveInputFormat | 默认采用hiveInputFormat切分文件 | 如果小文件过多,导致map任务数生成很多,可以采用org.apache.hadoop.hive.ql.io.CombineHiveInputFormat来合并小文件,减少过多的map任务数 |
2.2 reduce数量设置
hive.tez.auto.reducer.parallelism
| 默认值 | 参数说明 | 详细解释 |
| false | 打开Tez的reducer parallelism特性。设置true后,tez会在运行时根据数据大小动态调整reduce数量 | 最好使用TEZ提供的动态调整reduce数量功能。不要使用mapred.reduce.tasks参数去直接决定reduce的个数。只有打开该参数才能使用下面的hive.tex.min.partition.factor ,hive.tez.max.partition.factor参数 |
hive.exec.reducers.max
| 默认值 | 参数说明 | 详细解释 |
| 1009 | 任务中允许的最大reduce数量 | 只有不使用mapred.reduce.tasks参数,该参数才能生效。 |
hive.exec.reducers.bytes.per.reducer
| 默认值 | 参数说明 | 详细解释 |
| 256000000 | 每个reduce处理的数据量,默认值是256M | 介绍该参数是为了说明下面的计算reduce个数的公式 |
hive.tex.min.partition.factor
hive.tez.max.partition.factor
maxReduces = min(hive.exec.reducers.max [1099], max((ReducerStage estimate/hive.exec.reducers.bytes.per.reducer),1)*hive.tez.max.partition.factor)
minReduces = min(hive.exec.reducers.max [1099], max((ReducerStage estimate/hive.exec.reducers.bytes.per.reducer),1)*hive.tez.min.partition.factor)
| 默认值 | 参数说明 | 详细解释 |
| 0.252 | 1.hive.tex.min.partition.factor默认值为0.252.hive.tez.max.partition.factor默认值为2这两个值效果一致,增加该值就是增加reduce数量。减少该值则减少reduce数量 | 从公式中可以看出调整reduce数量由三个变量控制: hive.exec.reducers.bytes.per.reducer, hive.tex.min.partition.factor,hive.tex.max.partition.factor。 假设reduce任务估算出的数据里为 190944 bytes, 则maxReuces=min(1099, max(190944/256000000,1)*2)=2 |
|
|
|
|
tez.shuffle-vertex-manager.min-src-fraction
tez.shuffle-vertex-manager.max-src-fraction
| 默认值 | 参数说明 | 详细解释 |
| 0.250.75 | 1.tez.shuffle-vertex-manager.min-src-fraction默认值为0.252.tez.shuffle-vertex-manager.max-src-fraction默认值为2这两个值效果一致,增加该值则reduce stage启动晚一些。减少该值则reduce stage启动早一些 | 举例:想让所有map都执行完才开始执行reduce,可以将这两个值都设置为1 |
- 计算yarn资源配置以及mapreduce的内存、cpu的设定
3.1脚本计算内存配置设置
计算出处地址:
Python脚本来计算资源值:
| 选项 | 描述 |
| -c核心 | 每个主机上的核心数。 |
| -m内存 | 每个主机上的内存量(以GB为单位)。 |
| -d磁盘 | 每个主机上的磁盘数。 |
| -k HBASE | 如果已安装HBase,则为“ True”,否则为“ False”。 |
运行如下命令:
python hdp-configuration-utils.py -c 16 -m 64 -d 4 -k True
将返回:
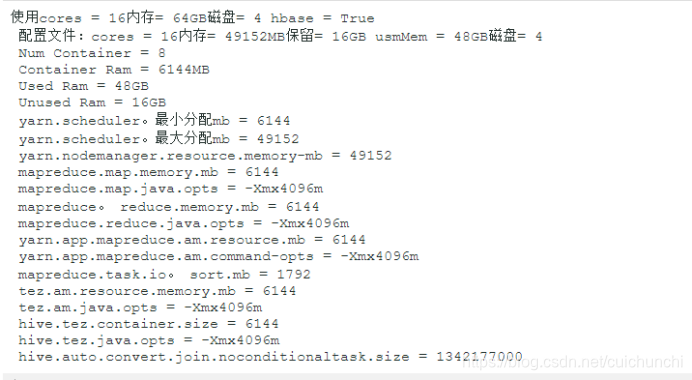
3.2手动计算内存配置设置
本节介绍如何根据节点硬件规格手动配置YARN和MapReduce内存分配设置。
YARN考虑了群集中每台计算机上所有可用的计算资源。根据可用资源,YARN协商来自集群中运行的应用程序(例如MapReduce)的资源请求。然后,YARN通过分配容器为每个应用程序提供处理能力。容器是YARN中处理能力的基本单位,并且是资源元素(内存,cpu等)的封装。
在Hadoop集群中,至关重要的是平衡内存(RAM),处理器(CPU核心)和磁盘的使用,以使处理不受这些集群资源中任何一种的约束。作为一般建议,每个磁盘和每个核心允许两个容器可以为群集利用率提供最佳平衡。
确定群集节点的适当YARN和MapReduce内存配置时,请从可用的硬件资源开始。具体来说,请注意每个节点上的以下值:
- RAM(内存量)
- CORES(CPU内核数)
- 磁盘(磁盘数)
YARN和MapReduce的总可用RAM应考虑预留内存。保留内存是系统进程和其他Hadoop进程(例如HBase)所需的RAM。
预留内存=堆栈内存预留+ HBase内存预留(如果HBase在同一节点上)
使用下表确定每个节点的保留内存。
保留内存建议
| 每个节点的总内存 | 建议的预留系统内存 | 建议的保留HBase内存 |
| 4GB | 1 GB | 1 GB |
| 8 GB | 2 GB | 1 GB |
| 16 GB | 2 GB | 2 GB |
| 24 GB | 4GB | 4GB |
| 48 GB | 6 GB | 8 GB |
| 64 GB | 8 GB | 8 GB |
| 72 GB | 8 GB | 8 GB |
| 96 GB | 12 GB | 16 GB |
| 128 GB | 24 GB | 24 GB |
| 256 GB | 32 GB | 32 GB |
| 512 GB | 64 GB | 64 GB |
下一个计算是确定每个节点允许的最大容器数。可以使用以下公式:
容器数=最小值(2 * CORES,1.8 * DISKS,(总可用RAM)/ MIN_CONTAINER_SIZE)
其中MIN_CONTAINER_SIZE是最小容器大小(在RAM中)。该值取决于可用的RAM数量-在较小的内存节点中,最小容器大小也应该较小。下表概述了推荐值:
| 每个节点的总RAM | 建议的最小容器尺寸 |
| 小于4 GB | 256兆字节 |
| 在4 GB和8 GB之间 | 512兆字节 |
| 介于8 GB和24 GB之间 | 1024兆字节 |
| 24 GB以上 | 2048兆字节 |
最终的计算是确定每个容器的RAM数量:
每个容器的RAM =最大值(MIN_CONTAINER_SIZE,(总可用RAM)/容器)
通过这些计算,可以设置YARN和MapReduce配置:
| 配置文件 | 配置设定 | 价值计算 |
| yarn-site.xml | yarn.nodemanager.resource.memory-mb | =容器*每个容器RAM |
| yarn-site.xml | 纱线调度器最小分配MB | =每个容器RAM |
| yarn-site.xml | yarn.scheduler.maximum-allocation-mb | =容器*每个容器RAM |
| mapred-site.xml | mapreduce.map.memory.mb | =每个容器RAM |
| mapred-site.xml | mapreduce.reduce.memory.mb | = 2 *每个容器的RAM |
| mapred-site.xml | mapreduce.map.java.opts | = 0.8 *每个容器的RAM |
| mapred-site.xml | mapreduce.reduce.java.opts | = 0.8 * 2 *每个容器的RAM |
| yarn-site.xml(检查) | yarn.app.mapreduce.am.resource.mb | = 2 *每个容器的RAM |
| yarn-site.xml(检查) | yarn.app.mapreduce.am.command-opts | = 0.8 * 2 *每个容器的RAM |
注意:安装后, yarn-site.xml和mapred-site.xml都位于/etc/hadoop/conf文件夹中。
例子
群集节点具有12个CPU内核,48 GB RAM和12个磁盘。
预留内存=为系统内存预留6 GB +(如果为HBase)为HBase 8 GB
最小容器大小= 2 GB
如果没有HBase:
容器数=最小值(2 * 12,1.8 * 12,(48-6)/ 2)=最小值(24,21.6,21)= 21
每个容器的RAM =最大(2,(48-6)/ 21)=最大(2,2)= 2
| 组态 | 价值计算 |
| yarn.nodemanager.resource.memory-mb | = 21 * 2 = 42 * 1024 MB |
| yarn.scheduler.minimum-allocation-mb | = 2 * 1024 MB |
| yarn.scheduler.maximum-allocation-mb | = 21 * 2 = 42 * 1024 MB |
| mapreduce.map.memory.mb | = 2 * 1024 MB |
| mapreduce.reduce.memory.mb | = 2 * 2 = 4 * 1024 MB |
| mapreduce.map.java.opts | = 0.8 * 2 = 1.6 * 1024 MB |
| mapreduce.reduce.java.opts | = 0.8 * 2 * 2 = 3.2 * 1024 MB |
| yarn.app.mapreduce.am.resource.mb | = 2 * 2 = 4 * 1024 MB |
| yarn.app.mapreduce.am.command-opts | = 0.8 * 2 * 2 = 3.2 * 1024 MB |
如果包括HBase:
容器数量=最小值(2 * 12,1.8 * 12,(48-6-8)/ 2)=最小值(24,21.6,17)= 17
每个容器的RAM =最大(2,(48-6-8)/ 17)=最大(2,2)= 2
| 组态 | 价值计算 |
| yarn.nodemanager.resource.memory-mb | = 17 * 2 = 34 * 1024 MB |
| yarn.scheduler.minimum-allocation-mb | = 2 * 1024 MB |
| yarn.scheduler.maximum-allocation-mb | = 17 * 2 = 34 * 1024 MB |
| mapreduce.map.memory.mb | = 2 * 1024 MB |
| mapreduce.reduce.memory.mb | = 2 * 2 = 4 * 1024 MB |
| mapreduce.map.java.opts | = 0.8 * 2 = 1.6 * 1024 MB |
| mapreduce.reduce.java.opts | = 0.8 * 2 * 2 = 3.2 * 1024 MB |
| yarn.app.mapreduce.am.resource.mb | = 2 * 2 = 4 * 1024 MB |
| yarn.app.mapreduce.am.command-opts | = 0.8 * 2 * 2 = 3.2 * 1024 MB |
3.3笔记:
1、在yarn.scheduler.minimum-allocation-mb不更改的情况下进行更改yarn.nodemanager.resource.memory-mb,或在 yarn.nodemanager.resource.memory-mb不更改的情况下进行更改也将yarn.scheduler.minimum-allocation-mb更改每个节点的容器数。
2、如果安装的RAM高但磁盘/核心不多,则可以通过降低yarn.scheduler.minimum-allocation-mb和 来释放RAM用于其他任务 yarn.nodemanager.resource.memory-mb。
3.3.1。在YARN上配置MapReduce内存设置
MapReduce在YARN之上运行,并利用YARN容器来计划和执行其Map and Reduce任务。在YARN上配置MapReduce资源利用率时,需要考虑三个方面:
- 每个Map and Reduce任务的物理RAM限制。
- 每个任务的JVM堆大小限制。
- 每个任务将接收的虚拟内存量。
您可以为每个Map and Reduce任务定义最大内存量。由于每个Map and Reduce任务将在单独的容器中运行,因此这些最大内存设置应等于或大于YARN最小容器分配。
对于上一节中使用的示例集群(48 GB RAM,12个磁盘和12个内核),容器的最小RAM(yarn.scheduler.minimum-allocation-mb)= 2 GB。因此,我们将为Map任务容器分配4 GB,为Reduce任务容器分配8 GB。
在 mapred-site.xml:
<name> mapreduce.map.memory.mb </ name>
<值> 4096 </ value>
<name> mapreduce.reduce.memory.mb </ name>
<value> 8192 </ value>
每个容器将为Map和Reduce任务运行JVM。JVM堆大小应设置为小于“映射容器”和“缩小容器”的值,以使它们在YARN分配的容器内存的范围内。
在 mapred-site.xml:
<name> mapreduce.map.java.opts </ name>
<value> -Xmx3072m </ value>
<name> mapreduce.reduce.java.opts </ name>
<value> -Xmx6144m </ value>
前述设置配置了Map和Reduce任务将使用的物理RAM的上限。每个Map and Reduce任务的虚拟内存(物理+分页内存)上限由允许的每个YARN容器的虚拟内存比率确定。使用以下配置属性设置此比率,默认值为2.1:
在 yarn-site.xml:
<name> yarn.nodemanager.vmem-pmem-ratio </ name>
<value> 2.1 </ value>
使用示例集群上的上述设置,每个Map任务将收到以下内存分配:
分配的总物理RAM = 4 GB
Map任务容器内的JVM堆空间上限= 3 GB
虚拟内存上限= 4 * 2.1 = 8.2 GB
使用YARN上的MapReduce,不再需要为Map和Reduce任务预先配置的静态插槽。整个群集可用于根据每个作业的需要动态分配Map和Reduce任务。在我们的示例集群中,使用上述配置,YARN将能够在每个节点上分配多达10个Mappers(40/4)或5个Reducer(40/8)(或每个40 GB内的其他Mappers和Reducer组合)节点限制)。

















 1828
1828

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









