



1. 引言
如果你熟悉 C 语言,那么学习 C++ 会让你感受到编程的高效和灵活性。C++ 不仅保留了 C 的速度和低级操作能力,还提供了现代编程所需的面向对象特性。本文将帮助你快速入门 C++,并展示它与 C 的区别。
2. 命名空间
命名空间是 C++ 提供的一种功能,用于组织代码并解决名称冲突问题。
在大型项目中,不同模块可能会定义相同名字的变量或函数,这时命名空间可以帮助我们把这些名字隔离开。
2.1 关键特点
-
避免命名冲突
不同模块可以定义相同名字的变量或函数,而不会冲突。 -
组织代码
把相关的函数、类和变量归类到一个逻辑单元中,使代码结构更加清晰。 -
灵活性
可以嵌套命名空间,也可以通过using关键字引入命名空间。
#include <stdio.h>
/*可以看到,尽管在不同命名空间中重复定义了 age、sex 和 phone 等变量,
但由于命名空间的隔离作用,所以变量之间不会冲突。*/
namespace Jack
{
int age = 20;
char sex = '男';
char phone[] = "123-4567-890";
}
namespace Kate
{
int age = 23;
char sex = '女';
char phone[] = "098-7654-321";
}
int main() {
// 使用 Jack 和 Kate 命名空间的变量
printf("Jack age: %d\n", Jack::age);
printf("Kate age: %d\n", Kate::age);
return 0;
}2.2 命名空间的定义
• 定义命名空间,需要使用到namespace关键字,后面跟命名空间的名字,然后接⼀对{}即可,{}中即为命名空间的成员。命名空间中可以定义变量/函数/类型等。
• namespace本质是定义出⼀个域,这个域跟全局域各自独立,不同的域可以定义同名变量
• namespace只能定义在全局,当然也可以嵌套定义。
• 项⽬⼯程中多⽂件中定义的同名namespace会认为是⼀个namespace,不会冲突。
• C++ 提供了 命名空间别名 的功能,允许我们为长路径的命名空间定义一个短的、简洁的别名。
• C++标准库都放在⼀个叫std(standard)的命名空间中
#include <stdio.h>
//基本语法
namespace name
{
// 命名空间内的变量、函数、类
}
namespace school
{
char postalCode[] = "123456"; // 学校邮政编码
char address[] = "xxx省xxx市"; // 学校地址
//命名空间可以嵌套
namespace student1{
char name[] = "Jack"; // 学生姓名
int age = 20; // 学生年龄
}
//namespace 本质是定义出⼀个独⽴域,不同的域可以定义同名变量
namespace student2{
char name[] = "Kate"; // 学生姓名
int age = 21; // 学生年龄
}
}
// 使用别名
namespace stu1 = school::student1; // 定义别名 stu1
int main()
{
// 错误示例:命名空间只能定义在全局作用域
// 编译报错
// namespace a {
// ...
// }
// 使用嵌套命名空间的示例
printf("School postal code: %s\n", school::postal_code);
printf("Student1 name: %s\n", school::student1::name);
printf("Student1 age: %d\n", school::student1::age);
printf("Student2 name: %s\n", school::student2::name);
printf("Student2 age: %d\n", school::student2::age);
// 使用别名访问
printf("Student1 name: %s\n", stu1::name);
return 0;
}2.2 命名空间的使用
编译查找⼀个变量的声明/定义时,默认只会在局部或者全局查找,不会到命名空间里面去查找。们要使用命名空间中定义的变量/函数,有三种方式:
1. 指定命名空间访问
#include <stdio.h>
namespace Jack
{
int age = 20;
char sex = '男';
char phone[] = "123-4567-890";
}
namespace Kate
{
int age = 23;
char sex = '女';
char phone[] = "098-7654-321";
}
int main() {
// 编译报错: 未声明的标识符
//printf("%d\n", age);
// 指定命名空间访问
printf("Jack: %d, %c, %s\n", Jack::age, Jack::sex, Jack::phone);
printf("Kate: %d, %c, %s\n", Kate::age, Kate::sex, Kate::phone);
return 0;
}在这个例子中,使用了命名空间 Jack:: 来限定 age、sex 和 phone。这是访问命名空间成员的标准方法,需要显式地指定命名空间前缀。
2. 将命名空间中某个成员展开
using Jack::age; // 只展开命名空间 Jack 中的成员 age
int main() {
// 使用 using 后的变量 age
printf("Age: %d\n", age); // 正确,age 被引入当前作用域
// 直接访问未展开的成员 sex
printf("Sex: %c\n", Jack::sex); // 正确,直接通过命名空间访问
// 编译报错:未声明的标识符,因为 sex 没有通过 using 引入
// printf("Sex: %c\n", sex);
return 0;
}
使用 using Jack::age; 将 Jack 命名空间中的 age 引入当前作用域,之后就可以直接使用 age,不再需要显式写 Jack:: 前缀。这种方式适用于只想引入命名空间中的特定成员。
3. 展开命名空间中全部成员
// 展开命名空间中的全部成员
using namespace Jack;
int main() {
// 直接使用命名空间中的成员
printf("Age: %d\n", age); // 输出 Jack::age
printf("Sex: %c\n", sex); // 输出 Jack::sex
printf("Phone: %s\n", phone); // 输出 Jack::phone
return 0;
}
使用 using namespace Jack; 引入整个 Jack 命名空间后,在当前作用域中可以直接使用命名空间中的所有成员,而无需前缀。这种方式简化了代码,但也增加了潜在的命名冲突风险,尤其在较大的项目中。
3. C++输入&输出与 C 语言的对比
C++ 的输入输出(I/O)系统与 C 语言相比,有显著的不同。C 语言使用的是 printf 和 scanf,而 C++ 提供了更加现代化和灵活的 I/O 流方式,即通过 iostream 库中的 cin 和 cout 来处理输入输出。
3.1 C 语言的输入输出
在 C 语言中,输入输出主要使用标准库函数 printf 和 scanf 来进行格式化输出和输入。
-
输出:
#include <stdio.h>
int main()
{
int num = 100, num1 = 200;
printf("num: %d, num1 %d", num, num1); // 使用 printf 输出
return 0;
}- 输出:
#include <stdio.h>
int main()
{
int num, num1;
scanf("%d %d", &num, &num1);
printf("num: %d, num1 %d", num, num1); // 使用 scanf 获取用户输入
return 0;
}3.1.1 特点
-
printf和scanf函数的使用需要格式化字符串,例如%d、%s来表示不同类型的数据。 -
输入输出操作比较直接,但缺乏面向对象的封装。
3.2 C++的输入输出
C++ 提供了更为简洁和灵活的 I/O 机制,主要通过 iostream 库中的 cin 和 cout 来处理输入和输出。
- 输出:
#include <iostream>
using namespace std;
int main()
{
int num = 100, num1 = 200;
cout << "num: " << num << "num1: " << num1 << endl; // 使用 cout 输出
return 0;
}- 输入:
#include <iostream>
using namespace std;
int main()
{
int num, num1;
cin >> num >> num1; // 使用 cin 获取用户输入
cout << "num: " << num << "num1: " << num1 << endl;
return 0;
}3.2.1 特点
-
cin和cout不需要格式化字符串,操作符<<用于输出,>>用于输入。它们的使用更符合 C++ 面向对象的思想。 -
默认输出是自动类型匹配,不需要显式指定数据类型格式(虽然我们仍然可以使用流控制来格式化输出)。
-
支持链式操作,可以在一个语句中连续进行多个输出操作。
3.3 C++ 与 C 输入输出的主要区别
| 特性 | C 语言输入输出 | C++ 输入输出 |
|---|---|---|
| 使用的库 | stdio.h | iostream |
| 主要函数 | printf / scanf | cout / cin |
| 格式化字符串 | 需要使用格式化字符串,如 %d, %s | 不需要格式化,使用 << 和 >> 操作符 |
| 面向对象 | 非面向对象风格 | 面向对象,流是对象,符合 C++ 的设计哲学 |
| 扩展性和灵活性 | 较为简单,扩展性差 | 支持流操作符重载,提供更多灵活性 |
| 操作符支持 | 不支持 | 支持流操作符 << 和 >>,可重载 |
C 语言 的输入输出以函数为基础,直接且高效,但缺乏灵活性和面向对象的封装。
C++ 的输入输出使用 iostream 库,采用流式操作,更符合 C++ 的面向对象设计思想,提供了更大的灵活性和可扩展性。
3.4 补充
<< 是流插⼊运算符,>> 是流提取运算符。(C语言使用这两个运算符做位运算左移/右移)
cout / cin / endl等都属于C++标准库,C++标准库都放在⼀个叫std(standard)的命名空间中,所以要通过命名空间的使用方式去用他们。
⼀般日常练习中可以使用using展开命名空间,但是实际项目开发中不建议直接展开。
就算没有包含<stdio.h>,也可以使用printf和scanf,因为在包含<iostream>时会间接包含。vs系列 编译器是这样的,其他编译器可能会报错。
4. 缺省参数
在 C++ 中,缺省参数(Default Arguments)是一种在函数声明时为参数指定默认值的机制。这允许调用者在调用函数时,某些参数可以省略,使用默认值,而不必每次都传递所有的参数。缺省参数提高了函数的灵活性,并简化了代码。
4.1 缺省参数的语法
在函数声明时,可以为参数指定缺省值。缺省参数的值必须出现在参数列表的右侧,并且只能有一个缺省值,或者多个缺省值必须从右往左连续设置,不能间隔跳跃给缺省值。
#include <iostream>
using namespace std;
void print(const char* name, int age = 18) {
cout << "Name: " << name << ", Age: " << age << endl;
}
int main() {
printInfo("Jack"); // 调用时只传递一个参数,age 使用默认值 18
printInfo("Jack", 22); // 调用时传递两个参数,使用传递的值
return 0;
}4.2 使用缺省参数的注意事项
1. 只能从右向左指定默认值:
// 编译报错:缺省参数必须从右向左依次设置
int add(int a = 0, int b) {
return a + b;
}
// 正确示例
int add(int a, int b = 0) {
return a + b;
}
2. 函数声明和定义分离时,缺省参数不能在函数声明和定义中同时出现,规定必须函数声明给缺省值。
// 声明时给出默认值
int add(int a, int b = 0);
// 错误示例:定义时重复为参数提供缺省值
// 编译报错: 重复为参数 b 设置默认值
int add(int a, int b = 0){
return 0;
}
// 正确示例:定义时不再为参数提供默认值
int add(int a, int b) {
return a + b; // // 使用传入参数或默认值进行计算
}
4.3 缺省参数的实际应用案例
为了更好地理解缺省参数的实际用途,以下是一个“计算商品总价”的案例:
#include <iostream>
using namespace std;
// 默认税率为 10%
double calculatePrice(double price, double taxRate = 0.1) {
return price * (1 + taxRate);
}
int main() {
cout << "Price with default tax: " << calculatePrice(100) << endl;
cout << "Price with custom tax: " << calculatePrice(100, 0.2) << endl;
return 0;
}
5. 函数重载
在 C++ 中,函数重载(Function Overloading)是指在同一作用域内,允许定义多个同名函数,这些函数的参数列表(包括参数个数、类型、顺序)必须有所不同。
通过函数重载,可以根据调用时传递的参数类型和数量,自动选择最匹配的函数进行调用,从而提高程序的灵活性。
5.1 函数重载的规则
1. 函数名必须相同
函数重载的核心就是多个函数使用相同的名字。
2. 参数列表必须不同
参数列表可以通过以下方式实现差异:
-
参数的个数不同。
// 参数类型不同
int add(int a, int b)
{
cout << "int Add(int a, int b)" << endl;
retrun a + b;
}
double add(double a, double b)
{
cout << "double Add(double a, double b)" << endl;
return a + b;
}-
参数类型顺序不同。
// 参数类型顺序不同
void func(int a, char b)
{
cout << "void func(int a, char b)" << endl;
}
void func(char b, int a)
{
cout << "void func(char b, int a)" << endl;
}-
参数的个数不同。
// 参数个数不同
void greet(const char* name)
{
cout << "Hello, " << name << "!" << endl;
}
void greet(const char* name, int times)
{
for (int i = 0; i < times; ++i)
{
cout << "Hello, " << name << "!" << endl;
}
}3. 返回值类型不能用于区分重载
仅仅依赖返回值类型的不同,无法实现函数重载。
// 返回值不同不能作为重载条件,因为调⽤时⽆法区分
void func()
{
cout << "void func()" << endl;
}
int func()
{
cout << "int func()" << endl;
return 0;
}5.2 函数重载的注意事项
参数列表中的默认值可能引发歧义
如果一个函数的重载版本同时存在默认参数值,可能会导致调用时的二义性。
// 下⾯两个函数构成重载
// 但是调⽤时会报错,存在歧义,编译器不知道调⽤哪一个函数
void greet()
{
cout << "Hello" << endl;
}
void greet(const char* name = "Jack")
{
cout << "Hello" << name << endl;
}
int main()
{
greet(); // 编译报错:调用时存在二义性
return 0;
}5.3 函数重载的实际应用案例
案例 1:多种数据类型的打印
#include <iostream>
using namespace std;
void print(int value) {
cout << "Integer: " << value << endl;
}
void print(double value) {
cout << "Double: " << value << endl;
}
void print(const char* value) {
cout << "String: " << value << endl;
}
int main() {
print(42); // 调用 int 参数的重载版本
print(3.14); // 调用 double 参数的重载版本
print("Hello!"); // 调用 const char* 参数的重载版本
return 0;
}
输出结果:
Integer: 42
Double: 3.14
String: Hello!案例 2:图形计算
#include <iostream>
using namespace std;
// 计算矩形面积
int area(int length, int width) {
return length * width;
}
// 计算圆形面积
double area(double radius) {
return 3.14 * radius * radius;
}
int main() {
cout << "Rectangle area: " << area(5, 10) << endl;
cout << "Circle area: " << area(7.0) << endl;
return 0;
}
输出结果:
Rectangle area: 50
Circle area: 153.86
6. 引用
在 C++ 中,引用(Reference) 是一种 变量的别名,它提供了一种可以通过另一个名称直接访问变量的机制。引用的引入简化了指针的使用,同时提供了一种更加安全和直观的方式来操作数据。
6.1 引用的定义
引用是某个变量的别名,可以通过引用操作同一个变量。它使用符号 & 来声明。
void refTest() {
int a = 10; // 定义一个变量
int& ra = a; // 定义引用 ra,引用变量 a
cout << "Address of a : " << &a << endl; // 输出变量 a 的地址
cout << "Address of ra : " << &ra << endl; // 输出引用 ra 的地址,和 a 的地址相同
}6.2 引用的特点
1. 引用必须在声明时被初始化,不能是空引用
int main()
{
// 编译报错:“ra”: 必须初始化引⽤
int& ra;
return 0;
}2. 引用一旦绑定到某个变量,就无法再改变绑定。
int main() {
int a = 10;
int b = 20;
int& ref = a; // 引用 ref 绑定到变量 a
cout << "ref: " << ref << endl; // 输出 ref 的值,即 a 的值
ref = b; // 修改的是 a 的值,而不是重新绑定 ref 到 b
cout << "a: " << a << endl; // 输出 a 的值,已经被修改为 20
cout << "b: " << b << endl; // b 的值不变
return 0;
}3. ⼀个变量可以有多个引用
int main() {
int a = 10;
int& ref1 = a; // ref1 是 a 的引用
int& ref2 = a; // ref2 也是 a 的引用
cout << "a: " << a << endl;
cout << "ref1: " << ref1 << endl;
cout << "ref2: " << ref2 << endl;
// 修改其中一个引用的值,实际上是修改变量 a 的值
ref1 = 20;
cout << "After modifying ref1:" << endl;
cout << "a: " << a << endl;
cout << "ref2: " << ref2 << endl; // ref2 的值也变了,因为它引用的是同一个变量 a
return 0;
}6.3 引用的使用
6.3.1 引用作为函数参数
引用可以避免传递参数时的值拷贝,从而提高效率。
// 按引用传递
void increment(int &num) {
num++; // 修改原变量的值
}
int main() {
int x = 5;
increment(x); // 按引用传递
cout << "x = " << x << endl; // 输出 6
return 0;
}
函数 increment 修改的是 x 的原始值,而不是副本。
6.3.2 引用作为函数返回值
函数返回值可以是引用,用于修改调用者中的变量。
// 返回引用
int& larger(int &a, int &b) {
return (a > b) ? a : b;
}
int main() {
int x = 10, y = 20;
larger(x, y) = 30; // 修改较大值为 30
cout << "x = " << x << ", y = " << y << endl; // 输出 x = 10, y = 30
return 0;
}
函数 larger 返回的是变量的引用,因此可以直接通过函数结果修改变量。
6.4 传值, 传引用效率比较
传值与传引用在函数调用中的效率差异主要体现在拷贝开销上:
-
传值:在函数调用时会创建参数对象的拷贝,对于简单数据类型影响不大,但处理大对象或复杂数据结构时会占用更多内存并增加时间开销。
-
传引用:直接操作原始对象,无需额外的拷贝,函数内部对引用的修改会直接作用于原始对象,因此更加高效,特别是在处理复杂数据结构时表现尤为突出。
#include <iostream>
#include <ctime> // clock 函数头文件
using namespace std;
struct A {
int a[10000] = {0}; // 显式初始化
};
// 测试函数
void TestFunc1(A a) {} // 传值
void TestFunc2(A& a) {} // 传引用
void TestRefAndValue() {
A a;
// 测试传值
size_t begin1 = clock();
for (size_t i = 0; i < 10000; ++i)
TestFunc1(a);
size_t end1 = clock();
// 测试传引用
size_t begin2 = clock();
for (size_t i = 0; i < 10000; ++i)
TestFunc2(a);
size_t end2 = clock();
// 输出时间结果
cout << "Time taken by pass-by-value: "
<< (double)(end1 - begin1) / CLOCKS_PER_SEC << " seconds" << endl;
cout << "Time taken by pass-by-reference: "
<< (double)(end2 - begin2) / CLOCKS_PER_SEC << " seconds" << endl;
}
int main() {
TestRefAndValue();
return 0;
}
示例输出结果(取决于系统性能和环境):
Time taken by pass-by-value: 0.028 seconds
Time taken by pass-by-reference: 0.001 seconds
6.5 const引用
const 引用用于限制通过引用修改变量的行为。在函数参数中使用 const 引用不仅可以防止参数被修改,还可以接受常量或临时对象作为输入。
6.5.1 const引用的作用
- 防止通过引用修改原变量
int main()
{
int a = 10;
const int& ra = a; // 非常量变量绑定到 const 引用
//错误:const 引用不能修改变量
ra++;
return 0;
}- 允许引用常量或临时对象
int main()
{
const int a = 10; // 定义一个常量
const int& ra1 = a; // const引用可以直接绑定到常量
const int& ra2 = a * 2; // a * 2 的结果是一个临时对象
// 临时对象的生命周期被延长到引用的作用域内
return 0;
}在 C++ 中,临时对象的生命周期会在语句结束时销毁,但如果使用 const 引用绑定临时对象,可以延长它的生命周期到引用的作用域结束。
6.5.2 常量引用与权限放大/缩小
引用的权限规则:权限可以保持不变(平移)或缩小,但不能放大。
- 缩小:普通引用可以绑定到与原类型兼容但权限更低的对象(如非
const绑定到const对象)。 - 不能放大:普通引用不能绑定到权限更高的对象(如
int&不能绑定到const int对象)。
#include <iostream>
void TestConstRef()
{
const int a = 10;
//int& ra = a; // 编译错误:a为常量,普通引用不能绑定
const int& ra = a; // 正确:const引用可以绑定常量
//int& b = 10; // 编译错误:字面量是常量
const int& b = 10; // 正确:const引用可以绑定字面量
double d = 12.34;
//int& rd = d; // 在类型转换中会产⽣临时对象存储中间值
const int& rd = d; // 正确:通过隐式类型转换绑定
}
6.6 指针与引用的对比
| 对比点 | 引用 | 指针 |
|---|---|---|
| 基本定义 | 是变量的别名,绑定到某个变量上 | 存储变量地址 |
| 初始化 | 定义时必须初始化并绑定 | 可以不初始化 |
| 绑定灵活性 | 初始化后无法重新绑定 | 可以随时指向其他变量 |
| 空值支持 | 无NULL引用 | 可以指向NULL |
sizeof行为 | 返回引用类型的大小(如int&等于int的大小) | 返回指针大小(32位4字节,64位8字节) |
| 自增操作 | 变量值增加 | 指针地址偏移一个类型大小 |
| 多级结构 | 不支持 | 支持多级指针(如int**) |
| 实体访问 | 编译器自动处理解引用操作 | 需要显式解引用(如*ptr) |
| 安全性 | 更安全,无法为空,绑定后不可更改 | 灵活性高,但容易产生空指针或悬空指针问题 |
可以看到,在汇编指令层面,其实并不存在引用的概念,上层的引用语法实际上是通过指针来实现的。

7. 内联函数
在C++中,内联函数是一种将函数代码直接插入到调用处的机制。与普通函数不同,内联函数在编译阶段展开,而不是像普通函数那样通过调用栈进行执行。这减少了函数调用的开销,适合于一些频繁调用且逻辑简单的函数。
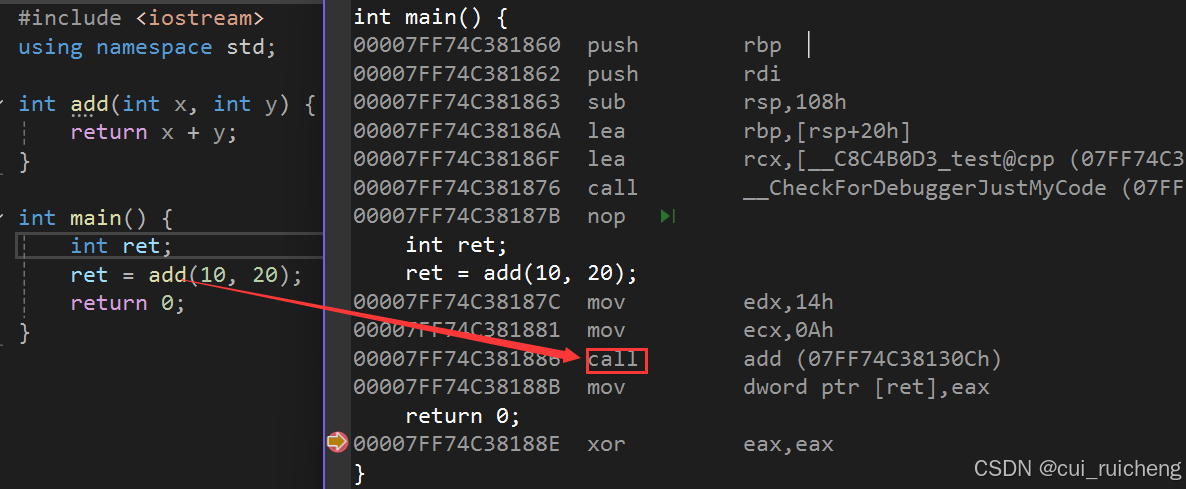
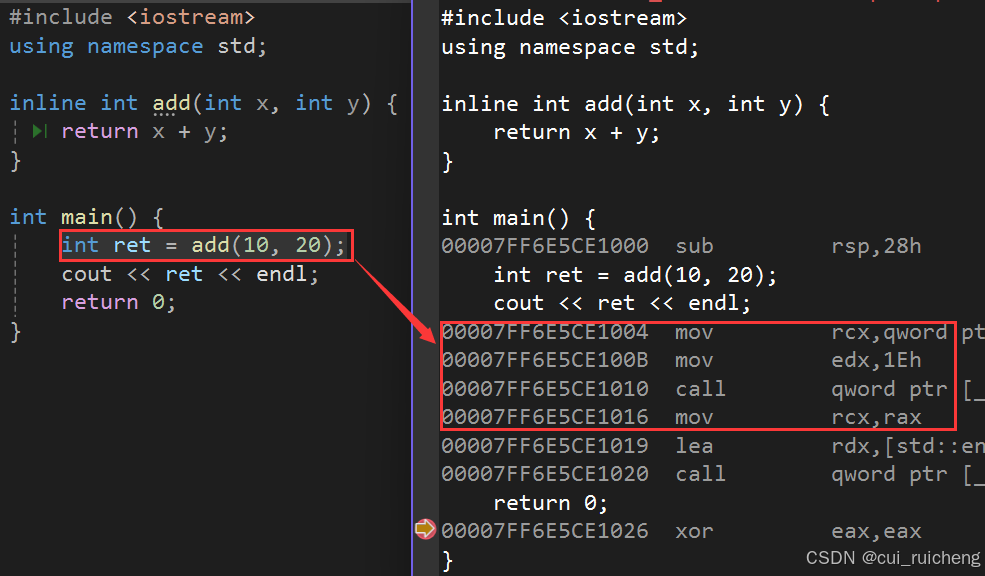
7.1 内联函数的特性
-
inline关键字对于编译器而言仅是一个建议,这意味着即使标注了inline,编译器也可能选择不在调用处展开。不同的编译器对inline的展开策略各不相同,因为C++标准对此并未作出明确规定。内联函数通常适用于频繁调用且代码较短的小型函数,而对于递归函数或代码较为复杂的函数,即使标注了inline,编译器也可能忽略这一建议。 -
不建议将
inline函数的声明和定义分离到两个文件中,因为这样可能导致链接错误。由于内联函数在调用处直接展开,不会生成独立的函数地址,因此在链接阶段可能找不到对应的函数实现,从而引发报错。为避免此类问题,应将inline函数的定义写在头文件中,确保调用处可以直接获得函数的完整实现。 -
虽然
inline函数可以减少函数调用的开销,但滥用可能导致代码膨胀(Code Bloat)。当标注inline的函数过大,或者被多次调用时,编译器在每个调用点展开代码会显著增加程序的体积。这不仅可能导致更高的内存占用,还可能因缓存命中率下降而降低运行效率。 -
与宏相比,
inline函数提供了类型安全性,并且能够在编译阶段进行完整的语法检查,这可以避免宏在替换过程中可能引发的错误。此外,inline函数在调试时能够保留调试信息,而宏仅仅是文本替换,难以追踪和调试。
8. 指针空值nullptr(C++11)
nullptr 是 C++11 引入的一个关键字,用于表示空指针。它取代了传统的 NULL,并提供了更强的类型安全性和更明确的语义
8.1 nullptr 与 NULL 的区别
在 C++11 之前,空指针通常使用 NULL 来表示。NULL 是一个宏,它的定义依赖于编译器和平台,通常为 0 或 (void*)0。下面是一个传统的 NULL 定义示例:
#ifndef NULL
#ifdef __cplusplus
#define NULL 0
#else
#define NULL ((void*)0)
#endif
#endif在这段代码中,首先检查是否已经定义了 NULL,如果没有定义,则根据编译器的语言环境进行不同的定义
- 对于 C++ 编译环境,
NULL被定义为0。 - 对于 C 编译环境,
NULL被定义为(void*)0,确保NULL是一个空指针常量
这种做法虽然能够兼容 C 和 C++,但是存在类型安全的问题。例如,在 C++ 中,NULL 的值是 0,这可能导致它与整数类型混淆,尤其在函数重载时可能会引发歧义。
void f(int)
{
cout << "f(int)" << endl;
}
void f(int*)
{
cout << "f(int*)" << endl;
}
int main()
{
f(NULL); // 由于NULL通常被定义为0,这里将调用f(int)
return 0;
}
程序本意是想通过f(NULL)调用指针版本的f(int*)函数,但是由于NULL被定义成0,因此与程序的初衷相悖
相比之下,nullptr 是一个独立的关键字,不是宏,专门用于表示空指针。它的类型是 std::nullptr_t,并且只能与指针类型进行比较,提供了更严格的类型检查。因此,使用 nullptr 可以避免因错误的类型转换而导致的潜在问题。
void f(int)
{
cout << "f(int)" << endl;
}
void f(int*)
{
cout << "f(int*)" << endl;
}
int main()
{
f(nullptr); // 调用f(int*),没有歧义
return 0;
}
8.2 总结:nullptr 的优势
-
类型安全:
nullptr的类型是std::nullptr_t,它只能与指针类型进行比较或赋值,避免了传统的NULL(定义为0)与整数类型发生隐式转换,避免了歧义。 -
更清晰的语义:
nullptr明确表示“空指针”,不像NULL可能被误用或误解为其他用途。它清晰地表达了意图,使代码更具可读性。 -
函数重载的帮助:
nullptr在函数重载时避免了NULL的歧义,使得编译器能够正确选择重载版本,特别是在同时存在指针和整数类型的重载时。 -
兼容性:
nullptr与传统的NULL和0兼容,并且可以与旧版 C++ 代码一起使用,同时能更好地支持 C++11 及以后的新特性。
总的来说,nullptr 是一个小而重要的特性,它在 C++ 中引入了更严格的类型检查,增强了程序的稳定性,避免了常见的空指针错误,因此在 C++ 编程中推荐使用 nullptr 来替代传统的NULL和 0
9 结语
本篇文章介绍了 C++ 中一些基础的语法特性。掌握这些基础语法是我们编写高效、清晰代码的第一步。尽管 C++ 是一门功能强大的语言,但只有通过不断实践和学习,我们才能真正掌握它。感谢您阅读这篇文章,希望它能帮助你在 C++ 学习的道路上走得更远。如果您有任何问题或反馈,欢迎在评论区留言一起探讨交流。非常感谢您的阅读!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









