




我是东哥,一名热爱技术的自媒体创作者。今天,我将为大家介绍一个非常有趣且强大的Python库——NLTK。无论你是刚刚接触Python的小白,还是对自然语言处理(NLP)有些许了解的朋友,NLTK都是一个值得学习的工具。
基本介绍
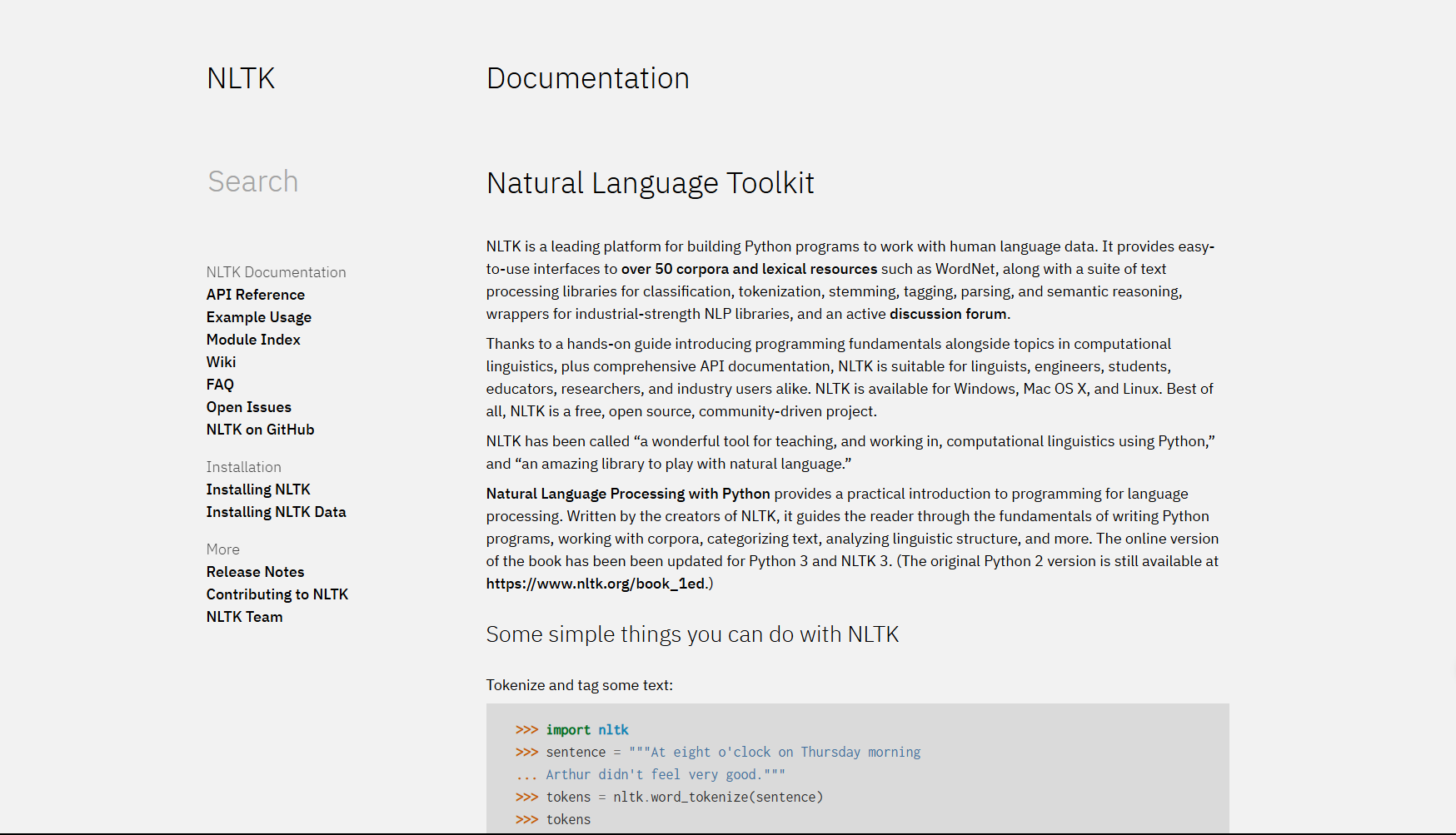
NLTK,全称Natural Language Toolkit,即自然语言处理工具包。它是一个用于构建Python程序以处理人类语言数据的平台。NLTK库包含了大量的语料库、词汇资源、分类器、语法分析器等,可以帮助我们进行文本分类、词性标注、命名实体识别、情感分析等各种自然语言处理任务。
项目地址:https://github.com/nltk/nltk
安装方法
安装NLTK非常简单,只需打开你的命令行工具,输入以下命令即可:
pip install nltk
安装完成后,你可以通过以下代码来下载NLTK的数据包,这些数据包包含了多种语料库和模型,是进行NLP任务的基础:
import nltk
nltk.download('all')
基本用法
让我们先从一些基础的例子开始,逐步揭开NLTK的神秘面纱。
案例1:分词
from nltk.tokenize import word_tokenize
# 示例文本
text = "Hello, how are you doing today?"
# 使用NLTK进行分词
tokens = word_tokenize(text)
print(tokens)
输出将会是文本被分割成单词和标点的列表,如下:
['Hello', ',', 'how', 'are', 'you', 'doing', 'today', '?']
案例2:词性标注
import nltk
from nltk.tokenize  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 900
900

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











