




作者简介
小琴,携程高级数据经理,负责酒店BI、数仓工作,专注于大数据应用领域多年。
一、背景
随着时间推移和业务的快速发展,携程酒店数据累积越来越多。目前流量日数据在3T左右,再加上各种订单、价、量、态等数据更是庞大。现有Hive(Spark引擎)执行速度虽然相对较快,但在国际化发展背景下,一些海外业务由于时差问题,数据需要比国内提前数小时完成,性能提升迫在眉睫。2020年初,我们开始研究ClickHouse在数据仓库领域应用。
本文将从技术方案选型、集成开发环境封装、ClickHouse代码优化技巧、异常问题处理、服务器故障处理五个方面分享ClickHouse实践,希望给关注同样问题的同学有所启发。
二、技术预研与技术方案选型
1)公司内部有无ClickHouse集群使用环境。经过了解知晓,原ClickHouse验证集群正准备下线,无可用环境;
2)办公电脑通过Vmware搭建ClickHouse集群,部分同学基于单机练习ClickHouse语法以及验证各项ClickHouse特性,部分专攻ClickHouse集群搭建及各项配置、集成开发环境的封装等底层功能。
3)2020年3月,Vmware搭建ClickHouse集群基本完成各项验证,同时4台物理服务器(配置:内存-256G,CPU-40core,硬盘-3.5T)到位。为保证对生产平稳过渡(不给生产DB造成额外压力),我们从Hive ODS层同步数据至ClickHouse ODS层,技术方案如下图1(橙色部分是ClickHouse实现部分):
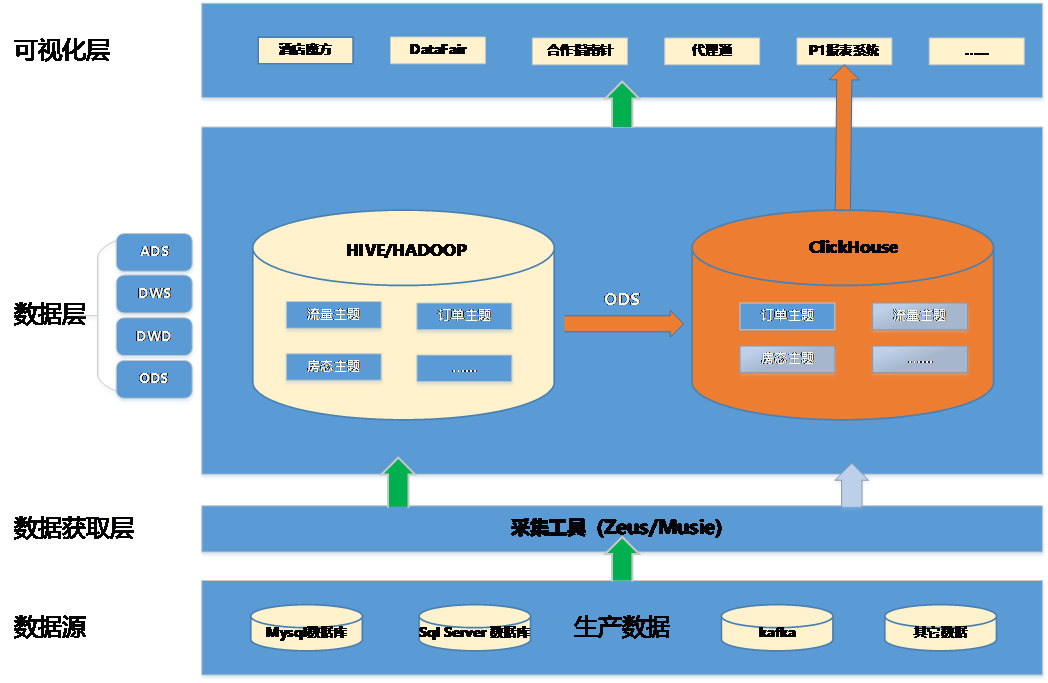
图1
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









