




作者简介
mczhao,携程资深软件工程师,关注自然语言处理、搜索引擎和数据库内核开发。
概览
随着线上旅游业务的不断发展,携程酒店的数据量不断增加,用户对于搜索功能的要求也在不断提高。携程酒店搜索系统是一个基于Lucene开发的类似Solar的搜索引擎系统,本文将从四个部分描述对搜索引擎的优化。
第一部分,通过优化存储来降低响应时延,提升用户体验,降低硬件成本。第二三部分,通过召回和纠错的智能化来提升用户体验。第四部分,通过重新设计搜索DSL提高业务灵活性和研发效率。本文也描述了在优化过程中遇到的各种问题和解决方法。
一、存储优化
1.1 数据压缩
在Lucene 8中,long型的数据会被自动压缩存储。我们可以去除搜索shema中原有的byte、short、int类型,对整型字段统一使用long类型存储,而不用担心其占用多余的空间。这既降低了对内存和磁盘的需求,也降低了运维的人力成本。
1.2 空间索引
在地理查询和存储这块,使用PointValues来替换原来的GeoHash索引。PointValues是从Lucene 6开始引入的一个新特性,使用kd树作为地理空间数据结构,来加速几何图形内点的过滤筛选。
踩过的坑
1)尽管Lucene官方极力宣传PointValues的性能优势,也许在二维地理搜索场景下是这样,但是在一维数据中其性能还是远逊于普通的倒排索引,甚至不如走逐个访问过滤。究其原因是PointValue中KD树的节点都是压缩存储,其CPU时间大部分消耗在对存储的解压和反序列化,造成浪费。
2)而对于高维空间的搜索,例如通过word2vec的词向量搜索某个词的相似词,无论是KD树还是VP树,其时间复杂度都会退化到不可忍受的地步。
1.3 KV存储
搜索流程不仅需要依靠倒排的索引,也需要正排的数据。在过滤和排序的搜索步骤中,需要根据主键来访问doc的一些维度信息,来判断该doc是否满足过滤条件,或者用来计算这个doc的排序分数。
在早期Solar版本中,使用了FieldCache——一种内存中SST来保存这些KV数据。从Lucene 4开始,DocValues作为KV数据的一种磁盘存储方案。在Lucene 7版本中,使用倒排索引中的DISI作为DocValues的索引,而FieldCache已经被移除。在Lucene 8版本中,DocVaues添加了jump table来增强其随机访问能力。
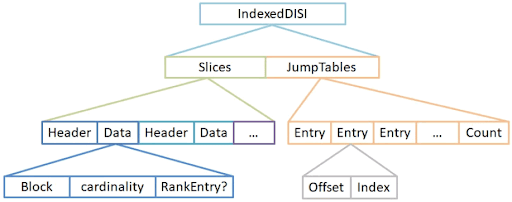
Lucene DocValues相对于FieldCache的优势是:
1)存储在磁盘,对内存需求减少。
2)存储经过压缩,消耗资源进一步减少。
Lucene内部的KV存储有一定局限性,例如:
1)使用磁盘的存储时,需要将byte数组反序列化,还是略慢于内存中直接存储的数据结构。
2)只能用docid作为key,如果使用业务id来访问,需要先查询倒排索引获取其docid,再访问正排数据获取值。
3)DISI存储的docid范围只能在32位整型内,当遇到单点几十亿级别的数据,就无法存储了。
在某些场景下,给酒店打排序分时,需要获取酒店到POI之间的关联分数,此类分数不仅仅是通过直线距离计算得来,还需要考虑驾车步行距离的时间,以及距离筛选的酒店点击量等等因素,所以需要一个酒店到POI之间关联的KV存储。酒店和POI数据量各自是百万级别,而一个POI周边的酒店数平均是千级别,这样他们之间关联数据条数可达数十亿。
为此,我们自研了一种Java内嵌KV存储,和Lucene的索引中"mmap"模式一样,利用JDK自带的MappedDirectedBuffer,将数据存储在磁盘上,将磁盘和内存的交换交给操作系统托管,也不会给堆内存造成压力。不同于Lucene的DISI和LevelDB的SST,考虑到减少磁盘和内存的交换,已经提高TLB的命中率,其索引是固实化(compacted)的BTree,也就是一棵用数组表示的完全n叉树,其查询的时间复杂度为对数,索引合并时间复杂度为线性。相比使用排序数组的SST,空间占用一样,优势是查询时内存页跳转减少,劣势是compact的时候需要随机访问磁盘,而不是顺序访问。
踩过的坑
1)虽然Lucene DocValues是一种磁盘存储,但由于其实现和FieldCache有着诸多相似特性,部分元数据甚至是数据本身还是
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3045
3045




 到【灌水乐园】发言
到【灌水乐园】发言







