




 本文介绍了Java中FileInputStream类的基本用途及常见操作方法,包括如何读取文件中的字节数据,并展示了不同方法的应用实例。
本文介绍了Java中FileInputStream类的基本用途及常见操作方法,包括如何读取文件中的字节数据,并展示了不同方法的应用实例。
一:前置介绍
●从文件系统中的某个文件中获得输入字节,例如文档复制时候,文件输入流主要负责“读取”文件,获得文件输入流;
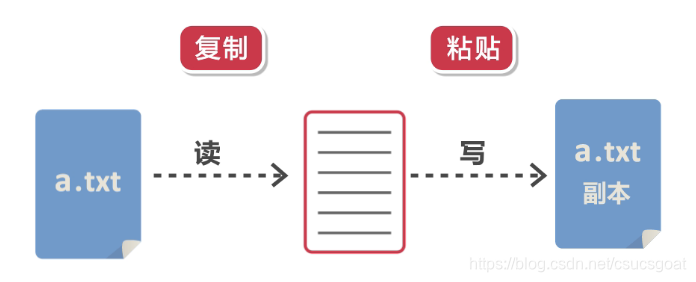
●用于读取诸如图像、图片数据之类的原始字节流(如视频图像和图片数据是二进制的数据,字节流一般用于读取这类的二进制数据;而一般读文档等内容是字符串的数据时,一般不使用字节流,而是使用字符流去读取文档)
二:FileInputStream类常用方法简介
FileInputStream类简介:
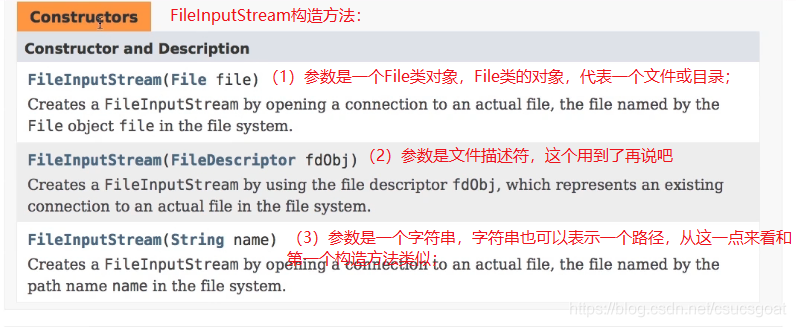
常用方法:

public int read():从输入流中读取一个字节数据,也就是读取一个整数;该返回值int,就是读到什么返回什么,即把读到的数据返回;返回值-1:已经读到了文件末尾;
public int read(byte[] b):用这个方法之前,需要事先定义一个byte类型的数组,好把读到的数据存到这个数组中;返回值为-1:已经读到了文件末尾;
public int read(byte[] b,int off,int len):off:从什么位置处开始存放,又称偏移量?
public void close():关闭输入流,释放资源;
三:FileInputStream类常用方法范例:
(1)public int read():读取文件的一个字节,返回该字节对应的整数值:
public class FileInputDemo1 {
public static void main(String[] args) {
// TODO Auto-generated method stub
// (1)创建文件输入流对象,(建立访问文件的一个"通道");
// (2)因为imooc.txt在工程根目录,所以这儿直接用相对路径访问了;其中,imooc.txt的内容为:Hello,imooc!
// (3)访问文件时文件可能不存在,所以必须处理FileNotFoundException异常;
try {
FileInputStream fis = new FileInputStream("imooc.txt");
int n = fis.read();
System.out.println(n);
fis.close();
} catch (FileNotFoundException e) { // FileNotFoundException是IOException的子类;对于catch来说,子类必须写在上面;
// TODO Auto-generated catch block
e.printStackTrace();
}catch(IOException e){ // int n = fis.read();这条语句会抛出I/O异常,这儿处理了一下
e.printStackTrace();
}
}
}
输出:
72
public int read()方法返回的是读取到的字节的整数;上述程序,将方法返回的int值装换成char后输出即:System.out.println((char)n);
输出结果:即为,imooc.txt的第一个字母H
H
public int read()循环读取文件内容:
public class FileInputDemo1 {
public static void main(String[] args) {
// TODO Auto-generated method stub
// (1)创建文件输入流对象,(建立访问文件的一个"通道");
// (2)因为imooc.txt在工程根目录,所以这儿直接用相对路径访问了;其中,imooc.txt的内容为:Hello,imooc!
// (3)访问文件时文件可能不存在,所以必须处理FileNotFoundException异常;
try {
FileInputStream fis = new FileInputStream("imooc.txt");
int n = 0;
while((n = fis.read())!= -1){
System.out.println((char)n);
}
fis.close();
} catch (FileNotFoundException e) { // FileNotFoundException是IOException的子类;对于catch来说,子类必须写在上面;
// TODO Auto-generated catch block
e.printStackTrace();
}catch(IOException e){ // int n = fis.read();这条语句会抛出I/O异常,这儿处理了一下
e.printStackTrace();
}
}
}
输出结果:可以发现public int read()方法是,每次读一个字节;一个英文字母占一个字节,很ok,不会出现乱码,但如果imooc.txt中的内容为中文是怎样的?见下面
H
e
l
l
o
,
i
m
o
o
c
!
如果imooc.txt中的内容为中文时,其输出结果是:很显然出现了,乱码,英文一个中文字至少占两个字节;

?
?
?
?
?
?
?
?
?
?
°
?
?
?
?
?
?
?
?
?
?
(2)public int read(byte[] b):用这个方法之前,需要事先定义一个byte类型的数组,好把读到的数据存到这个数组中;返回值为-1:已经读到了文件末尾;
实际使用的时候,如何满足业务需求,可能需要编写一下辅助的逻辑代码,以更好地应用这个read()方法。
public class FileImputStreamDemo2 {
public static void main(String[] args) {
// TODO Auto-generated method stub
try {
FileInputStream fis = new FileInputStream("imooc.txt");
byte[] b = new byte[100];
fis.read(b);
// new String(b):将字节数组转成字符串;
System.out.println(new String(b));
fis.close();
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e){
e.printStackTrace();
}
}
}
输出结果:
Console显示:

实际将输出结果copy后,后面的正方形没了:这是因为上面的程序中,byte数组定义长度为100,而imooc.txt中只有12个字符,所有byte数组中有88位的值是null的缘故吧。
Hello,imooc!
注:当imooc.txt内容改成中文后,如果项目编码方式为GBK的时会出现乱码;项目编码为utf-8时正常输出中文;
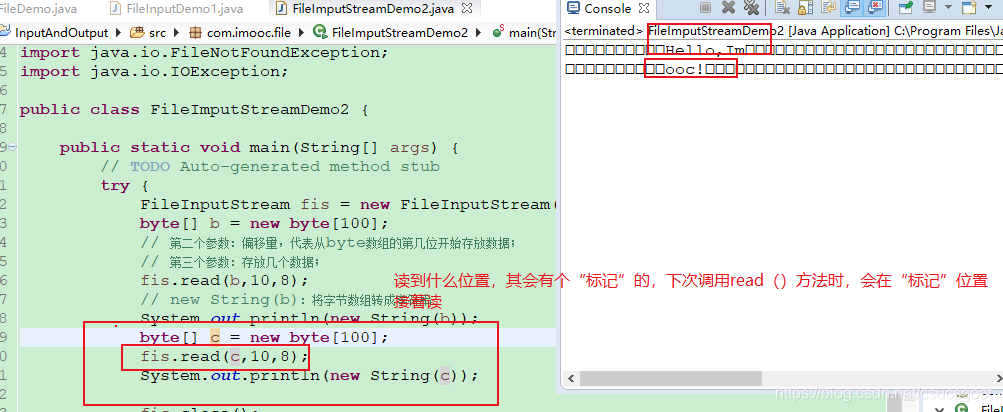
(3)public int read(byte[] b,int off,int len):off:从什么位置处开始存放,又称偏移量;
public class FileImputStreamDemo2 {
public static void main(String[] args) {
// TODO Auto-generated method stub
try {
FileInputStream fis = new FileInputStream("imooc.txt");
byte[] b = new byte[100];
// 第二个参数:偏移量,代表从byte数组的第几位开始存放数据;
// 第三个参数:存放几个数据;
fis.read(b,10,8);
// new String(b):将字节数组转成字符串
System.out.println(new String(b));
fis.close();
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e){
e.printStackTrace();
}
}
}
输出结果:可以,因为偏移量设成了10,所以,字节数组的第0到第9位的值位null,第三个参数设成了8,即本次只读8位;(如果想继续读的化,就继续调用read方法了)

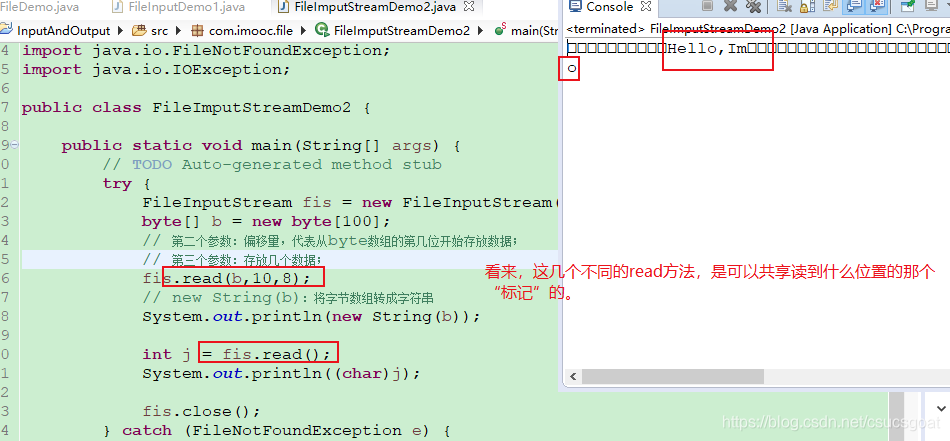

















 915
915

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









