




 网友常将业务QQ收到的病毒木马样本转发分析。此次样本是“截图.zip”压缩包,解压后有快捷方式和隐藏目录。经分析,这是利用覆盖SEH漏洞的音乐播放器,投毒方式虽简单但免杀效果好。手动运行样本,其动态行为包括拷贝软件、创建启动项、开启键盘记录并注入木马。
网友常将业务QQ收到的病毒木马样本转发分析。此次样本是“截图.zip”压缩包,解压后有快捷方式和隐藏目录。经分析,这是利用覆盖SEH漏洞的音乐播放器,投毒方式虽简单但免杀效果好。手动运行样本,其动态行为包括拷贝软件、创建启动项、开启键盘记录并注入木马。
一个网友跟我说,他们的业务qq经常收到各种病毒木马,每次收到后都会把样本转发给我,让我帮忙看看是什么木马!
这次他给我发来一个名为"截图.zip"的压缩包,通过qq传播时,也没报毒!
解压后,可以看到里面只有一个快捷方式,和一个隐藏的~目录
快捷方式的目标中,填写的是
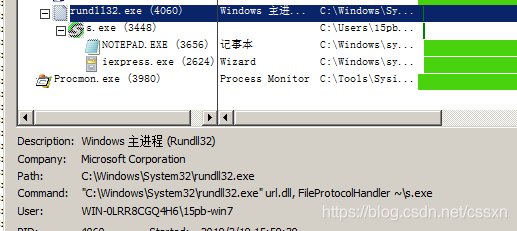
C:\Windows\System32\rundll32.exe url.dll, FileProtocolHandler ~\s.exe
双击快捷方式后,打开的是~目录下的s.exe,打开r ~目录,可以看到这是个正常的软件
简单看了一下,我在skin目录下发现了端倪
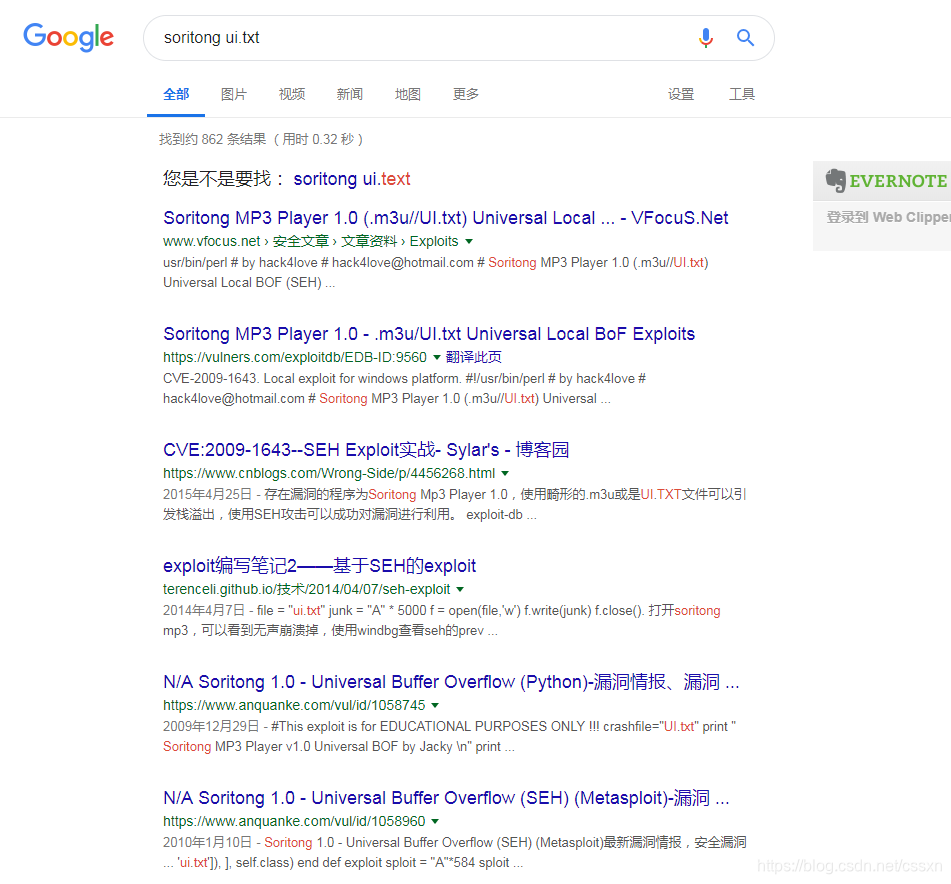
skin是这个软件的皮肤目录,对缓冲区溢出漏洞敏感的同学一眼就可以看出来,这ui.txt就是平时定位溢出点的pattern啊!!
这里就是溢出时覆盖的返回地址
通过对目录内几个文件的静态分析,找到关于这个软件名字的一些信息,并google了一下,发现这是一款音乐播放器,并且利用的漏洞的是覆盖SEH
见过这么多投毒方式,这投毒时发送个自带漏洞的软件,还是第一次见。。。
不过这种投毒方式虽然很low!但是免杀效果却很好!!!
现在手动运行一下这个样本看看,啥效果!
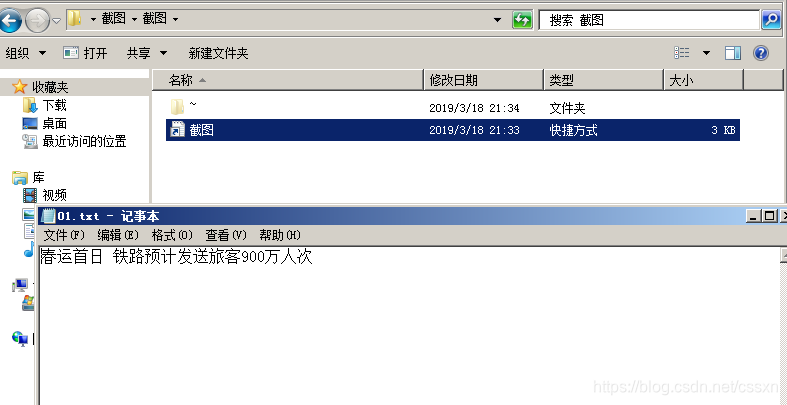
首次打开快捷方式的图标,发现弹出个程序加载的界面,然后立马退出了,然后打开了目录下的01.txt,用来迷惑用户这是正常的软件
但是Procmon抓的的日志可不止这些,快捷方式
可以看到动态行为显示如下:
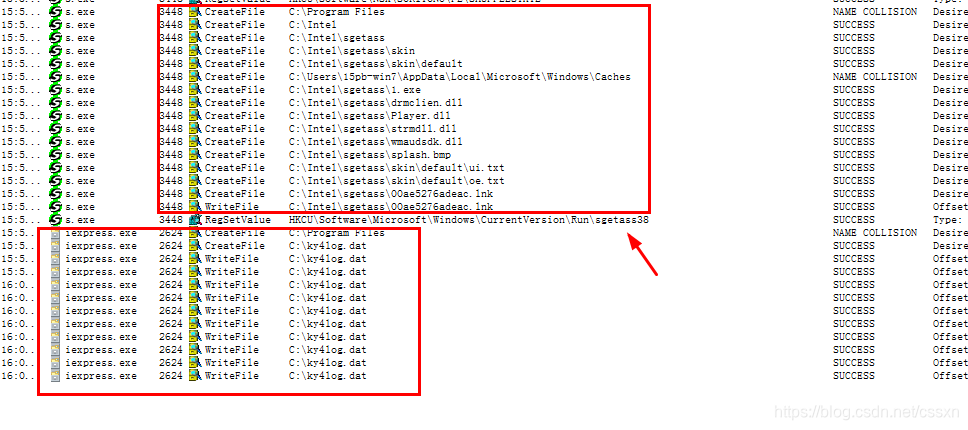
1)先把自己所有目录下的软件拷贝到 C:\Intel\sgetass
然后创建启动项
注册表启动项
HKEY_CURRENT_USER\Software\Microsoft\Windows\CurrentVersion\Run\sgetass38
启动项内容
C:\Windows\System32\WindowsPowerShell\v1.0\powershell.exe -nop -W hidden C:\Intel\sgetass\00ae5276adeac.lnk
开启键盘记录,每按一次键盘,就触发一次写入事件
通过文件映射的方式,把键盘记录木马注入到iexpress.exe进程中

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









