



搜索引擎技术:概要
01:搜索引擎的基本概念
基础知识
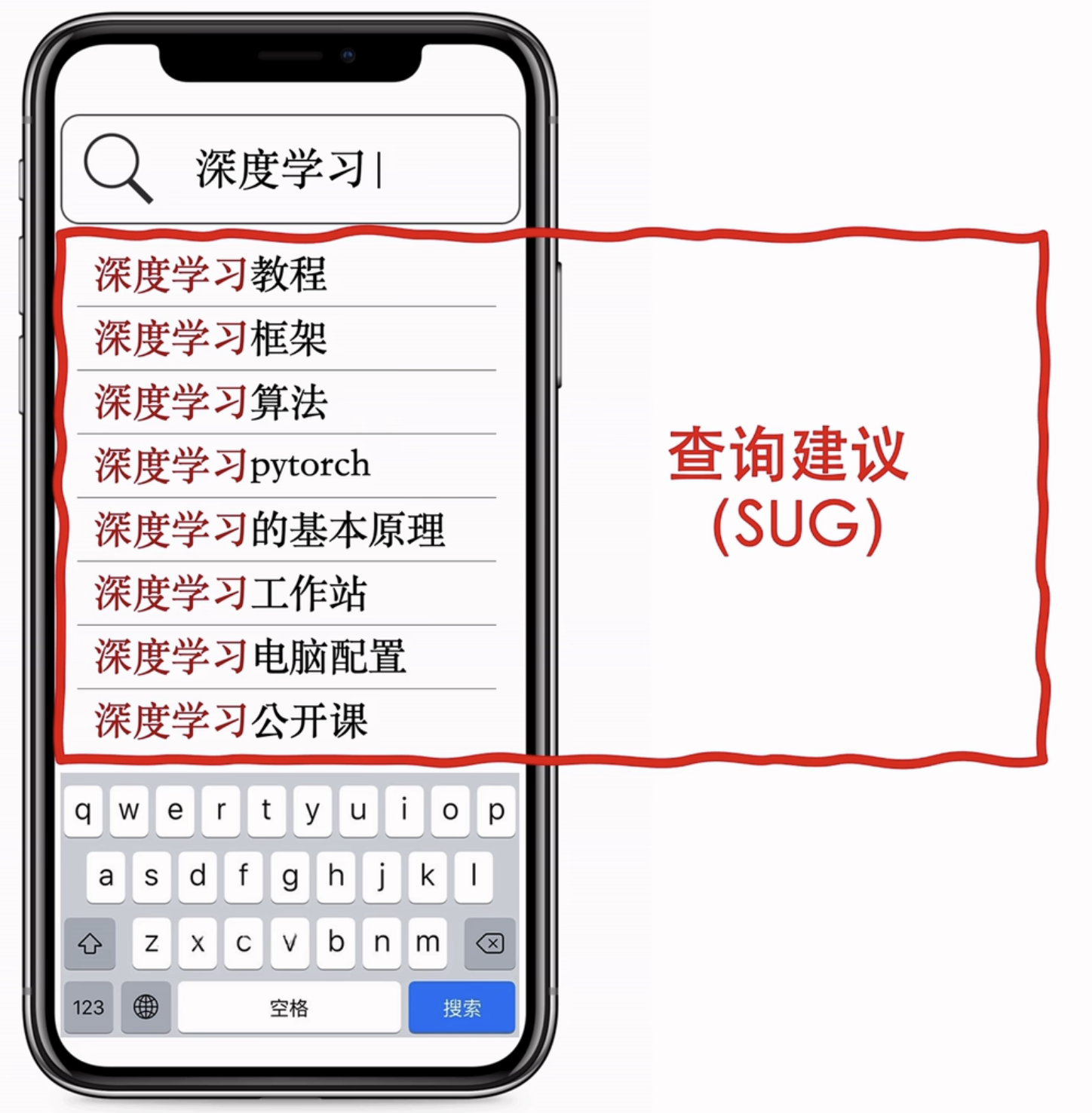
查询词:深度学习-点击搜索就会出发搜索
查询建议SUG:让搜索引擎变得更加方便

文档:点击搜索后的搜索结果,百度谷歌的文档是网页链接,亚马逊淘宝的文档是商品,优酷b站的文档是视频。
搜索完成后的整个页面是搜索结果页
最新、最热、视频叫做标签/筛选项 点击不同的标签会文档排序会发生变化,主要以点击和交互次序发生变化。搜索结果页的主体是搜到的文档,有标题、摘要等预览。
单列曝光&双列曝光:展示区别,后台搜索引擎算法是一样的


曝光和点击
文档点击率(10%左右)
- 曝光:用户在搜索结果页上看到文档,就算曝光。 能否获得更多文档曝光,取决于用户是否下滑搜索结果页
- 文档点击:在曝光之后,用户点击文档,进入文档的详情页。
- 文档点击率: 文档点击总次数 / 文档曝光总次数 文档点击总次数/文档曝光总次数 文档点击总次数/文档曝光总次数-和推荐系统相同,独立看待每一篇文档的点击。
查询次词点击率(有点比)(70%左右)
- 查询词点击:用户点击搜索结果页上任意一篇文档,就算“查询词点击”。
- 点击1篇文档和n篇文档都算一次查询次点击
- 查询词点击率(有点比): 查询次点击总次数 / 搜索总次数 查询次点击总次数/搜索总次数 查询次点击总次数/搜索总次数。(<=1)
- 查询词首屏点击:用户点击搜索结果页首屏的任意一篇文档,就算“查询词首屏点击”。
- 区分查询词点击和查询词首屏点击:点击文档1-3下面的文档4算查询词点击而不算首屏点击
- 查询词首屏点击率(首屏有点比)(60%左右): 查询词首屏点击总次数 / 搜索总次数 查询词首屏点击总次数/搜索总次数 查询词首屏点击总次数/搜索总次数。(<=1, 小于有点比)
为什么要研究首屏有点比呢?
有点比和首屏有点比非常相似,都可以反映用户有没有找到需要的文档,但是首屏有点比要求更严格,让用户需要的文档出现在首屏,用户更快达到目的,用户体验会更好。
搜索排序做的好,用户需要的文档会排在前面
垂搜vs通搜
垂直搜索
- 垂直搜索(垂搜):针对一个行业的搜索引擎(电商(淘宝)、学术(知网)、本地生活(美团)等)
- 垂直搜索的文档普遍是结构化的,容易根据文档属性标签做检索筛选
- 电商限制品牌or卖家等;学术 搜索限定作者、年份等
- 垂搜用户的意图明确
- 美团用户搜索‘寿司’,目的是找餐厅;淘宝用户搜‘拳击’,目的是找拳击相关的商品
通用搜索
- 通用搜索(通索):覆盖面广,不限于一个领域(eg:谷歌、百度、抖音…)
- 文档来源广,覆盖面大(eg:网页、视频、图片…)
- 没有结构化,检索难度大
- 用户使用😓搜的目的各不相同,较难判断用户意图。
- 本课程主要研究通搜

02:搜索引擎的用户满意度

用户满意度
- 影响用户满意度的三大因素:相关性、内容质量、时效性。
- 移动互联网时代、个性化、地域性也会影响用户满意度
- 通用搜索引擎迭代优化的目标是让用户更满意。
- 如何让用户更满意:提升相关性、内容质量、时效性、个性化。
- 评价用户体验:留存、有点比等客观指标;人工评估的主观指标。
相关性(Relevance):评价用户满意度最重要的指标
相关性
- 相关性是查询词 q q q与文档 d d d两者的关系。
- 相关性是客观标准,不取决于用户
u
u
u。(如果大多数有背景知识的人认为
(
q
,
d
)
(q,d)
(q,d)相关,则判定为相关)
-相关性是语义上的,不是字面上的。(相关是指 d d d能满足 q q q的需求或回答 q q q提出的问题。) - 查询词q可能有多种意图。只要d命中q的一种主要意图,则(q,d)算相关。
- 农药玩家搜‘狄仁杰’搜索结果是历史人物,这是相关的,至于并不满足农药里的介绍,这是个性化的问题,而不是相关性的问题。
相关性模型
- 召回、粗排、精排均需要计算相关性。
- 召回完成后,候选文档量级为数万;召回海选阶段用文本分配分数或双塔 B E R T BERT BERT模型粗略地估计相关性。
- 粗排阶段候选文档量级为数千,用双塔 B E R T BERT BERT模型或浅层交叉 B E R T BERT BERT模型计算相关性。
- 精排阶段候选文档量级为数百,用交叉 B E R T BERT BERT模型计算相关性。
内容质量

EAT
- EAT 是谷歌提出的内容质量评价标准。-针对网站和作者
- 专业性(Expertise):作者有专业资质,比如医生、记者等。
- 权威性(Authoritativeness):作者、网站在领域内有影响力,不会被用户质疑。
- 可耐性(Trustworthiness):作者、网站的名声好坏
- 对于your money or your life 方面的查询词,EAT是排序的重要因子。

文本质量
-
被判定为低质量的文档应该被搜索引擎打压- 这三类负面信号针对的是文档本身

-
文本质量不是一个分数,而是很多个分数,在搜索排序中起作用。
-
对于每个文本质量分数,都有一个专门训练的模型。
- 模型:BERT等NLP模型、CLIP等多模态模型。
- 数据:制定分档规则,然后人工标注。
- 先对模型做预训练,然后采用人工标注的数据Fanto。
-
在文档发布、或被检索时,用模型打分,分数存入文档画像。(搜索排序时直接读取文档画像。)
关于对模型进行预训练和采用人工Fanto的方法,有几个关键步骤和注意事项:
1. 预训练模型预训练模型通常涉及以下步骤:
-
数据收集和处理:收集大量的高质量数据,并进行清洗和处理,以确保数据的质量和多样性。
-
选择模型架构:选择适合任务的模型架构,例如GPT、BERT等。对于不同的任务,模型架构可能有所不同。
-
训练配置:设置模型的超参数,包括学习率、批量大小、训练轮数等。
-
训练模型:使用高性能计算资源(如GPU或TPU)进行模型训练。训练过程需要大量的计算资源和时间。
-
保存模型:训练完成后,保存模型的权重和配置,以便后续使用。
2. 人工Fanto
Fanto(Fine-tuning)是对预训练模型进行微调,以适应特定任务或领域。人工Fanto通常包括以下步骤:
-
准备微调数据:根据特定任务收集和处理微调数据。例如,对于文本分类任务,需要准备标注好的分类数据集。
-
加载预训练模型:加载预先训练好的模型权重和配置。
-
配置微调参数:设置微调的超参数,包括学习率、批量大小等。
-
微调模型:在特定任务的数据集上进行微调训练。微调过程中需要监控模型的性能,以避免过拟合。
-
评估模型:使用验证集或测试集评估微调后的模型性能,并进行必要的调整。
-
部署和应用:将微调后的模型部署到生产环境中,进行实际应用。
图片质量(或视频质量):-(有些搜索引擎会考虑到)
分辨率、有无水印、是不是截图、图片是否清晰、图片美学等
-
时效性
时效性定义
文档的年龄在排序中有一定的权重,权重的大小取决于查询词,查询词对时效的需求越强,文档年龄的权重就越大。
- 优化搜索时效性的关键是识别查询词的时效性意图(即查询词对“新”的需求)。
- 分类:突发时效性、一般时效性(分多个当问:强/中/弱/无)、周期时效性。
- 识别方法:数据挖掘、语义模型。
突发时效性
- 查询词涉及突发的新闻、热点事件。
- 如果查询词带有突发时效性,那么用户想看最近发布的文档。
- eg:“王力宏”:平时没有突发时效性,写小作文期间有突发时效性
- 识别方法:以数据挖掘为主
- 挖掘站内搜索量激增的查询词。
- 搜索站内发布量激增的关键词。
- 爬取其他网站的热词。
- 为什么不能用BERT等自然语言模型?
- 人擅长的也是深度学习擅长的,不借助新闻媒体,人无法判断突发时效性。
- 因此人和模型都没法根据查询词字面的意思判断是否关联某个突发事件,因此不能用模型,只能用数据挖掘来判断时效性。
一般时效性
- 只看查询词字⾯就可以判断时效性意图的强弱。(无需知道近期是否有⼤新闻。)
- 按需求强度分为 4 档:强、中、弱、无。
- 例:某品牌薅⽺⽑、黄⾦价格(时效性非常高),上海楼市新闻(中),在美国更新中国护照、单反相机测评(弱),苏联笑话、82版射雕(无)。
- 识别⽅法:BERT 等语义模型。
周期时效性
- 周期时效性:在每年特定时间表现为突发时效性,在其他时间表现为无时效性。
- 例:双⼗⼀、春晚⼩品、⾼考作⽂、奥斯卡。
- 可以不做任何处理。(当查询词表现出突发时效性时,会被算法挖掘到,算法基于挖掘到的数据做判断。)
- 识别:标注做规则匹配、数据挖掘识别周期时效性查询词。
个性化
个性化定义
- 考虑到不同⽤户有不同偏好,搜索引擎可以根据⽤户特征做排序,让搜索结果带有个性化(类似推荐系统)。(eg:移动端app用户都会登陆,可以记录偏好)
- ⽤预估点击率、交互率来衡量⽤户对⽂档的偏好。
- 结合相关性、内容质量、时效性、个性化(预估点击率和交互率)等因⼦对候选⽂档排序
为什么需要个性化和点击率模型?
- why1:查询词的宽泛性使得搜索需要个性化,越精确越不需要个性化。
- why2:预估点击率和交互率有利于提升相关性和内容质量。
- 相关且高质的文档更容易与用户发生交互 (用户的行为告诉了搜索引擎哪篇文档更好的满足需求)
- 点击率模型与BERT等语言模型互补,解决搜索结果页上的bad case。
- 即便是⾮个性化排序,也会⽤模型预估点击率和交互率(用户对相关性和内容质量的投票),有助于提升排序效果。
03:搜索引擎的评价指标
- 总结3指标

北极星指标:用户规模&留存
用户规模(DAU)
- ⽇活⽤户数(Daily Active User,DAU)。
- 搜索⽇活(Search DAU),推荐⽇活(Feed DAU)。
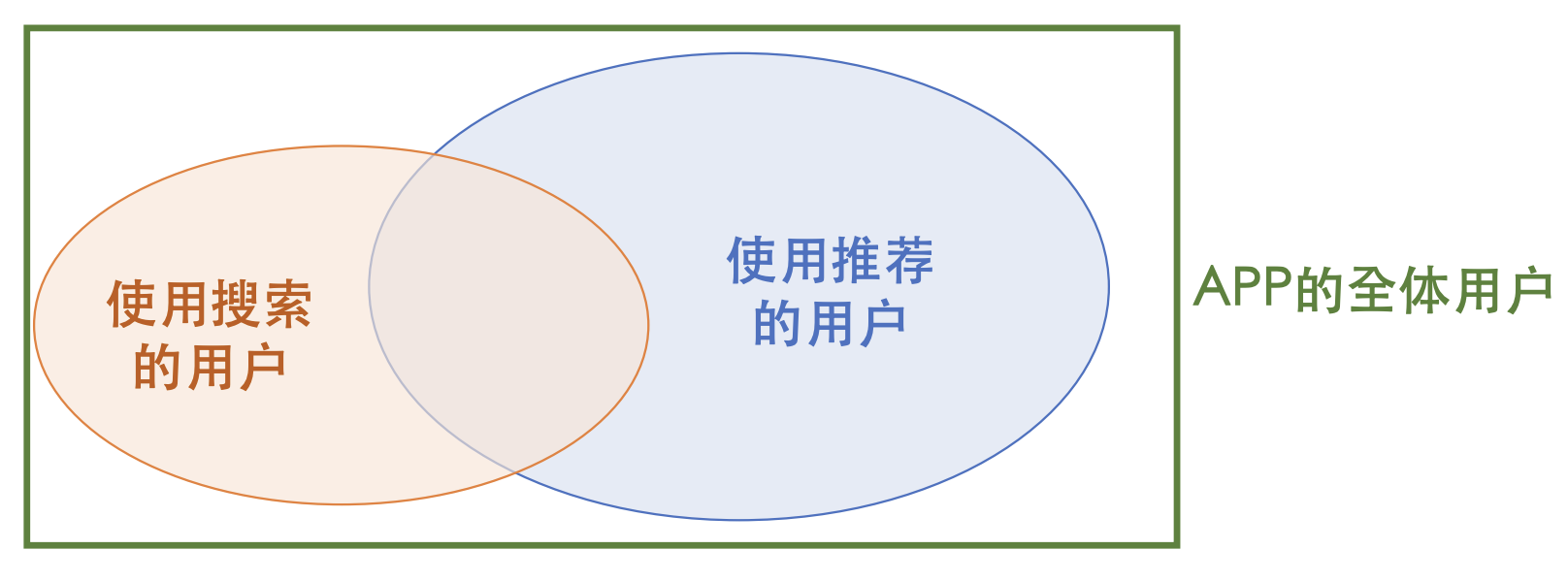
- 搜索⽇活(Search DAU),推荐⽇活(Feed DAU)。
- 搜索渗透率 = Search DAU / DAU。搜索体验越好,⽤户越喜欢⽤搜索功能,则搜索渗透率越⾼。
- 提升搜索⽇活、搜索渗透率的⽅法:
- 搜索的体验优化,可以提升搜索留存,从⽽提升搜索⽇活。
- 产品设计的改动,从推荐等渠道向搜索导流,推荐用户更频繁的使用搜索能提升搜索渗透率,从⽽提升搜索⽇活。
- 提升搜索⽇活、搜索渗透率的⽅法:
用户留存
- 次7留举例

- 常用留存指标:次 n n n留(随 n n n单调递增)
- 多功能app拆分看:次 n n n留,搜索次 n n n留,推荐次 n n n留。
- 现在更流行LT7和LT30留存指标。
中间指标:点击等行为
北极星指标提升比较难,搜索引擎可用中间指标来迁移技术和迭代的优化。中间指标易于在A/B test中显示出来。
点击率&有点比
- 三者之间有关联性,但也不是绝对关联的。
- 改进排序策略通常会同时提升三种指标
- 改进召回策略提升文档点击率、有点比,但很难提升首屏有点比,因为首屏的文档主要由排序决定

首点位置
- 平均首点位置:
- 一次搜索之后,记录第一次点击发生的位置
- 如果没有点击,或者首点位置大于阈值 x x x,则首点位置取 x x x。
- 对所有搜索的首点位置取平均作为中间指标。
- 平均首点位置小,说明符合用户需求的文档排名靠前,用户体验好。
- 优化搜索排序,通常会同时改善有点比、首屏有点比、平均首点位置。三者与留存指标强相关。
主动换词率
- 用户没搜到需要的文档才会换词,换词率高是负面指标。(可能是个性化不够好or搜索引擎自动纠错能力差)
- 换词:一定时间间隔内,搜的两个查询词相似(比如编辑距离小)
- 主动换词vs被动换词
- 被动换词:搜索引擎对查询词纠错,用户点击搜素引擎给出的建议查询词 (更加说搜索引擎更好)
- 主动换词:原因是没有找到满意的结果,说明搜索结果不好。
交互指标
- ⽤户点击⽂档进⼊详情页,可能会点赞、收藏、转发、关注、评论。
- 交互通常表明用户对文档非常感兴趣(强度大于点击),因此可以作为中间指标(类似于有点比、首点位置、换词率)。
- 问题:交互行为稀疏(每百次点击、只有10次点赞、2次收藏),单个交互率波动很大,而且在A/B测试中不容易显著。
- 总体交互指标:各种交互率的加权和,权重取决于交互率与留存的关联强弱。(波动小,A/B 测试中更容易显著)
中间指标➡️留存指标
- 算法工作:优化搜索体验:更好的理解查询词意图、对查询词作正确的改写、让召回变得更全面更相关、让相关性和点击预测率更准
- 体验优化的策略往往同时改善多种中间指标:有点⽐、⾸屏有点⽐、平均⾸点位置、主动换词率、交互指标。(中间指标比留存指标更容易在A/B测试显著(1-2天就显著))
- 单个体验优化的策略很难在短期内显著提升留存指标。(通常微弱上涨(可能一个月才显著),不具有统计显著性。)因此实验推全多用中间指标
- 上述中间指标与留存有很强的关联。长期持续改善中间指标,留存指标会稳定上涨。


















 10万+
10万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









