




 本文详细介绍了如何在Hive中使用动态分区进行数据组织,包括设置动态分区模式,创建分区表,以及通过SQL操作实现动态分区的创建和数据插入。重点展示了动态分区根据字段自动分区和overwrite操作的使用与理解。
本文详细介绍了如何在Hive中使用动态分区进行数据组织,包括设置动态分区模式,创建分区表,以及通过SQL操作实现动态分区的创建和数据插入。重点展示了动态分区根据字段自动分区和overwrite操作的使用与理解。
hive分区分为静态分区和动态分区。顾名思义,静态分区需要手动去添加分区信息,而动态分区可根据已有的字段信息来自动实现分区信息。
使用动态分区需要提前开启设置
--设置动态分区
set hive.exec.dynamic.partition=true;
--设置动态分区为非严格模式
set hive.exec.dynamic.partition.mode=nonstrict;创建一个分区表
create table if not exists partition_table1(
name STRING,
ip string
)partitioned by (day STRING,hour STRING)
row format delimited fields terminated by "\t";插入测试数据(由于这里只是为了学习动态分区,没有考虑表结构和字段信息以及数据之间的合理性,总之这些不影响不重要)
insert into table partition_table1 partition (day='22',hour='18') values
('beijing','192.168.20.222'),
('shanghai','192.168.70.111')
;
insert into table partition_table1 partition (day='22',hour='20') values
('beijing','192.168.20.222'),
('shanghai','192.168.70.111')
;再创建一个分区表,结构一致用来实现动态分区
create table partition_table2 like `partition_table1`;第一次动态分区:指定一个分区条件
insert overwrite table partition_table2 partition (day,hour)
select
*
from partition_table1
where day='22';结果: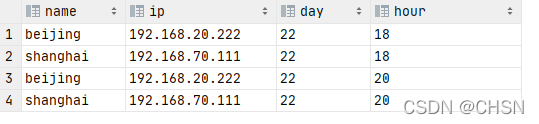
这里很明显实现了一天的动态分区,没有要我们手动指定具体的时间分区
第二次动态分区:指定到具体分区
insert overwrite table partition_table2 partition (day,hour)
select
*
from partition_table1
where day='22' and hour='18';结果:
第三次动态分区:(这里我们使用的是字段信息来分区)
insert overwrite table partition_table2 partition (day,hour)
select
name,
ip,
name,
ip
from partition_table1
where day='22' and hour='20';结果: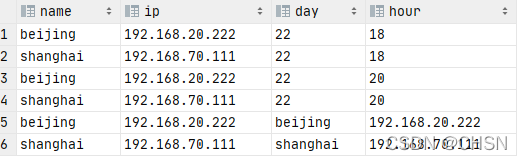
先看结果,overwrite为什么没起作用?其实不然,因为分区表overwrite的是指定分区的数据。
动态分区,它会首先去找你查询字段的最后位,将它定为分区(但是位数一定要对,分区是多出来的)使用*的话就会默认去和where条件的分区一致

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









