







一、 Python及其依赖包安装:
- 官网https://www.python.org/下载python2.7,直接双击安装包进行安装,然后配置系统环境变量的path变量,添加:
C:\install\Python\Python37 和 C:\install\Python\Python37\Scripts
在dos窗口中,执行python,可以看到提示信息:

表示安装成功;通过python -m pip list可以查看已经安装的pythonj包; - 安装matlpotlib、pandas、scipy、scikit-learn、xgboost
- 安装和使用IPython和IPython Notebook
(参考:https://blog.youkuaiyun.com/qq_37423198/article/details/76180905)
二、 jieba使用:参考
简介
"结巴"中文分词:做最好的Python中文分词组件
● 支持三种分词模式:
(1)精确模式:试图将句子最精确地切开,适合文本分析;
(2)全模式:把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义;
(3)搜索引擎模式:在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
● 支持繁体分词
● 支持自定义词典
Algorithm
● 基于Trie树结构实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图(DAG)
● 采用了动态规划查找最大概率路径, 找出基于词频的最大切分组合
● 对于未登录词,采用了基于汉字成词能力的HMM模型,使用了Viterbi算法
功能 1:分词
jieba.cut 方法接受两个输入参数: 1) 第一个参数为需要分词的字符串 2)cut_all参数用来控制是否采用全模式
jieba.cut_for_search 方法接受一个参数:需要分词的字符串,该方法适合用于搜索引擎构建倒排索引的分词,粒度比较细
(注意:待分词的字符串可以是gbk字符串、utf-8字符串或者unicode)
jieba.cut以及jieba.cut_for_search返回的结构都是一个可迭代的generator,可以使用for循环来获得分词后得到的每一个词语(unicode),也可以用list(jieba.cut(…))转化为list
demo
输出:
功能2:自定义词典补充
开发者可以指定自己自定义的词典,以便包含jieba词库里没有的词。虽然jieba有新词识别能力,但是自行添加新词可以保证更高的正确率
用法: jieba.load_userdict(file_name) # file_name为自定义词典的路径(出错!!!)
词典格式和dict.txt一样,一个词占一行;每一行分三部分,一部分为词语,另一部分为词频,最后为词性(可省略),用空格隔开
示例
功能 3:停用词词库补充
功能 4:词频统计
三、 python读写txt文件,并用jieba库进行中文分词
(matplotlib库,主要是用来绘图;jieba库,对文字进行分词;wordcloud库,构建词云。)
-
引入库

(注:加:import io) -
读取TXT文件
#定义一个空字符串
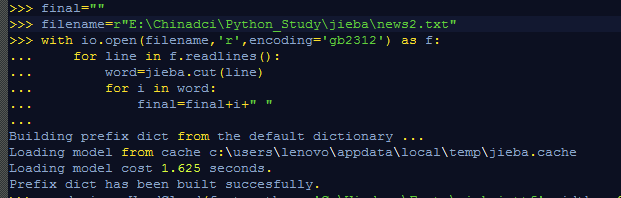
final = “”
#文件夹位置
filename=r"E:\Chinadci\Python_Study\jieba\news2.txt"
#打开文件夹,读取内容,并进行分词
with io.open(filename,‘r’,encoding = ‘gb2312’) as f:
for line in f.readlines():
word = jieba.cut(line)
for i in word:
final = final + i +" "
3. 构造词云
word_pic = WordCloud(font_path = r’C:\Windows\Fonts\simkai.ttf’,width = 2000,height = 1000).generate(final)
plt.imshow(word_pic)
<matplotlib.image.AxesImage object at 0x000000000BC13860>
#去掉坐标轴plt.axis(‘off’)
(-0.5, 1999.5, 999.5, -0.5)
#保存图片到相应文件夹plt.savefig(r’E:\Chinadci\Python_Study\jieba\7.png’)
- 结果(7、 8对比)

7

8
四、 变形(不构造词云,而是直接将分词结果打印出来):
#打开文件夹,读取内容,并进行分词:
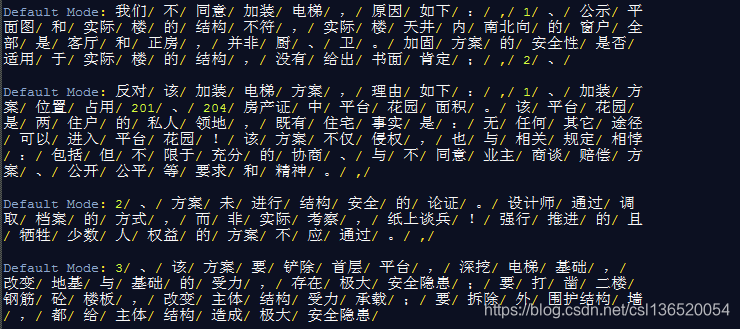
with io.open(filename,‘r’,encoding = ‘gb2312’) as f:
for line in f.readlines():
word = jieba.cut(line)
print("Default Mode: " + "/ ".join(word))

结果:
f=io.open(‘E:\Chinadci\Python_Study\jieba\news01.txt’,‘r’,encoding=‘utf-8’)
(参考链接:https://blog.youkuaiyun.com/CYJ2014go/article/details/85264016 https://blog.youkuaiyun.com/qq_30262201/article/details/80128076 https://blog.youkuaiyun.com/songrenqing/article/details/80541055)


















 448
448

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











