




 本文介绍了一种基于深度生成模型的方法,通过稀疏输入(如不到6%的像素)实现高质量图像重建和编辑。该方法利用轮廓与纹理之间的统计关联,分为两部分:一是重建整体图像结构和颜色;二是恢复纹理细节。实验结果表明,此方法在保真度和效果上具有优越性。
本文介绍了一种基于深度生成模型的方法,通过稀疏输入(如不到6%的像素)实现高质量图像重建和编辑。该方法利用轮廓与纹理之间的统计关联,分为两部分:一是重建整体图像结构和颜色;二是恢复纹理细节。实验结果表明,此方法在保真度和效果上具有优越性。
Sparse, Smart Contours to Represent and Edit Images
Abstract
By GAN, reconstruct images with high quality and fidelity from sparse input, e.g., comprising less than 6% of image pixels.
Introduction
This paper proposed a new method based on deep generative models to resolve the conflict between high fidelity and high sparsity. They trained the model to hallucinate appropriately according to the correlation between contours and textures. For instance, knowing that a contour map is of a person’s face, the model can fill in the details of hairs and facial expression based on the statistical correlation trained on a set of facial images. They divided the work into two parts. One is to reconstruct the overall image structures and colors. The other is to recover texture and finetuning.
Method
The model consists of two networks: LFN (“Low Frequency Network”) and HFN (“High Frequency Network”).
The LFN is trained with an L1L_1L1 pixel loss between the reconstructed output image and the ground-truth image. The HFN is conditioned on the sparse contours and the output of the LFN, and trained with a combination of piexl loss and an adversarial loss. Then they use a conditional discriminator to distinguish between the real image and the fake output of HFN.
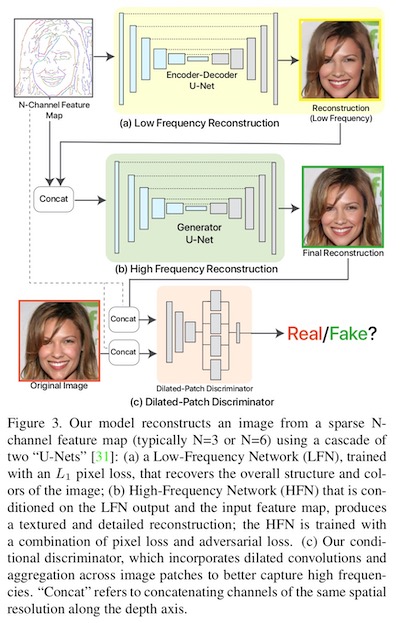
In fact, the LFN and HFN is a convolutional encoder and decoder without connections between layers of the encoder and decoder. The discriminator is a combination of a “patch discriminator” and a branch of dilated convolution filters that better capture higher frequencies.
Experiments
In experiments, they show “reconstruction” and “editing” respectively. For evaluation, they use human reters firstly to distinguish the real and fake image. Then, they use FaceNet to test the extent to which their reconstructed faces capture the identity of a person. Finally, they use texture-loss to evaluate the quality of their synthesized texture compared to the source image. Meanwhile, they show comparisons with two baselines.
Conclusion
The authors proposed a method to reconstruct image with high fildety and fine texture from sparse source image (about 6% pixels). Their model include two parts: LFN and HFN based GAN. The former reconstruct paradoxical contours while the latter finetuning the texture in details. Quantity experiments show that their method has superiority in both fildety and effectiveness.

















 665
665

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









