



Java处理图片提取目标文字DEMO
demo开始前开心一刻
作为一名菜鸟的码农,平时能借鉴前辈的代码绝不自己重写,日子过得倒也轻松。但今天收到通知,说是硬件测试出了问题,有200台设备需要手动录入系统。第一反应是懵的,转念一想:“用Excel批量导入应该很快吧,剩下的时间就能自由安排了,嘿嘿~”

理想很丰满,现实很骨感~测试组居然要求手动录入200多张图片,每张都要单独核对两个字段。两百多张啊!!!

逐张识别?手动录入?那得干到猴年马月啊,那我自由安排的时间呢?
不行不行,那能这样搞,咱是码农啊,代码干活才是真理,所以我就想着用代码处理图片,提取关键字段,生成excel文件,然后cv进到库里.反正要求是手动入库,你就说入没入库吧!
实现基础:Tesseract OCR引擎
然后,我开始在优快云上查阅了一堆前辈大佬们(太多了这里就不一一感谢了)的介绍和示例,发现在Java中提取图片中的文字,通常称为光学字符识别(OCR)。目前,Java中可以使用一些库来实现OCR功能,其中最常用的是Tesseract OCR引擎。Tesseract是一个开源的OCR引擎,由Google支持,可以识别多种语言的文字。
哎嘿嘿嘿嘿~案例存在,合理,开工!
实现方案:使用 Tesseract OCR + Tess4J(Java封装库)
实现优化
当然,很作前辈大佬们也有提到还有很多处理方法
1. 云服务 API(适合高精度需求)
Google Cloud Vision:
// 需添加 Google Cloud 客户端库
try (ImageAnnotatorClient client = ImageAnnotatorClient.create()) {
ByteString imgBytes = ByteString.readFrom(new FileInputStream("image.jpg"));
Image img = Image.newBuilder().setContent(imgBytes).build();
AnnotateImageResponse response = client.annotateImage(
AnnotateImageRequest.newBuilder()
.addFeatures(Feature.newBuilder().setType(Type.TEXT_DETECTION))
.setImage(img)
.build());
System.out.println(response.getFullTextAnnotation().getText());
}
类似服务:Azure Cognitive Services、Amazon Textract。
2. 其他开源库
Asprise OCR(商业免费版可用):
OCR.setup(); // 初始化
String result = new OCR().recognize("image.png");
OpenCV 预处理 + Tesseract(复杂图像需预处理增强效果)。
后话:本菜鸟在demo运行之后,由于解析有点问题想使用OpenCV 预处理,希望能增强图片识别,但是弄不下那些依赖之类的,所以失败了,有知道的大佬希望能不吝指导
demo开始
第一步:安装依赖
下载 Tesseract OCR 引擎:安装包(Windows/Mac/Linux)
第二步:添加 Tess4J Maven 依赖:
<dependency>
<groupId>net.sourceforge.tess4j</groupId>
<artifactId>tess4j</artifactId>
<version>5.3.0</version> <!-- 检查最新版本 -->
</dependency>
第三步:下载语言数据包
-
从 tessdata 下载所需语言(如 eng.traineddata、chi_sim.traineddata 中文简体)
-
将文件放入 Tesseract 的 tessdata 目录(如 C:\Program Files\Tesseract-OCR\tessdata):这里我就不放在那个目录下了,直接放在最后程序打包之后的jar包同级别的目录下面就行,demo直接读取.
-
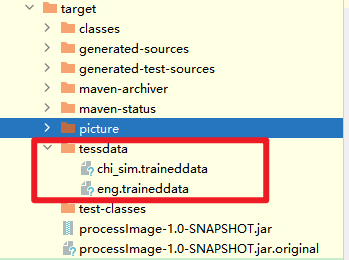
第四步:Java-tessdata初始化示例
// jar包同级目录的testdata路径
Tesseract tesseract = new Tesseract();
// 设置 tessdata 路径为 JAR 同级别的 tessdata 文件夹
tesseract.setDatapath(jarDir + File.separator + "tessdata");
// 设置语言(简体中文+英文)
tesseract.setLanguage("chi_sim+eng");
实现思路:读文件->处理图片->提取文字->存到excel->手动CV入库
所有需要的的资源全部都放到jar包统同级别的目录下去,tessdata资源和要处理的图片picture
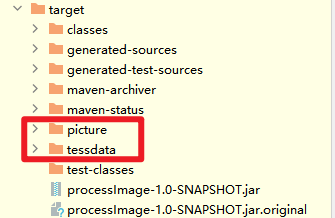
demo分三步走:
准备环境和所需要的工具:在jar同级目录下读取资源
图片处理:
- ①内存中处理图片
- ②执行OCR过程
- ③提取目标字段
- ④验证并格式化数据
- ⑤验证结果
写入excel表
demo代码
import net.sourceforge.tess4j.Tesseract;
import org.apache.poi.ss.usermodel.Row;
import org.apache.poi.ss.usermodel.Sheet;
import org.apache.poi.ss.usermodel.Workbook;
import org.apache.poi.xssf.usermodel.XSSFWorkbook;
import javax.imageio.ImageIO;
import java.awt.*;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* className: ImageService
* @Author csggogo4j
* @Create 2025/06/14_23:37
* @Version 1.0
*/
public class ImageService {
public static void main(String[] args) throws Exception{
//获取当前jar包路径
File jarDir = new File(ImageService.class.getProtectionDomain().getCodeSource().getLocation().toURI()).getParentFile();
// 图片dir跟jar包下的picture
File pictureDir = new File(jarDir, "picture");
// jar包同级目录的testdata路径
Tesseract tesseract = new Tesseract();
// 设置 tessdata 路径为 JAR 同级别的 tessdata 文件夹
tesseract.setDatapath(jarDir + File.separator + "tessdata");
// 设置语言(简体中文+英文)
tesseract.setLanguage("chi_sim+eng");
File[] imageFiles = pictureDir.listFiles((d, name) -> name.endsWith(".png") || name.endsWith(".jpg") || name.endsWith(".jpeg"));
if (imageFiles == null || imageFiles.length == 0) {
throw new Exception("没有找到图片!");
}
List<String[]> results = new ArrayList<>();
List<String> failedImages = new ArrayList<>();
for (File image : imageFiles) {
System.out.println("正在处理图片:" + image.getName());
try {
// 1. 直接在内存中处理图像
BufferedImage processedImage = enhancedPreprocessInMemory(image);
if (processedImage == null) {
System.out.println("❌ 图像预处理失败,跳过: " + image.getName());
failedImages.add(image.getName());
continue;
}
// 2. 执行OCR
long startTime = System.currentTimeMillis();
String resultText = tesseract.doOCR(processedImage);
long endTime = System.currentTimeMillis();
System.out.println("OCR耗时: " + (endTime - startTime) + "ms");
// 3. 提取设备ID(MAC地址)和NFCId
String deviceId = extractDeviceId(resultText);
String nfcId = extractNfcId(resultText);
// 4. 验证并格式化设备ID
if (deviceId != null) {
deviceId = formatDeviceId(deviceId);
}
// 5. 结果验证
if (deviceId != null && nfcId != null) {
results.add(new String[]{image.getName(), deviceId, nfcId});
System.out.println("✅ 提取成功: 设备ID=" + deviceId + ", NFCid=" + nfcId);
} else {
System.out.println("❌ 提取失败: " + image.getName());
System.out.println("可能原因: " +
(deviceId == null ? "设备ID未识别" : "") +
(nfcId == null ? " NFCid未识别" : ""));
// 保存OCR结果到文件以便分析
saveOcrResult(image.getName(), resultText);
failedImages.add(image.getName());
}
} catch (Exception e) {
System.out.println("❌ 处理失败: " + image.getName());
e.printStackTrace();
failedImages.add(image.getName());
}
}
// 生成Excel
writeExcel(results);
// 生成失败报告
if (!failedImages.isEmpty()) {
generateFailureReport(failedImages);
}
}
/**
* 提取设备ID(MAC地址)
*/
public static String extractDeviceId(String text) {
// 主匹配模式:设备ID后面跟着MAC地址格式
Pattern pattern = Pattern.compile("设[\\s::]*备[\\s::]*ID[\\s::]*(.{12,17})");
Matcher matcher = pattern.matcher(text);
if (matcher.find()) {
String rawId = matcher.group(1);
System.out.println("原始设备ID: " + rawId);
return formatDeviceId(rawId);
}
// 备用匹配:全局搜索MAC地址格式
Pattern fallbackPattern = Pattern.compile("([0-9A-Fa-f]{1,2}[:\\s-]{0,3}){5}[0-9A-Fa-f]{1,2}");
Matcher fallbackMatcher = fallbackPattern.matcher(text);
if (fallbackMatcher.find()) {
return formatDeviceId(fallbackMatcher.group());
}
return null;
}
/**
* 格式化设备ID为标准MAC地址格式
*/
public static String formatDeviceId(String rawId) {
// 1. 移除非十六进制字符
String cleanId = rawId.replaceAll("[^0-9A-Fa-f]", "");
// 2. 检查长度(MAC地址应为12个字符)
if (cleanId.length() < 12) {
// 尝试补全(例如补0)
cleanId = String.format("%-12s", cleanId).replace(' ', '0');
System.out.println("⚠️ 设备ID长度修正为: " + cleanId);
} else if (cleanId.length() > 12) {
// 截断超长部分
cleanId = cleanId.substring(0, 12);
System.out.println("⚠️ 设备ID截断为: " + cleanId);
}
// 3. 格式化为标准MAC地址 (XX:XX:XX:XX:XX:XX)
StringBuilder formatted = new StringBuilder();
for (int i = 0; i < 12; i += 2) {
if (i > 0) formatted.append(":");
formatted.append(cleanId.substring(i, i + 2));
}
return formatted.toString().toUpperCase();
}
/**
* 提取NFCId
*/
public static String extractNfcId(String text) {
// 主匹配模式:更灵活的格式匹配
Pattern pattern = Pattern.compile(
"NFC[\\s::]*" + // NFC开头
"I[\\s]*d" + // Id(允许中间有空格)
"[\\s::{&]*" + // 允许各种分隔符和OCR错误
"值?[\\s::{&]*" + // 可选的"值"字
"[::{&\\s]*" + // 值前的各种符号
"([0-9A-Fa-f]{8})" // 8位十六进制值
);
Matcher matcher = pattern.matcher(text);
if (matcher.find()) {
return matcher.group(1).toUpperCase();
}
// 备用匹配1:直接搜索8位十六进制值(在NFCId文本后)
int nfcIndex = text.indexOf("NFCId");
if (nfcIndex != -1) {
String afterText = text.substring(nfcIndex + 5);
Pattern hexPattern = Pattern.compile("[^0-9A-Fa-f]*([0-9A-Fa-f]{8})");
Matcher hexMatcher = hexPattern.matcher(afterText);
if (hexMatcher.find()) {
return hexMatcher.group(1).toUpperCase();
}
}
// 备用匹配2:全局搜索8位十六进制值(最后手段)
Pattern globalPattern = Pattern.compile("([0-9A-Fa-f]{8})");
Matcher globalMatcher = globalPattern.matcher(text);
// 跳过设备ID(通常在文本前部)
if (globalMatcher.find()) {
// 如果找到多个,取第二个(假设第一个是设备ID)
if (globalMatcher.find()) {
return globalMatcher.group(1).toUpperCase();
}
}
return null;
}
/**
* 直接在内存中进行图像预处理
*/
public static BufferedImage enhancedPreprocessInMemory(File original) throws IOException {
try {
// 1. 读取原始图像
BufferedImage src = ImageIO.read(original);
if (src == null) {
System.err.println("无法读取图像: " + original.getName());
return null;
}
// 2. 转换为灰度图(手动计算亮度)
BufferedImage gray = new BufferedImage(
src.getWidth(),
src.getHeight(),
BufferedImage.TYPE_BYTE_GRAY
);
for (int y = 0; y < src.getHeight(); y++) {
for (int x = 0; x < src.getWidth(); x++) {
Color color = new Color(src.getRGB(x, y));
int luminance = (int)
(0.299 * color.getRed() +
0.587 * color.getGreen() +
0.114 * color.getBlue());
gray.setRGB(x, y, new Color(luminance, luminance, luminance).getRGB());
}
}
// 3. 提高对比度
BufferedImage highContrast = increaseContrast(gray);
// 4. 计算Otsu阈值
int threshold = calculateOtsuThreshold(highContrast);
// 5. 二值化处理
BufferedImage binary = new BufferedImage(
highContrast.getWidth(),
highContrast.getHeight(),
BufferedImage.TYPE_BYTE_BINARY
);
for (int y = 0; y < highContrast.getHeight(); y++) {
for (int x = 0; x < highContrast.getWidth(); x++) {
Color color = new Color(highContrast.getRGB(x, y));
int value = color.getRed() > threshold ? 255 : 0;
binary.setRGB(x, y, new Color(value, value, value).getRGB());
}
}
// 6. 放大图像(提高分辨率)
int newWidth = src.getWidth() * 2;
int newHeight = src.getHeight() * 2;
BufferedImage scaled = new BufferedImage(newWidth, newHeight, BufferedImage.TYPE_BYTE_BINARY);
Graphics2D g2dScaled = scaled.createGraphics();
g2dScaled.setRenderingHint(RenderingHints.KEY_INTERPOLATION, RenderingHints.VALUE_INTERPOLATION_BICUBIC);
g2dScaled.setRenderingHint(RenderingHints.KEY_RENDERING, RenderingHints.VALUE_RENDER_QUALITY);
g2dScaled.setRenderingHint(RenderingHints.KEY_ANTIALIASING, RenderingHints.VALUE_ANTIALIAS_ON);
g2dScaled.drawImage(binary, 0, 0, newWidth, newHeight, null);
g2dScaled.dispose();
System.out.println("✅ 预处理完成: " + original.getName());
return scaled;
} catch (Exception e) {
System.err.println("❌ 图像预处理失败: " + original.getName());
e.printStackTrace();
return null;
}
}
/**
* 提高图像对比度
*/
public static BufferedImage increaseContrast(BufferedImage image) {
BufferedImage result = new BufferedImage(
image.getWidth(),
image.getHeight(),
BufferedImage.TYPE_BYTE_GRAY
);
int min = 255, max = 0;
// 找到最小和最大亮度值
for (int y = 0; y < image.getHeight(); y++) {
for (int x = 0; x < image.getWidth(); x++) {
int luminance = new Color(image.getRGB(x, y)).getRed();
if (luminance < min) min = luminance;
if (luminance > max) max = luminance;
}
}
// 应用对比度拉伸
float scale = 255.0f / (max - min);
for (int y = 0; y < image.getHeight(); y++) {
for (int x = 0; x < image.getWidth(); x++) {
int luminance = new Color(image.getRGB(x, y)).getRed();
int newLuminance = (int)((luminance - min) * scale);
if (newLuminance > 255) newLuminance = 255;
if (newLuminance < 0) newLuminance = 0;
result.setRGB(x, y, new Color(newLuminance, newLuminance, newLuminance).getRGB());
}
}
return result;
}
/**
* 计算Otsu阈值并返回
*/
public static int calculateOtsuThreshold(BufferedImage image) {
int[] histogram = new int[256];
// 计算直方图
for (int y = 0; y < image.getHeight(); y++) {
for (int x = 0; x < image.getWidth(); x++) {
int luminance = new Color(image.getRGB(x, y)).getRed();
histogram[luminance]++;
}
}
// 计算总像素数
int total = image.getWidth() * image.getHeight();
float sum = 0;
for (int i = 0; i < 256; i++) sum += i * histogram[i];
float sumB = 0;
int wB = 0;
int wF = 0;
float varMax = 0;
int threshold = 0;
for (int t = 0; t < 256; t++) {
wB += histogram[t]; // 背景权重
if (wB == 0) continue;
wF = total - wB; // 前景权重
if (wF == 0) break;
sumB += (float)(t * histogram[t]);
float mB = sumB / wB; // 背景均值
float mF = (sum - sumB) / wF; // 前景均值
// 计算类间方差
float varBetween = (float)wB * (float)wF * (mB - mF) * (mB - mF);
// 检查最大值
if (varBetween > varMax) {
varMax = varBetween;
threshold = t;
}
}
return threshold;
}
/**
* 写入Excel文件
* @param data
* @throws IOException
*/
public static void writeExcel(List<String[]> data) throws IOException {
if (data == null || data.isEmpty()) {
System.out.println("⚠️ 没有有效数据可写入Excel");
return;
}
try (Workbook workbook = new XSSFWorkbook();
FileOutputStream fos = new FileOutputStream("提取结果.xlsx")) {
Sheet sheet = workbook.createSheet("提取结果");
// 创建标题行
Row header = sheet.createRow(0);
header.createCell(0).setCellValue("图片名称");
header.createCell(1).setCellValue("设备ID");
header.createCell(2).setCellValue("NFCid");
// 填充数据
for (int i = 0; i < data.size(); i++) {
Row row = sheet.createRow(i + 1);
String[] record = data.get(i);
for (int j = 0; j < record.length; j++) {
row.createCell(j).setCellValue(record[j]);
}
}
// 自动调整列宽
for (int i = 0; i < 3; i++) {
sheet.autoSizeColumn(i);
}
workbook.write(fos);
System.out.println("✅ Excel文件已生成:提取结果.xlsx");
}
}
/**
* 保存OCR结果到文件
*/
public static void saveOcrResult(String imageName, String resultText) {
try {
// 移除文件扩展名中的点
String safeName = imageName.replace(".", "_");
File outputFile = new File("ocr_result_" + safeName + ".txt");
try (FileOutputStream fos = new FileOutputStream(outputFile)) {
fos.write(resultText.getBytes());
}
System.out.println("📝 OCR结果已保存到: " + outputFile.getName());
} catch (IOException e) {
System.err.println("无法保存OCR结果: " + e.getMessage());
}
}
/**
* 生成失败报告
*/
public static void generateFailureReport(List<String> failedImages) {
try (FileOutputStream fos = new FileOutputStream("失败报告.txt")) {
StringBuilder report = new StringBuilder("以下图片处理失败:\n\n");
for (String image : failedImages) {
report.append("• ").append(image).append("\n");
}
report.append("\n请检查这些图片的OCR结果文件(ocr_result_*.txt)");
fos.write(report.toString().getBytes());
System.out.println("📝 失败报告已生成: 失败报告.txt");
} catch (IOException e) {
System.err.println("无法生成失败报告: " + e.getMessage());
}
}
}
demo简单解释
资源都是放在同级目录下的指定文件夹中
使用内存处理图片
测试demo的电脑64G内存无所畏惧!(烂命一条就是干!),内存小的同学考虑分批次加载图片处理,但是那就需要改造后面writeExcel()->读和更新
[重点]提取信息
提取设备ID和NFCId也是根据的demo展示需要所写的,想要试试的同学可以修改为自己想要提取的信息资源,但是需要分析资源特征和写好匹配规则,规则尽量完善,demo中会有失败的记录生成失败报告"${fileName}.txt"文件,里面会保存图片识别后的信息,根据里面的信息判断为什么会识别和匹配失败,慢慢优化匹配规则以提高命中率;
测试demo结果纠正
如果识别的图片有问题,运行窗口会打印文件的名称,可以查看demo运行过程中,打印有问题的图片名称,进到excel中手动修正.当然同学也可以在处理过程中增加异常标识信息,写到excel表格,这样更方便排查问题,但是今天超过了三分钟了,下课了!干饭了 ~ 干饭了 ~ 干饭了~
同学你自己写吧,加油!
运行过程如下:
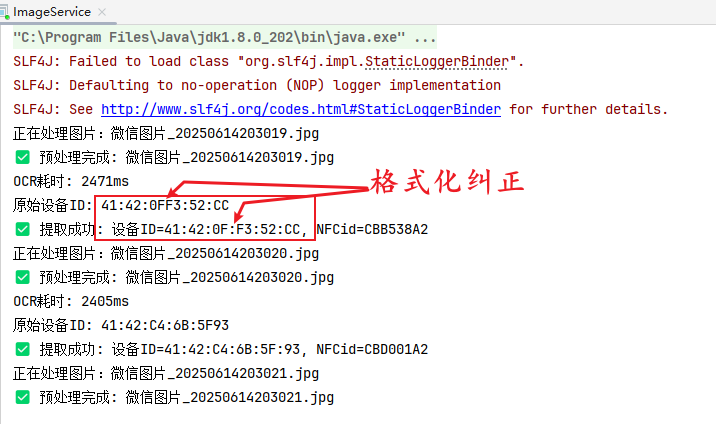
生成excel表格如下:

菜鸟如我,还在努力学习中,大家一起加油吧!
有实在是看不下的大佬,希望能不吝指教.
本文章只是经验技术交流分享,不涉及任何商用,不对任何借鉴人员使用造成的后果负责哦.

















 965
965

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









