



 本文详细解析Kafka生产者客户端的工作流程,包括主线程构建消息、Sender线程发送、RecordAccumulator缓存策略以及元数据更新机制。主线程通过拦截器、序列化器和分区器构建消息,Sender线程批量发送以提高性能。RecordAccumulator的buffer.memory参数控制内存大小,避免阻塞或异常。Sender线程通过InFlightRequests管理未确认请求,元数据更新由Sender线程发起并同步给主线程。
本文详细解析Kafka生产者客户端的工作流程,包括主线程构建消息、Sender线程发送、RecordAccumulator缓存策略以及元数据更新机制。主线程通过拦截器、序列化器和分区器构建消息,Sender线程批量发送以提高性能。RecordAccumulator的buffer.memory参数控制内存大小,避免阻塞或异常。Sender线程通过InFlightRequests管理未确认请求,元数据更新由Sender线程发起并同步给主线程。
一、整体图示
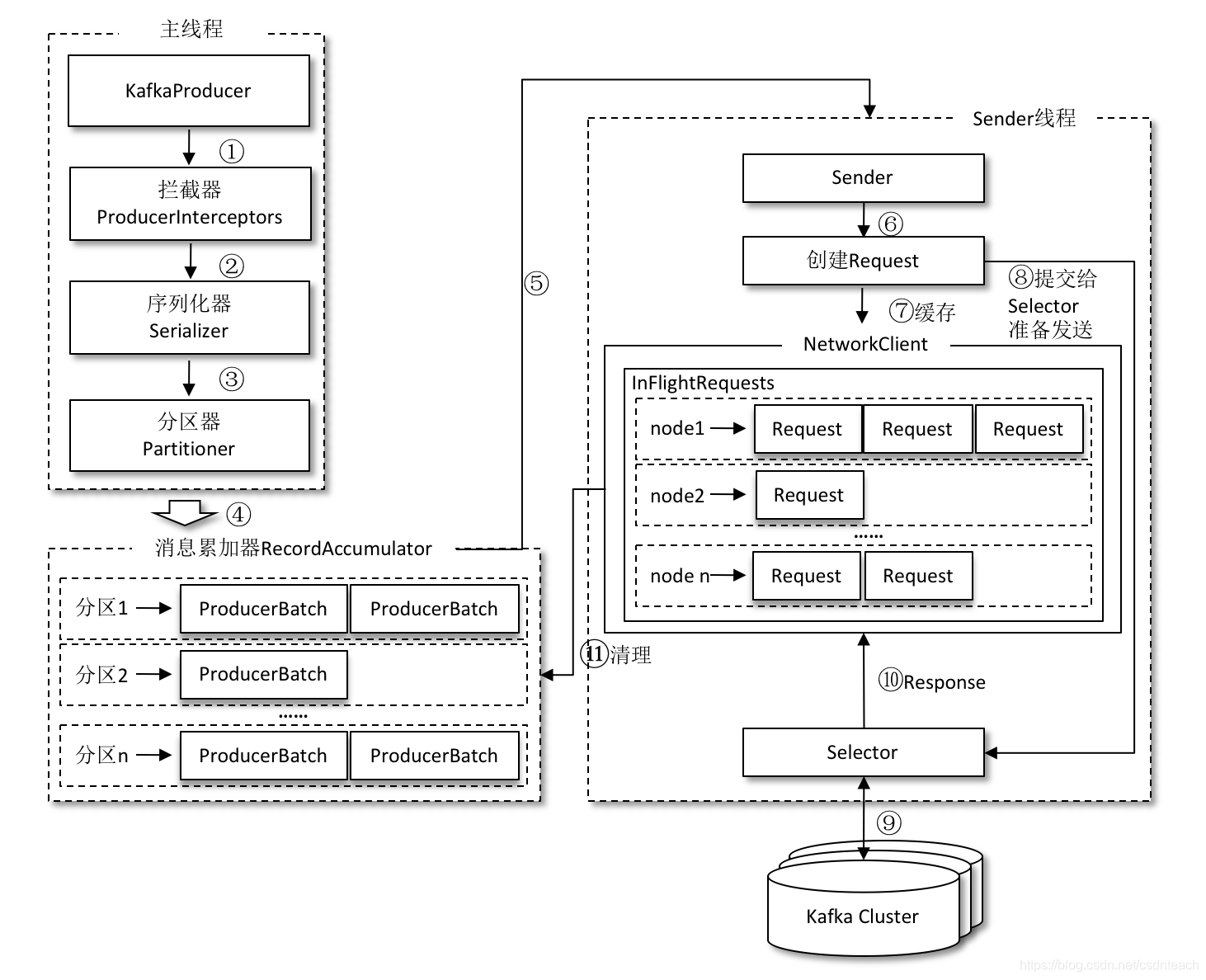
二、整个生产者客户端由两个线程:主线程、Sender发送线程
整个生产者客户端就是由主线程和Sender线程完成消息的发送,由主线程构建消息体,将消息体放到消息累加器中,由Sender 线程,从消息累加器中取值,发送给 Kafka
三、流程分析
3.1 主线程
主线程主要通过 KafkaProducer 对象,构建消息,经过可能的 拦截器 , 序列化器 , 分区器 ,最终交给 消息累加器 (RecordAccumulator)
3.2 RecordAccumulator
- RecordAccumulator 主要的作用就是封装 ProducerRecord 对象,将单个的消息封装为一个集合,使得 Sender
线程可以批量进行拉取和发送,从而减少网络消耗进而提升性能。 - RecordAccumulator 缓存的大小可以通过生产者客户端参数 buffer.memory 进行配置,默认的话是 32MB,如果生产者发送的速度超过了发送到服务器的速度,就会导致生产者的空间不足,这时 send()方法会进行堵塞,或者抛出异常,这个参数由max.block.ms 配置,默认60s
- 主线程中的数据回加到消息累加器中的某个双端队列中,主线程会将其放到双端队列的尾部,Sender 线程从双端队列的头部拉取数据,ProducerBatch 中是一个批次的消息,内部存放的都是 ProducerRecord 也就是前面说的,减少网络传输的消耗,提升性能
- ProducerBatch 大小和 batch.size 参数有关,当一条 Producer流入消息收集器的时候,会找到自己对应分区对应的 Deque ,若不存在的话,需要会进行重建,如果找到则会在双端队列的尾部进行 append,在新建 ProducerBatch 的时候会判断这条消息是否超过了 batch.size的大小,若超过了则使用消息大小进行创建,内存区域不会进行复用,若没有超过则直接用 batch.size 进行创建
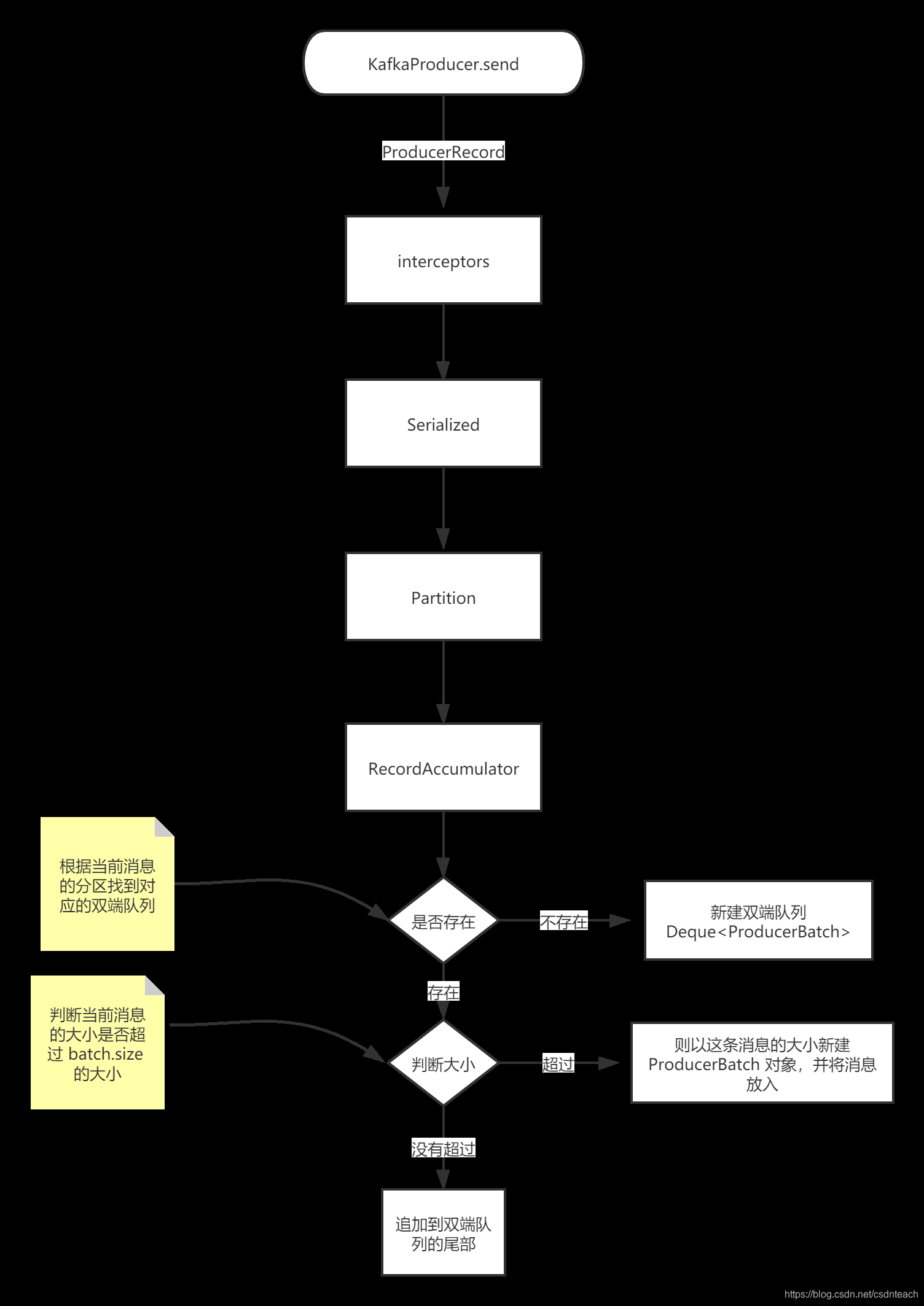
3.3 Sender 线程
- Sender 线程从消息收集器中获取到消息之后会将 <分区,Deque> 转换为 >这里主要做一个逻辑转换,对于网络连接来说,知道发到哪个 Node 节点就足够了
- 在转换成 **** 之后,会在转换为 **** ,Request 的话就是 Kafka 提供的各种请求,这时就可以发送到各个 Node 中
3.4 InFlightRequest
- 请求再从 Sender 线程发送到 kafka 之前还会保存一份到 InFlightRequest 中,会封装成Map<NodeId,Deque> ,nodeid 也就是对应节点的ID,他的主要作用是 缓存发送出去但是还没有收到响应的请求
四、元数据的更新
InFlightRequests 还可以获得 leastLoadedNode,即所有 Node 中负载最小的那一个。
这里的负载最小是通过每个 Node 在 InFlightRequests 中还未确认的请求决定的,未确认的请求越多则认为负载越大
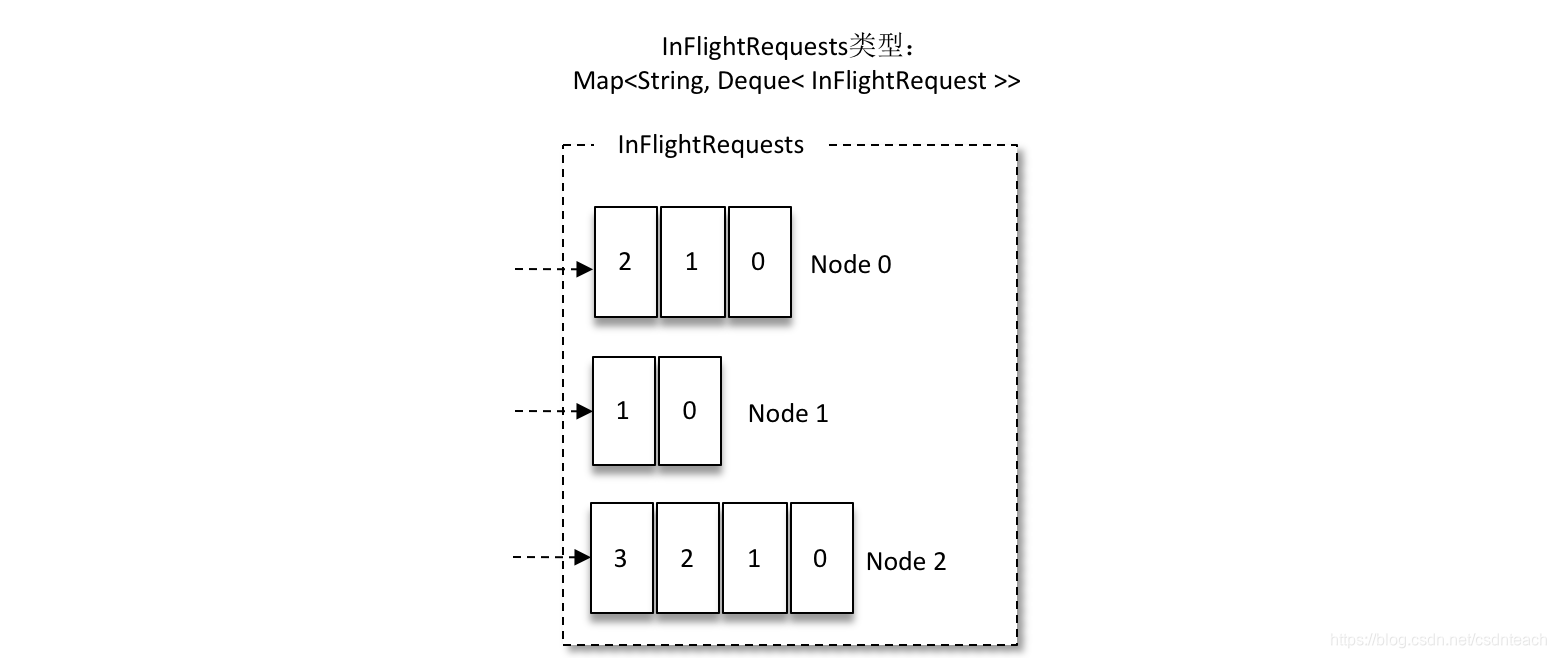
现在的话 Node1 的负载最小,选择负载最小的发送请求,可能会较快发生,减少网络堵塞造成的影响。
元数据的更新操作是在客户端内部进行的,对客户端的外部使用者不可见。当需要更新元数据时,会先挑选出 leastLoadedNode,然后向这个 Node 发送 MetadataRequest 请求来获取具体的元数据信息。这个更新操作是由 Sender 线程发起的,在创建完 MetadataRequest 之后同样会存入 InFlightRequests,之后的步骤就和发送消息时的类似。元数据虽然由 Sender 线程负责更新,但是主线程也需要读取这些信息,这里的数据同步通过 synchronized 和 final 关键字来保障。
原文:https://gper.club/articles/7e7e7f7ff4g59gc6g6e

















 1484
1484

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









