




还记得在刚开始学习这一行业知识时,便有一种千军万马任你指挥的快感。每天的学习之旅,每到晚上都会带着美好的想象而入梦:当我将一个个美好的主意用所学的代码,轻而易举的实现出来,进而改变人们的生活习惯。不得不说,这的确是一个美好的梦。

缓缓几年而过,我也正式踏入了这个行业,却仍也还记得上课那段时间,在编写“功能代码”之时,一直都在思考,为什么每一个功能都只需要那么短的时间完成,而程序员,每次开发程序,都要很长的时间,以及有那么多 bug 呢。那时还在沾沾自喜,认为可能是自己天赋好。可当接触了项目之后,顿时发现自己的想法真是愚不可及,不可理喻。
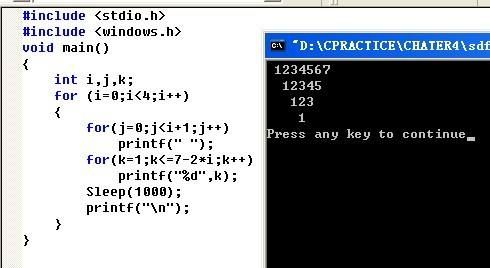
这是最简单的项目,或许只能算是学生的期末题——班级学生管理系统。但就是这样的项目,我却弄了一天。感觉这真的是对程序员抹黑。

首先,我便花了一下时间在表的设计,并不是大家所想的“先计划再行动”,而是“边行动边计划”。
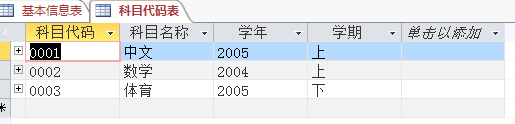
其次,我又在思考着接下来该设计那个地方,每每遇到一点困难之时,都会选择放弃,然后设计别的地方,直到简单的东西全部过。才开始我的查询之旅。
查了很久才发现,应该用函数“dcount()”而不是“count()”,可默默的我想说,教科书写的就是“count()”啊!当然,解决完这一点,还有很多问题等着解决呢。
这是“基本信息导入的追加查询”。
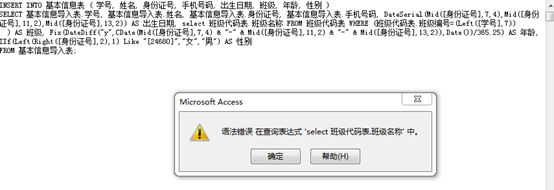
可为什么呢?为此我还特地的重启软件,搜索子查询的知识,感觉没问题啊!
直到最后才发现,原来我少了一个()。
改回来,重新运行一下,又是一脸迷茫。我不是已经将条件赋予了吗?怎么会这样呢?
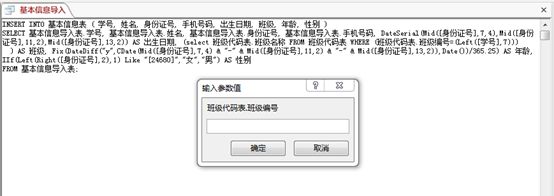
一通乱找后,才发现自己打错了,将“班级代码”打成“班级编号”。
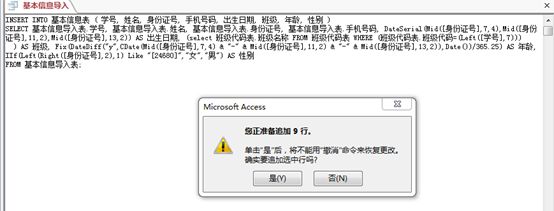
或许每一段功能都很简单,但其实在程序开发的时间里,很大部分都在于为“错误”买单。不仅仅是我们自身的错误,还有“别人”的错误。
直到项目的最后,我才发现我还有东西没做,除了 bug。
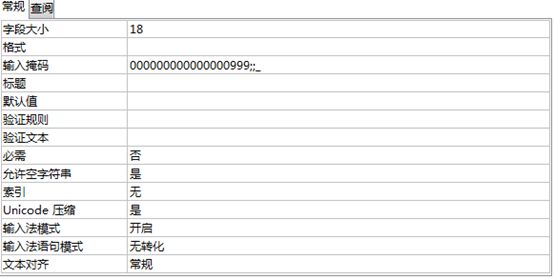
格式设置(防止别人不按照规则输入)

信息提醒
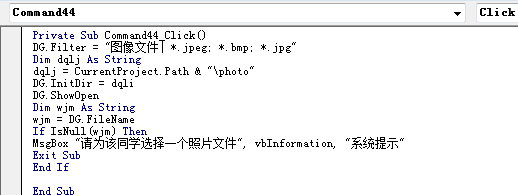
打开的图像类型

错误动作
什么,不做?切记,程序员的价值在于用户的体验。用户感觉不好了,我们的感觉也不好啦。还想着升职加薪,供房养家,还是赶紧打码吧!而一个真正的程序员与“程序员”的区别,或许也在于此了
程序员 >
修复bug的速度
+
制造bug的个数
+
搜索资料的时间
+
代码的可阅读性
+
项目的执行效率
+
知识的广博程度
+
接受错误的能力
+
面对上司的咆哮
+
……
=
经验
>“程序员”
说实话,这就像地图那般,距离是美好的,放大之后,真相是残酷的。至少一名有经验的程序员,不会只会跟着地图走。
声明:本文为作者投稿,版权归对方所有。
作者:马泽武。作为一名刚接触程序员生活的实习生,充满着无尽的梦想,但那也只是梦想,所以大家可以叫我 null。
“ 征稿啦”
优快云 公众号秉持着「与千万技术人共成长」理念,不仅以「极客头条」、「畅言」栏目在第一时间以技术人的独特视角描述技术人关心的行业焦点事件,更有「技术头条」专栏,深度解读行业内的热门技术与场景应用,让所有的开发者紧跟技术潮流,保持警醒的技术嗅觉,对行业趋势、技术有更为全面的认知。
如果你有优质的文章,或是行业热点事件、技术趋势的真知灼见,或是深度的应用实践、场景方案等的新见解,欢迎联系 优快云 投稿,联系方式:微信(guorui_1118,请备注投稿+姓名+公司职位),邮箱(guorui@youkuaiyun.com)。
————— 推荐阅读 —————























 733
733

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











