



Xiaomi MiMo-V2-Flash 是小米专为极致推理效率自研的总参数 309B(激活15B)的 MoE 模型,通过引入 Hybrid 注意力架构创新 及 多层 MTP 推理加速,在多个 Agent 测评基准上进入全球开源模型 Top 2;代码能力超过所有开源模型,比肩标杆闭源模型 Claude 4.5 Sonnet,但推理价格仅为其 2.5% 且生成速度提升至 2 倍,成功将大模型效果和推理效率推向极致。
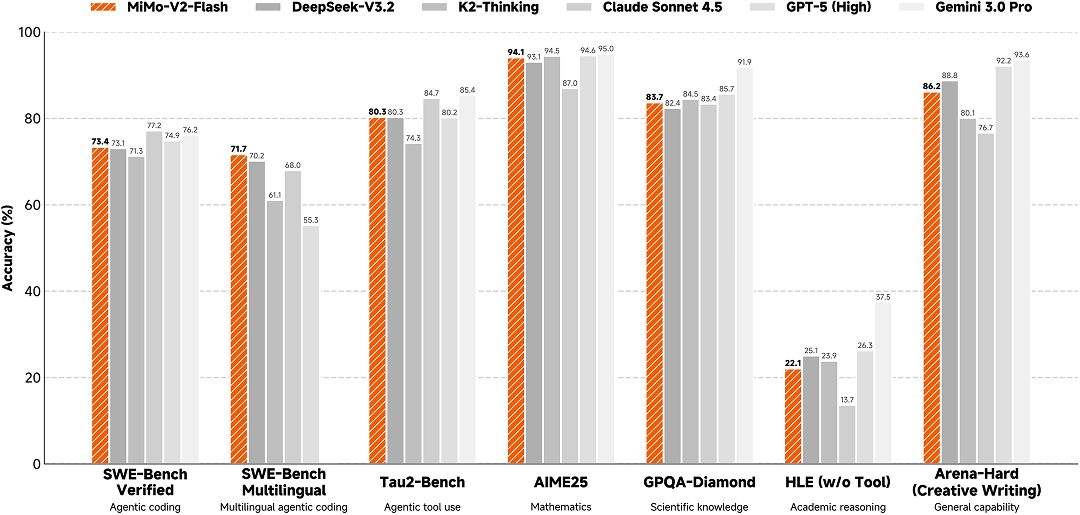
<center>全球顶尖模型测评基准效果对比</center>
秉持开放精神,模型权重和推理代码均全面开源。API 限时免费,体验 Web Demo 已上线。
推理成本与速度的极致优化
MiMo-V2-Flash 的 API 定价为: 输入 0.7 元 / 百万 tokens,输出 2.1 元 / 百万 tokens。
下图为全球顶尖模型速度和成本的对比,MiMo-V2-Flash 实现了低成本、高速度。
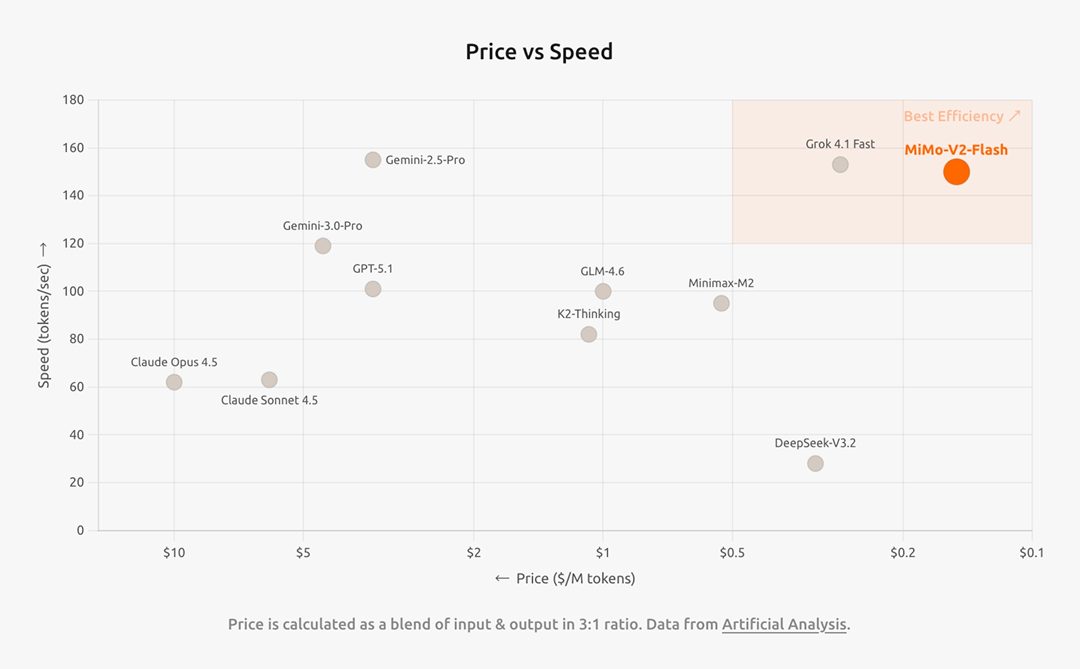
<center>全球顶尖模型速度 vs 成本</center>
面向高效推理的结构创新
模型结构要点如下:
-
混合注意力
采用 5:1 的 Sliding Window Attention (SWA) 与 Global Attention(GA)混合结构,128 窗口大小,原生 32K 外扩 256K 训练。经前期大量实验发现,SWA 简单、高效、易用,展现了比主流 Linear Attention 综合更佳的通用、长文和推理能力,并提供了固定大小的 KV Cache 从而极易适配现有训练和推理 Infra 框架。
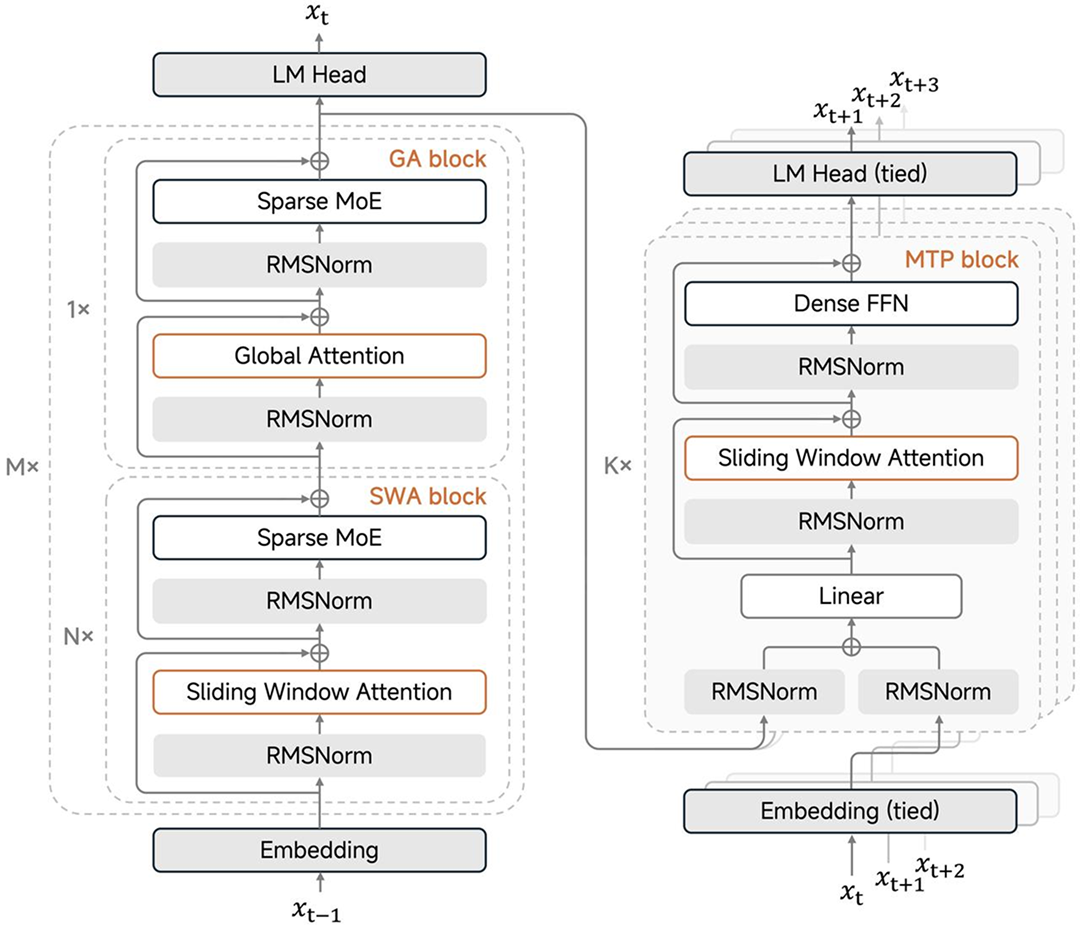
<center>MiMo-V2-Flash 模型架构</center>
-
MTP推理加速
引入 MTP (Multi-Token Prediction) 训练提升基座能力的同时,在推理阶段通过并行验证 MTP Token,打破了传统 Decoding 在大 Batch 下的显存带宽瓶颈,实测在 3 层 MTP 情况下可实现 2.8~3.6 的接收长度和 2.0~2.6 的实际加速比。
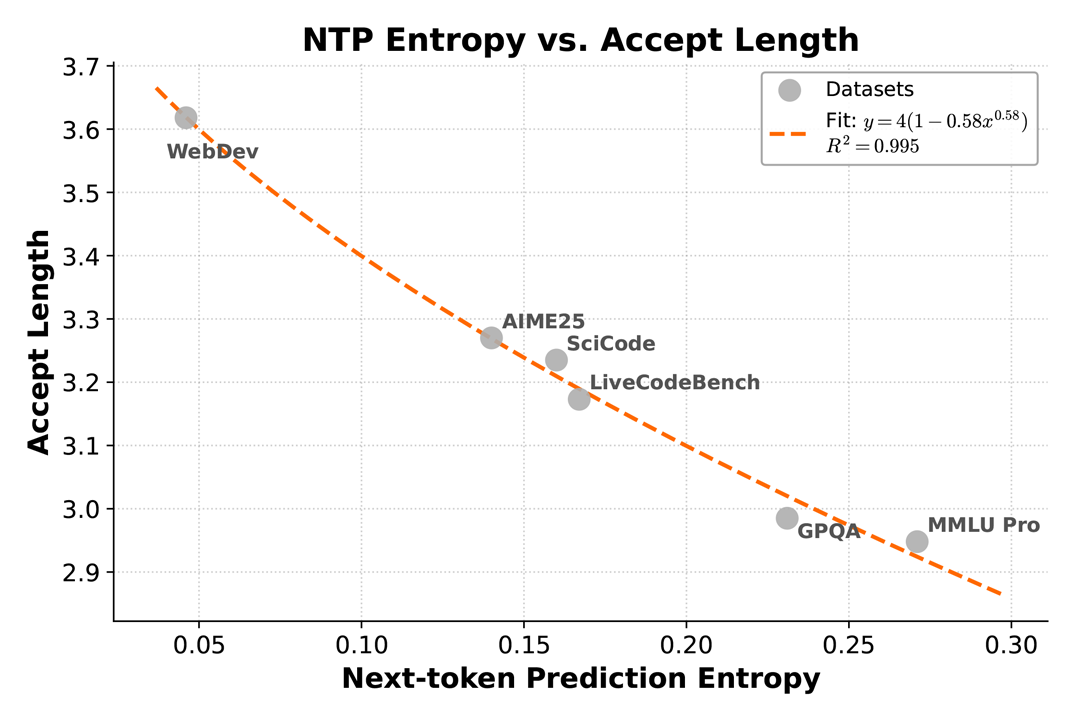
整体而言,得益于模型结构与训推 Infra 的深度融合与创新,MiMo-V2-Flash 可以在不同的硬件上通过调优 Batch Size 和 MTP 层数来最大化释放 GPU 算力,从而展现出更高的吞吐,并维持优秀的低时延以及极致推理性能。
此外,我们发现,MiMo-V2-Flash 非常适合高效的强化学习训练。它既支持小 Batch 的 On-Policy RL 训练,又能缓解长尾样本导致的 GPU 闲置。虽然主流方法采用大 Batch 的 Off-Policy RL 以最大化吞吐量,但 MTP 通过扩展 token 级并行,使小 Batch On-Policy RL 既稳定又高效。在推理采样后期,个别生成序列极长的样本会导致有效 Batch Size 减小,造成 GPU 算力闲置。而 MTP 能显著提升注意力和前馈网络的计算效率,从而降低整体延迟。
全新的后训练范式:MOPD
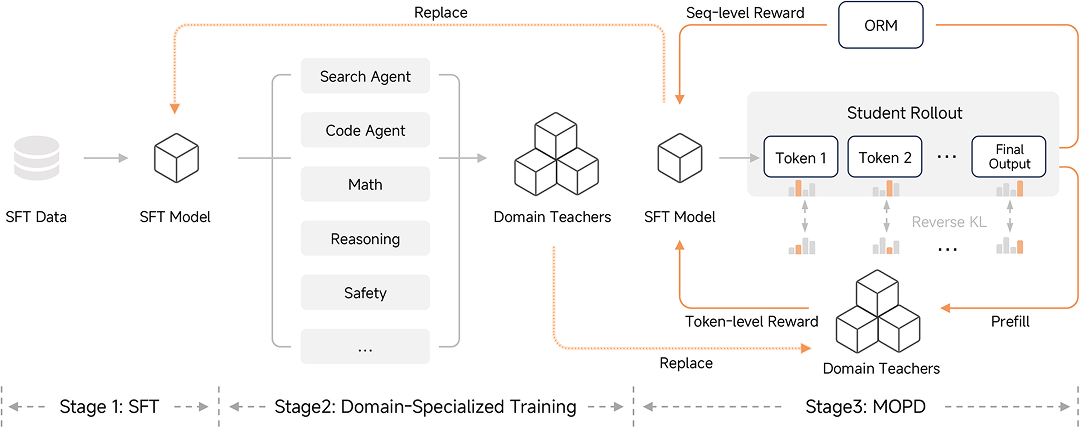
<center>全新的后训练范式(MOPD)</center>
在后训练阶段,为高效扩展后训练阶段的强化学习(RL)计算规模,提升模型推理与 Agent 能力,我们提出 Multi-Teacher On-Policy Distillation(MOPD)范式。其核心在于一种高效的 On-Policy 学习机制:在通过 SFT/RL 获取各领域专家教师后,学生模型基于自身策略分布进行采样(Rollout),并利用多教师提供的 Dense & Token-level Reward 进行优化。
MOPD 训练稳定且极具效率,仅需传统 SFT+RL 流程不到 1/50 的计算资源,即可追上教师模型的峰值能力。此外,MOPD 采用解耦设计,支持灵活引入新教师与 ORM(Outcome Reward Model)集成,并天然支持“教学相长”的闭环迭代:蒸馏后的学生模型可进化为更强教师,实现能力的持续自我强化。
模型技术、推理代码开源
MiMo-V2-Flash 模型现已在 HuggingFace 开源(MIT 协议),技术报告同步发布:
模型:
https://huggingface.co/xiaomimimo/MiMo-V2-Flash
论文:
https://github.com/XiaomiMiMo/MiMo-V2-Flash/blob/main/paper.pdf
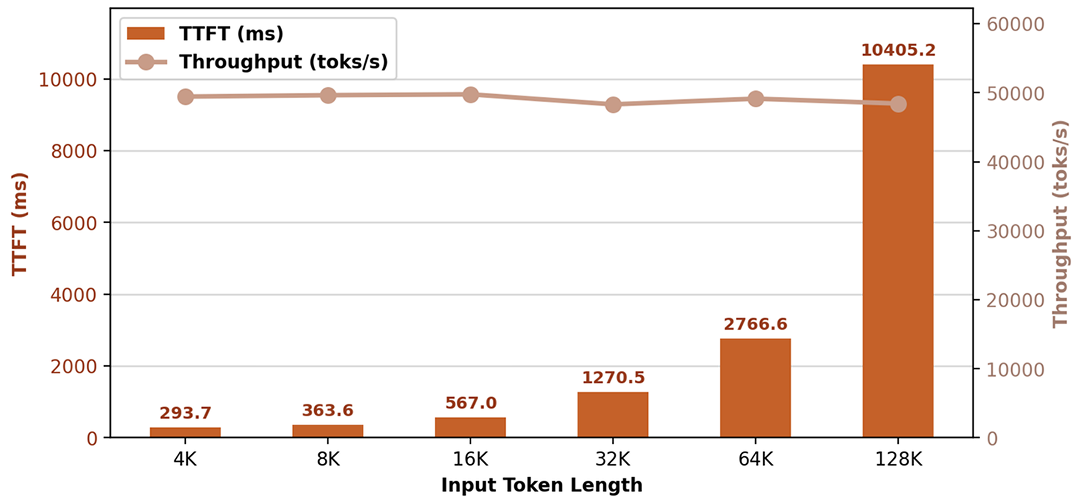
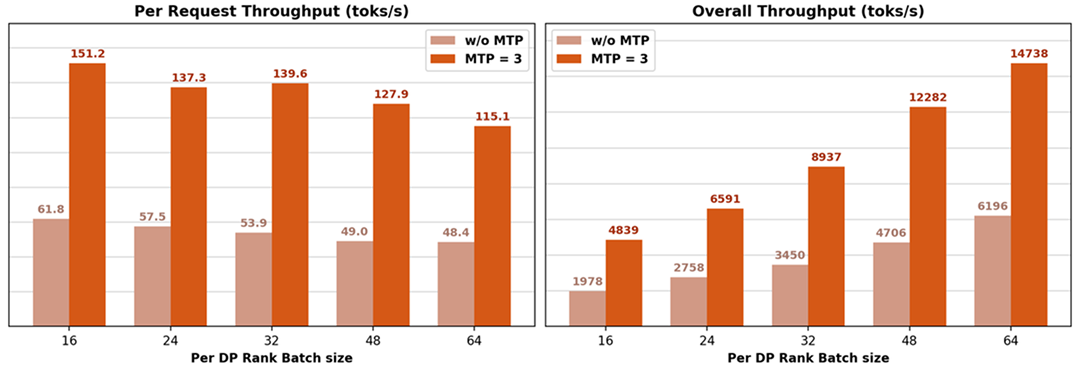
同时,我们在 Day0 共享所有推理代码至 SGLang 并开源,社区实测单机结果如下:
-
在 Prefill 单机吞吐约 50000 toks/s 的条件下,不同 Context Length 都取得了优越的 TTFT 性能
-
得益于 3 层 MTP,在 16K 的 Context Length 情况下,Decode 可以做到单机吞吐 5000 ~ 15000 toks/s 的同时达到 151 ~ 115 toks/s 的 单请求吞吐
详情查看 LMSYS 官方博客:lmsys.org/blog/2025-12-16-mimo-v2-flash
API 限时免费,体验 Web 上线
访问 platform.xiaomimimo.com,可以一键兼容 Claude Code、Cursor、Cline、Kilo Code 等框架。

即刻登录 MiMo Studio Web:aistudio.xiaomimimo.com,免费体验模型。

真实体验
Web 开发:初具“描述世界”的能力
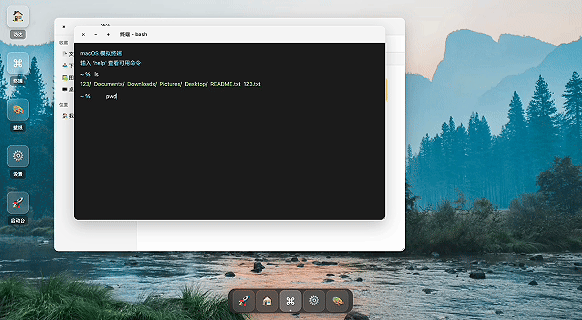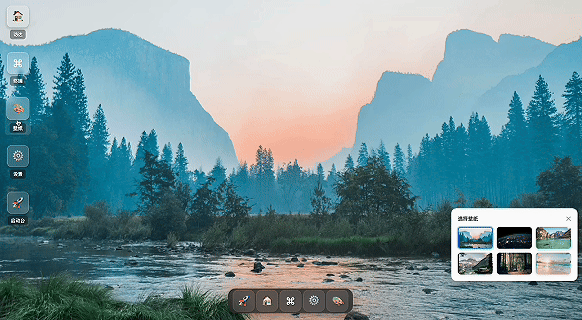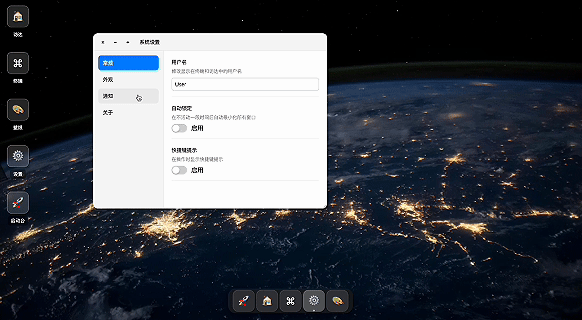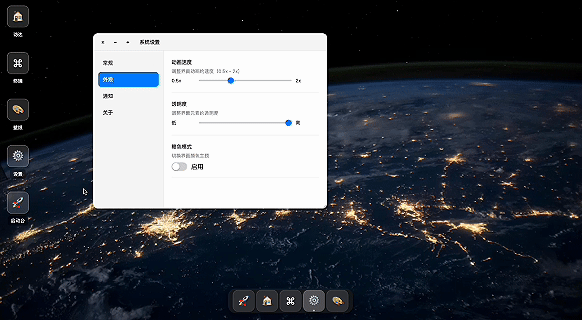
写一个操作系统

模拟太阳系
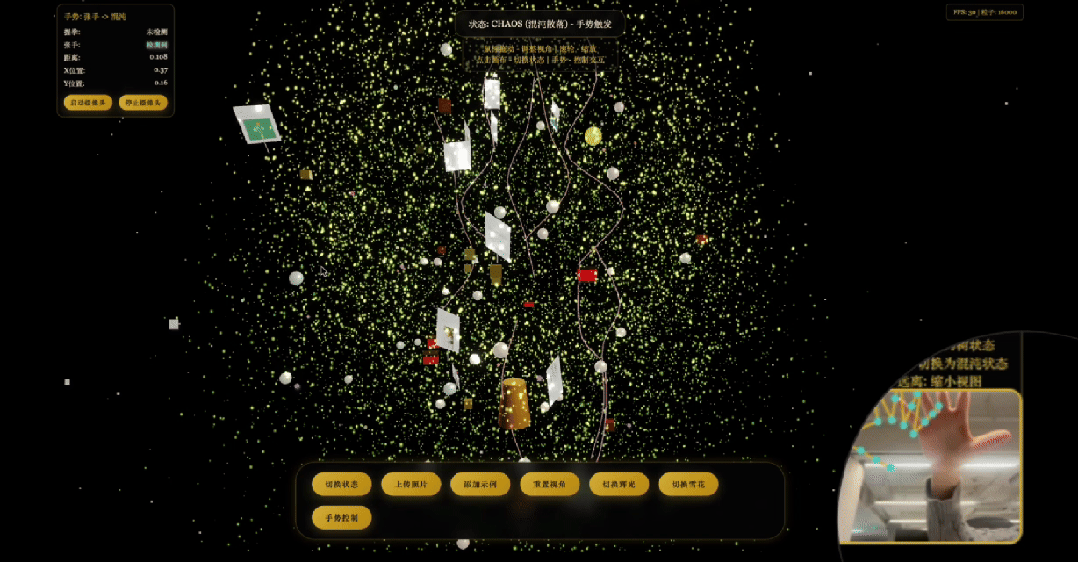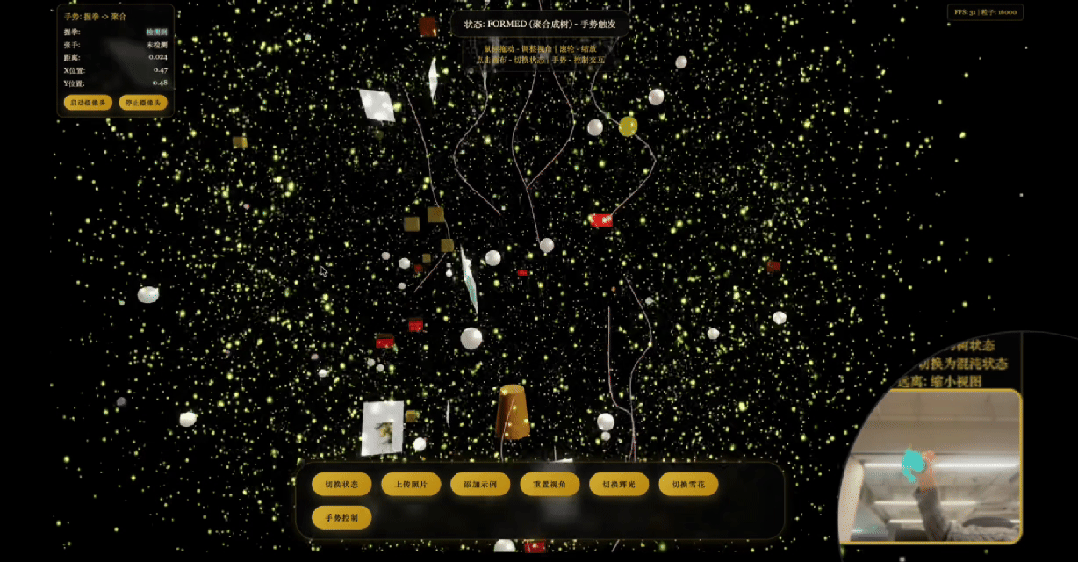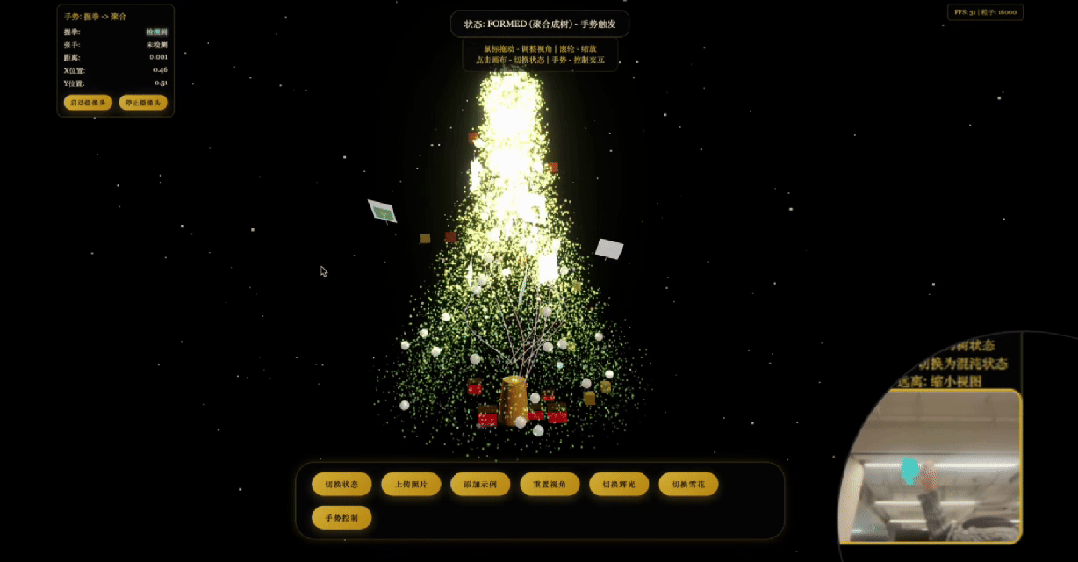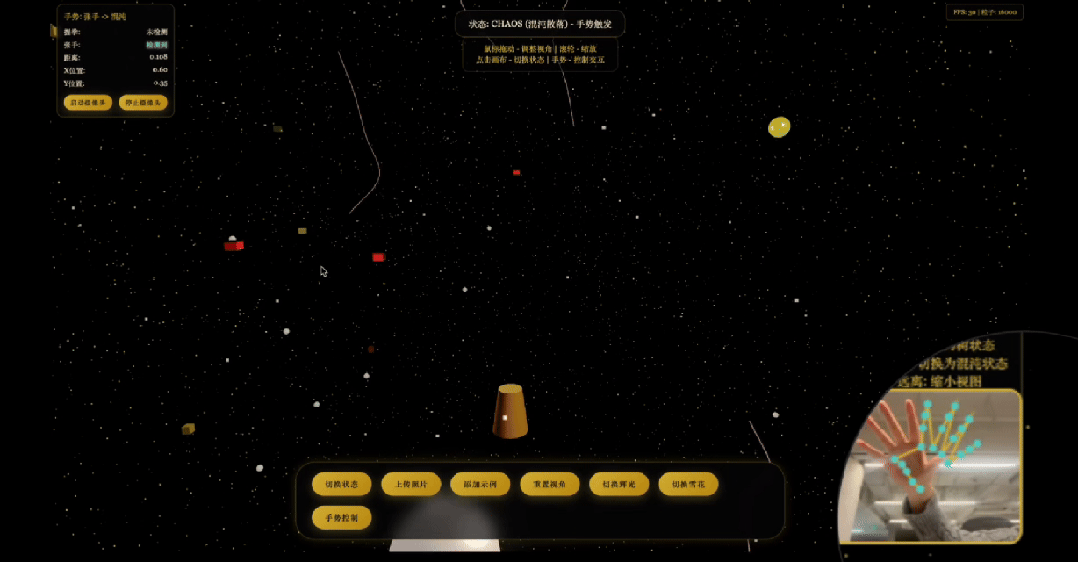
画一颗圣诞树
对话与写作能力:极具对世界的热忱
MiMo-V2-Flash 在对话和创作过程中,有独特的性格特征:简洁平实、有自信,同时极具同理心,满怀对世界的热忱。



















 806
806

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











