







近日,ICCV 2025(国际计算机视觉大会)公布论文录用结果,理想汽车共有 8 篇论文入选,其中 3 篇来自基座模型团队。
其中,基座模型团队与高校团队合作的研究《DH-FaceVid-1K: A Large-Scale High-Quality Dataset for Face Video Generation》,提出业界首个大规模高质量人脸视频数据集 DH-FaceVid-1K。
作为全球首个以亚洲人脸为主的超大规模高质量人脸视频数据集,DH-FaceVid-1K 数据集包含高达 1200 小时视频内容,涵盖 27 万个视频片段,其中亚洲面孔占比达 83%。这一数据集成功解决了当前 AI 人像生成领域长期存在的“亚洲面孔稀缺”难题。
这篇论文是如何构建这一数据集并解决亚洲面孔稀缺问题的呢?让我们通过这篇文章来深入探究其核心方法与贡献。

论文地址:https://arxiv.org/abs/2410.07151
项目主页:https://luna-ai-lab.github.io/DH-FaceVid-1K/
GitHub链接:https://github.com/luna-ai-lab/DH-FaceVid-1K

研究背景:打破数据壁垒,从“稀缺”到“丰富”
你有没有发现一个奇怪的现象?当你使用开源 AI 生成人像视频时,生成的欧美面孔往往栩栩如生,而亚洲面孔却总是显得不够自然——要么五官比例失调,要么表情僵硬,甚至连基本的亚洲人特征都难以准确呈现。
这并非 AI 技术本身“歧视”亚洲人,而是一个更深层的问题在作祟:用于 AI 训练的人脸视频数据集中,亚洲面孔严重缺失。
什么是人脸视频数据集?
在深入了解 DH-FaceVid-1K(Digital Human-FaceVideo-1K,1K 含义为时长在1K 小时以上)之前,我们需要先理解什么是人脸视频数据集。
简单来说,人脸视频数据集就是AI学习“认人”和“生成人脸”的教材。就像我们学习绘画需要大量观察真实的人脸一样,AI 也需要通过学习海量的人脸视频来理解人脸的结构、表情变化、说话时的口型变化等细节。
这些数据集通常包含:
视频片段:记录人物说话、微笑、转头等自然动作
音频信息:与视频同步的语音内容
标注信息:标记人物的年龄、性别、表情、动作等属性
数据集的质量和多样性直接决定了 AI 的“认知能力”。如果训练数据偏向某一类人群,AI生成的结果也会出现相应的偏差。
现状:AI 的“偏见”源于数据失衡
目前,全球主流的开源人脸数据集面临着三大瓶颈:规模有限、质量与数量失衡、以及亚洲人脸数据严重不足,这极大制约了生成效果的公平性与实用性。让我们看看现有主流数据集的情况:
1. CelebV-HQ
总时长:仅 68 小时;
分辨率:512×512;
问题:数据量太小,难以支撑基座模型训练。
2. VoxCeleb2
总时长:2442 小时;
分辨率:仅 224p;
问题:画质太差,生成的人脸缺乏细节。
3. CelebV-Text
亚洲人占比:不足 30%;
问题:族群分布严重失衡。
数据集的族群数据失衡带来的后果是显而易见的。当一个AI模型用 90% 的欧美面孔和 10% 的亚洲面孔训练时,它对亚洲面孔的理解自然是“一知半解”。这就像一个只在西餐厅实习的厨师,你让他做中餐,结果可想而知。
另一方面,这些公开的数据集,包括 CelebV-Text 在内,其通常包含了下图中列举的多种噪音,如随机出现在画面中的人手等:

公开数据集中的多种噪音
以音频驱动的人脸生成任务为例,上述的存在于数据集中的噪音会一致地出现在模型的生成结果中,影响生成效果与质量。
突破:1200 小时亚洲面孔“教科书”
DH-FaceVid-1K 的出现,彻底改变了这一局面。研究团队用数据说话:
规模之最
1200 小时视频内容,相当于连续观看 50 天
27 万个视频片段,每个都经过精心筛选
2 万个不同身份,涵盖各年龄层、各种职业
质量保证
46.5% 的视频达到 1080×1080 高清标准
最低分辨率也保证在 512×512 以上
所有视频都包含清晰的语音内容
族群平衡
83% 亚洲面孔,真正的“亚洲面孔大全”
同时包含 11% 白人、4% 非洲人等,保持适度多样性
性别分布均衡:男性 55%,女性 45%
和主流数据集对比,DH-FaceVid-1K 无疑在各方面实现了压倒性超越。
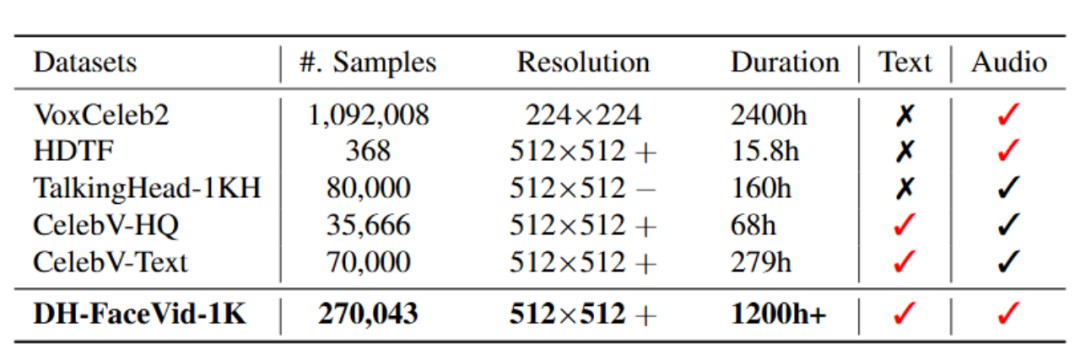
表1:主流数据集与 DH-FaceVid-1K 信息对比
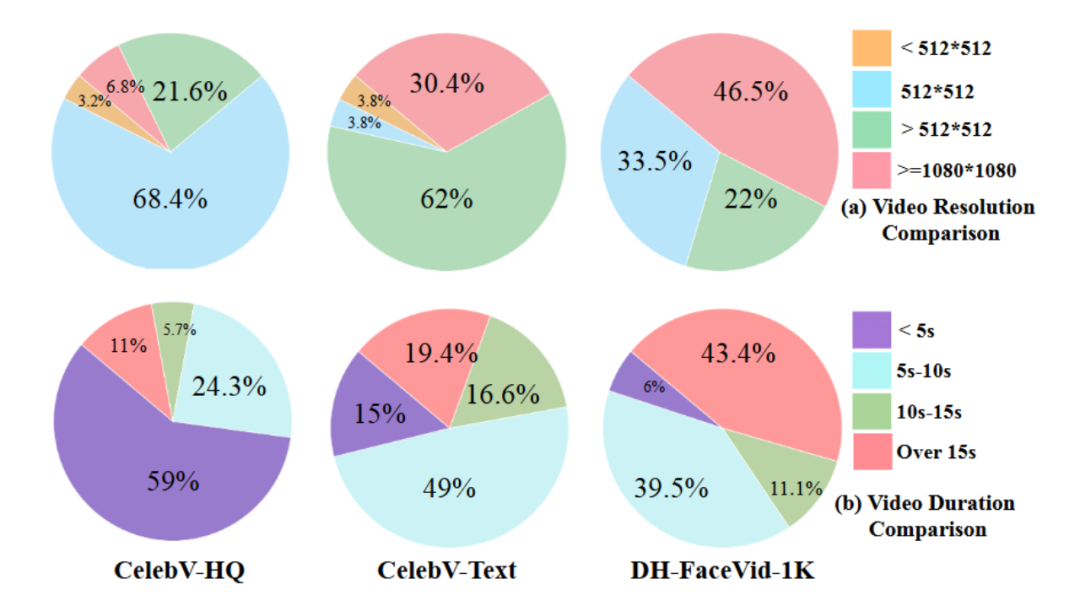
图1 主流数据集与 DH-FaceVid-1K 的视频分辨率及时长对比
这些数字背后,是对“让 AI 公平认识世界上每一张面孔”这一理念的坚持。

技术实现:不只是“大”,更要“精”
传统数据集制作的困境
人脸视频数据对 AI 的训练至关重要,但要获取高质量的数据集却充满挑战。传统方法通常面临诸多挑战:
数据收集难题:之前的人脸视频数据集,比如 CCv2,VoxCeleb2 等,其数据来源可以分成两种,即雇佣专业演员在摄影棚或绿幕录制与在网络爬取,其中前者的问题有:
录制环境与实际模型推理环境差异较大,如绿幕的背景单一,影响模型的泛化性能。
数据来源单一,通常是数名到数百名演员协作录制,同时也难以保证数据集的总时长。
演员录制的视频自然程度通常低于来自网络或数据众包平台的数据,通俗点讲,就是“演出来的终究没有发生的自然”。
而在网络爬取的数据集突出的问题有:
版权与隐私风险高:直接从网络抓取视频存在显著的版权侵权风险,且难以保证个人隐私得到充分保护。
原始质量参差不齐:网络视频来源复杂,分辨率和清晰度差异巨大,混杂着大量不符合要求的内容。
目前几乎所有的公开人脸视频数据集都面临上述问题,难以同时保证数据安全性、多样性、质量与总时长。
数据处理方面:以 prompt 提取为例,目前公开数据集也大致可以分成手工处理和全自动化处理两种,二者共同面临下面的问题:
人工依赖重、成本高:筛选清洗海量视频极度依赖人力,消耗巨大。
缺乏统一筛选标准:缺乏系统化的评估框架,导致数据筛选标准主观随意,影响数据集质量的一致性。
效率极其低下:传统手工作业模式下,清洗 1 小时的原始视频内容,甚至可能需要消耗 10 小时人工,成为规模化生产的巨大障碍。
自动化处理则缺乏人工监管的介入,导致提取出的 prompt 信息等数据失真。
三阶段严格筛选流程
为突破以上困境,我们设计并实施了行业内极其严格的三阶段数据处理流程,核心目标就是在确保数据安全合规的前提下,精准提取高质量内容。
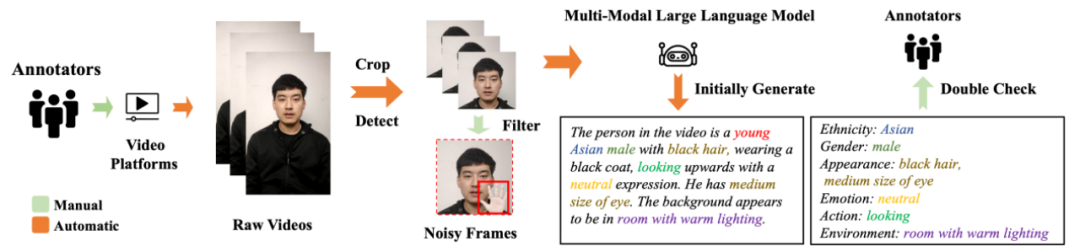
图2 数据处理流程示意图
阶段一:高质数据采集与安全初筛
从合规数据众包平台收集 2000+ 小时 1080p 原始视频,确保了原始数据的质量。
内容以单人采访节目和 Vlog 为主,确保收集的数据符合当前主流人脸生成模型的应用场景。
人脸区域检测裁剪,强制年龄过滤(剔除<22岁个体),保证了数据的安全性。
确保人脸区域 ≥256×256 像素,保证人脸区域的清晰度。
阶段二:多维度噪声过滤与质量增强
自动化过滤:OCR 字幕检测、黑边识别、多脸剔除,主动过滤掉开源人脸视频数据集中存在的诸多问题。
人工精筛:百人团队历时半年交叉审核。
模糊修复:对残留模糊样本采用 CodeFormer 超分辨率增强。
阶段三:多模态标注与音频对齐
视觉标注:DWPose 提取面部关键点,PLLaVA 自动生成初步属性标签,并由人工检查、筛选自动生成的标签以确保其质量和保真度。
音频对齐:基于重训的 SyncNet 模型计算唇语同步分数,确保说话音频与嘴唇的对齐程度。
安全合规:全程匿名化处理,禁止深度伪造滥用。
与传统数据集的处理流程比,DH-FaceVid-1K 的分阶段、分层次、半自动数据预处理流程的优势在于:
1.从源头上解决了合规性与自然度的双重难题。我们摒弃了网络爬取的版权风险与演员录制的场景失真,通过合规众包平台定向采集Vlog、采访等真实世界内容,确保数据来源合法、场景真实,其表情与姿态的自然度远非“扮演”可比。
2.建立了系统化、可量化的质量标尺,告别主观筛选。我们摒弃了传统手工作业的随意性,通过人脸尺寸、唇语同步分数等硬性指标进行自动化过滤,再结合多轮人工交叉审核,形成了一套标准统一、可复现的质量评估框架,从根本上保证了数据集的“精”。
3.实现了“机器跑量、人工把关”的人机协同模式,兼顾效率与精度。我们利用自动化技术处理海量的重复性筛选与初步标注工作,再将人力投入到最关键的审核与精校环节。这种模式既打破了传统手工作业的效率瓶颈,又通过人工监督避免了“全自动”流程带来的数据失真。
4.交付了即用型(Ready-to-use)的多模态数据,极大降低下游应用门槛。我们不止提供清洗后的视频,更交付了一套包含动态面部关键点、视觉属性、音视频同步分数等在内的结构化标签。开发者无需再进行繁琐的数据预处理,可直接将数据用于模型训练,真正做到“开箱即用”。
数据多样性的全面覆盖
为了构建真正具有实际应用价值的人脸视频数据集,研究团队不仅在“量”上达标,更在“质”与“多样性”上下足功夫,力求全面覆盖真实世界中的人脸特性与行为模式:
年龄分布:从青年到老年四个阶段全覆盖,真实反映现实社会的年龄结构。
性别平衡:男性 55%,女性 45%,最大程度避免了性别偏见。
表情完整:以中性表情为主,同时包含了快乐、愤怒等多种丰富的自然情绪状态,更贴近实际应用场景。
动作多样:涵盖说话、微笑、头部运动等自然行为,增强了数据集的活力和应用潜力。
外观特征:30 类特征呈现自然的长尾分布,尤其强化亚洲相关属性。
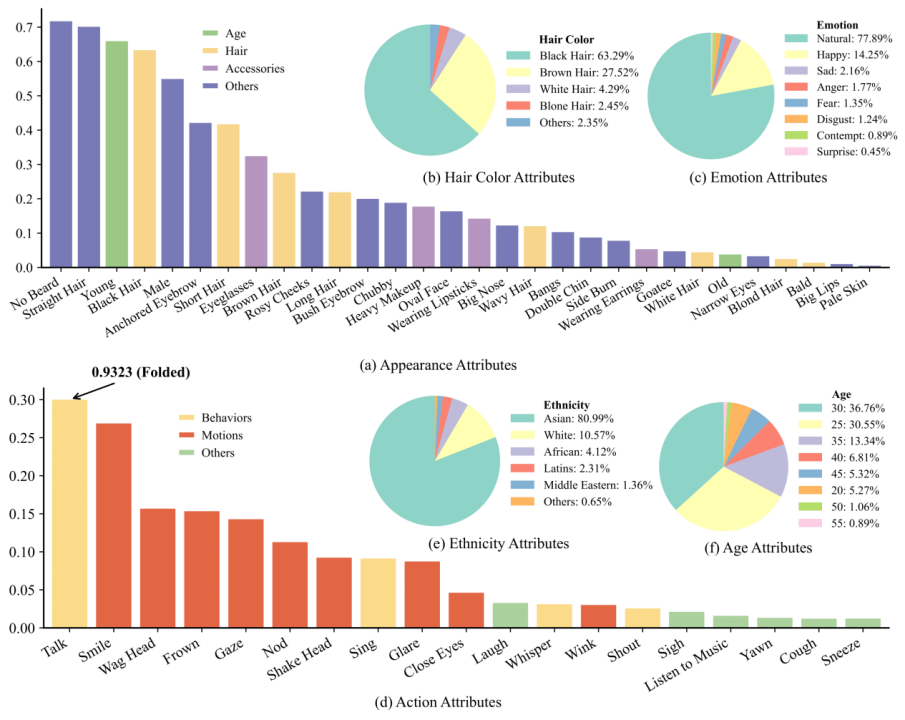
图3 数据集统计指标

应用效果:AI 生成质量的飞跃
理解关键评估指标
在展示效果之前,我们需要理解几个关键的评估指标,它们就像是 AI 生成质量的“体检报告”:
FID (Fréchet Inception Distance)
含义:衡量生成图像与真实图像的相似度;
原理:计算两组图像在特征空间中的距离;
解读:分数越低越好,低于50可认为质量优秀;
类比:就像比较仿制品与正品的相似度。
FVD (Fréchet Video Distance)
含义:FID在视频领域的扩展,评估视频质量;
特点:不仅看单帧质量,还考虑时间连贯性;
解读:分数越低,视频越自然流畅;
类比:检查动画是否流畅,有无跳帧或闪烁。
CLIPScore
含义:评估生成内容与文本描述的匹配度;
原理:使用 CLIP 模型计算图文相似性;
解读:分数越高,说明AI越“听话”;
类比:测试 AI 是否真正理解了你的需求。
量化指标全面提升
使用 DH-FaceVid-1K 训练的模型,在关键指标上均有显著提升:
FID(单帧质量):提升 15-20% 的生成的人脸更加真实细腻。
FVD(视频质量):提升 20-30% 的动作更自然,没有诡异的抖动。
CLIPScore(指令理解):提升 10-15%,更准确地生成用户想要的效果。

表2 T2V(Text-to-Video)模型性能对比

表3 I2V(Image-to-Video)模型性能对比
在生成“年轻亚洲女性说话”的任务中,使用新数据集训练的模型生成的人脸更加自然、细节更加丰富,彻底告别了以往的“AI 脸”痕迹。

图4 T2V(Text-to-Video)模型生成画面对比

图5 I2V(Image-to-Video)模型生成画面对比

意义深远:推动 AI 公平性发展
技术民主化
DH-FaceVid-1K 的开源发布,不仅是技术突破,更是推动 AI 公平性和包容性发展的重要里程碑。此次发布意味着:
全球研究者都能获得高质量的亚洲人脸训练数据。
中小团队也能开发出优秀的亚洲人脸生成模型。
推动 AI 技术更加包容和公平。
应用场景广阔
DH-FaceVid-1K 的开源发布,将为全球研究者提供更公平、更全面的训练资源,推动人像生成技术在虚拟人、远程会议、内容创作等领域的广泛应用,除此之外,这一突破将也会在以下多个领域产生深远影响:
虚拟人产业:更真实的亚洲虚拟主播和数字人,提升用户的文化认同感。
内容创作:为亚洲影视内容提供更好的AI工具,降低内容制作成本。
教育培训:开发贴近亚洲用户的虚拟教师,提升在线教育的亲和力。
游戏娱乐:创造更真实的亚洲游戏角色,增强游戏的沉浸感。

结语
DH-FaceVid-1K 的发布,不仅是一个技术里程碑,更是推动 AI 向着更加公平、包容方向发展的重要一步。当 AI 真正“认识”了全世界的面孔,它才能更好地为全人类服务。(投稿或寻求报道:zhanghy@youkuaiyun.com)
2025 全球产品经理大会
8 月 15–16 日
北京·威斯汀酒店
互联网大厂、AI 创业公司、ToB/ToC 实战一线的产品人
12 大专题分享,洞察趋势、拆解路径、对话未来。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











