



 本文介绍了如何利用poi-tl这个基于Word模板引擎的Java库来高效地导出格式复杂的Word文档。通过一个实际的证书报表案例,展示了poi-tl在处理动态表格时的便利性。
本文介绍了如何利用poi-tl这个基于Word模板引擎的Java库来高效地导出格式复杂的Word文档。通过一个实际的证书报表案例,展示了poi-tl在处理动态表格时的便利性。
UEditor 官网地址:http://fex.baidu.com/ueditor/
poi-tl 地址:Poi-tl Documentation
最近在做证书报表发现了一个好用的poi名为poi-tl 他是基于word模板引擎实现的导出word。
对于导出word格式要求严格你来说,poi-tl很好用。下面是我的实例;

@Test
public void testRenderTemplateByMapsaaa() throws Exception {
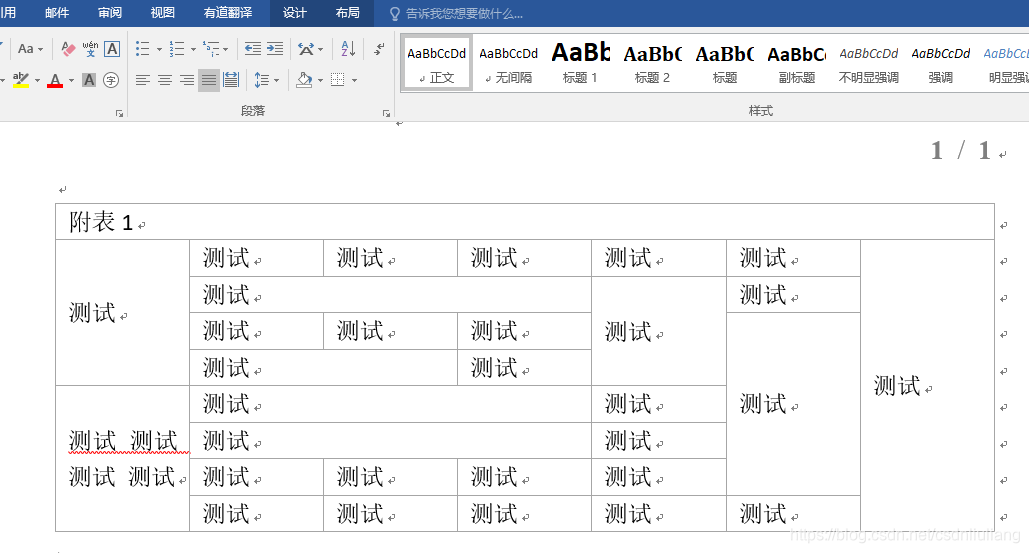
String template="<p> </p><p><br/></p><table data-sort=\"sortDisabled\" width=\"631\"><tbody><tr class=\"firstRow\"><td valign=\"top\" colspan=\"7\" rowspan=\"1\">附表1<br/></td></tr><tr><td width=\"74\" valign=\"top\" rowspan=\"4\" colspan=\"1\" style=\"word-break: break-all;\">测试</td><td width=\"74\" valign=\"top\" style=\"word-break: break-all;\">测试</td><td width=\"74\" valign=\"top\" style=\"word-break: break-all;\">测试</td><td width=\"74\" valign=\"top\" style=\"word-break: break-all;\">测试</td><td width=\"74\" valign=\"top\" style=\"word-break: break-all;\">测试</td><td width=\"74\" valign=\"top\" style=\"word-break: break-all;\">测试</td><td valign=\"top\" colspan=\"1\" rowspan=\"8\">测试<br/></td></tr><tr><td valign=\"top\" rowspan=\"1\" colspan=\"3\" style=\"word-break: break-all;\">测试</td><td width=\"74\" valign=\"top\" rowspan=\"3\" colspan=\"1\" style=\"word-break: break-all;\">测试</td><td width=\"74\" valign=\"top\" style=\"word-break: break-all;\">测试</td></tr><tr><td width=\"74\" valign=\"top\" style=\"word-break: break-all;\">测试</td><td width=\"74\" valign=\"top\" style=\"word-break: break-all;\">测试</td><td width=\"74\" valign=\"top\" style=\"word-break: break-all;\">测试</td><td width=\"74\" valign=\"top\" style=\"word-break: break-all;\" rowspan=\"5\" colspan=\"1\">测试<br/></td></tr><tr><td valign=\"top\" style=\"word-break: break-all;\" rowspan=\"1\" colspan=\"2\">测试<br/></td><td width=\"74\" valign=\"top\" style=\"word-break: break-all;\">测试</td></tr><tr><td width=\"74\" valign=\"top\" style=\"word-break: break-all;\" rowspan=\"4\" colspan=\"1\">测试<br/>测试<br/>测试<br/>测试</td><td valign=\"top\" style=\"word-break: break-all;\" rowspan=\"1\" colspan=\"3\">测试<br/></td><td width=\"74\" valign=\"top\" style=\"word-break: break-all;\">测试</td></tr><tr><td valign=\"top\" style=\"word-break: break-all;\" rowspan=\"1\" colspan=\"3\">测试<br/></td><td width=\"74\" valign=\"top\" style=\"word-break: break-all;\">测试</td></tr><tr><td width=\"74\" valign=\"top\" style=\"word-break: break-all;\">测试</td><td width=\"74\" valign=\"top\" style=\"word-break: break-all;\">测试</td><td width=\"74\" valign=\"top\" style=\"word-break: break-all;\">测试</td><td width=\"74\" valign=\"top\" style=\"word-break: break-all;\">测试</td></tr><tr><td width=\"74\" valign=\"top\" style=\"word-break: break-all;\">测试</td><td width=\"74\" valign=\"top\" style=\"word-break: break-all;\">测试</td><td width=\"74\" valign=\"top\" style=\"word-break: break-all;\">测试</td><td width=\"74\" valign=\"top\" style=\"word-break: break-all;\">测试</td><td width=\"74\" valign=\"top\" style=\"word-break: break-all;\">测试</td></tr></tbody></table><p><br/></p>";
Document document = Jsoup.parseBodyFragment(template);
Elements links = document.getElementsByTag("tbody");
//设置的合并规则
MergeCellRule.MergeCellRuleBuilder mergeCellRuleBuilder = MergeCellRule.builder();
//设置样式颜色尺寸等等
TableStyle.BorderStyle borderStyle = new TableStyle.BorderStyle();
borderStyle.setColor("A6A6A6");
borderStyle.setSize(4);
borderStyle.setType(XWPFBorderType.SINGLE);
TableRenderData table = Tables.ofA4Width().border(borderStyle).center().create();
Elements basicTrs = links.get(0).getElementsByTag("tr");
List<Map<String,Integer>> trList = new ArrayList<>();
List<Map<String,Integer>> rowtrList = new ArrayList<>();//几个纵向合并
List<Map<String,Integer>> rowspanList = new ArrayList<>();//纵向合并影响的行数
List<Map<String,Integer>> listmap = new ArrayList<>();//纵向合并判断
List<Map<String,Integer>> listmap2 = new ArrayList<>();//横向合并判断
for(Element tr : basicTrs) {
Elements tds = tr.getElementsByTag("td");
List<Map<String,Integer>> tdList = new ArrayList<>();
List<String> strsss = new ArrayList<String>();
for(Element td : tds) {
//获取属性为colspan的Elements对象
Elements elcolspan = td.select("td[colspan]");
String colspan = elcolspan.attr("colspan");
String rowspan = elcolspan.attr("rowspan");
if(StringUtils.isNoneBlank(rowspan) && Integer.parseInt(rowspan)>1) {
Map<String,Integer> intmap = new HashMap<>();
Map<String,Integer> map = new HashMap<>();
map.put("index", tr.siblingIndex());//第几行开始
map.put("hang", tr.siblingIndex()+Integer.parseInt(rowspan));//影响到第几行
map.put("lie", td.siblingIndex());//第几列的合并
intmap.put(String.valueOf(tr.siblingIndex()), Integer.parseInt(rowspan)+tr.siblingIndex());
intmap.put("trindex", tr.siblingIndex());
intmap.put("tdindex", td.siblingIndex());
rowspanList.add(map);
listmap.add(intmap);
}
// 判断纵向合并
if(StringUtils.isNoneBlank(colspan) && Integer.parseInt(colspan)>1) {
// 当前合并下角标
Map<String,Integer> map = new HashMap<>();
map.put("a", td.siblingIndex());
map.put("b", td.siblingIndex()+Integer.parseInt(colspan)-1);
map.put("c", td.siblingIndex());
tdList.add(map);
strsss.add(td.text());
for(int i=1;i<Integer.parseInt(colspan);i++) {
strsss.add(null);
}
Map<String,Integer> intmap = new HashMap<>();
intmap.put(String.valueOf(tr.siblingIndex()), Integer.parseInt(colspan)-1);
intmap.put("trindex", tr.siblingIndex());
intmap.put("tdindex", td.siblingIndex());
listmap2.add(intmap);
if(StringUtils.isNoneBlank(rowspan) && Integer.parseInt(rowspan)>1) {
Map<String,Integer> map1 = new HashMap<>();
map1.put("a", td.siblingIndex());
map1.put("c", tr.siblingIndex());
map1.put("b", tr.siblingIndex()+Integer.parseInt(rowspan)-1);
trList.add(map1);
Map<String,Integer> map2 = new HashMap<>();
map2.put("index", Integer.parseInt(rowspan));
map2.put("rowspanindex", Integer.parseInt(rowspan));
map2.put("tdindex", td.siblingIndex());
rowtrList.add(map2);
}
continue;
}
if(StringUtils.isNoneBlank(rowspan) && Integer.parseInt(rowspan)>1) {
Map<String,Integer> map = new HashMap<>();
Map<String,Integer> map2 = new HashMap<>();
int index= 0;//
for(Map<String,Integer> m:rowtrList) {
// Integer tdindex = m.get("tdindex");//纵向合处理后列位置
Integer tdindexPrimitive = m.get("tdindexPrimitive");//纵向合并当前列
Integer trindex = m.get("trindex");//纵向第几行开始合并
Integer rowspanindex = m.get("rowspanindex");//纵向合并影响的行数
int sum = trindex+rowspanindex-1;
if(trindex<tr.siblingIndex()&&tdindexPrimitive<td.siblingIndex() && sum>tr.siblingIndex()) {
index++;
}
}
int trindex = tr.siblingIndex();
int tdindex = td.siblingIndex();
for(Map<String,Integer> m2 :listmap2) {
Integer indextr = m2.get("trindex");//横向合并出现在第几行
Integer tdindexend = m2.get("tdindex");//当前行第几列开始合并
Integer indexend = m2.get(String.valueOf(indextr));//以行标记为key获取合并的数
if(trindex==indextr && tdindex>tdindexend) {
index=index+indexend;
}
}
map.put("a", td.siblingIndex()+index);
map.put("c", tr.siblingIndex());
map.put("b", tr.siblingIndex()+Integer.parseInt(rowspan)-1);
trList.add(map);
map2.put("index", Integer.parseInt(rowspan));
map2.put("trindex", tr.siblingIndex());
map2.put("rowspanindex", Integer.parseInt(rowspan));
map2.put("tdindex", td.siblingIndex()+index);
map2.put("tdindexPrimitive", td.siblingIndex());//原始td角标位置
rowtrList.add(map2);
}
//普通表格列
strsss.add(td.text());
}
Collections.sort(rowtrList, new Comparator<Map<String, Integer>>() {
public int compare(Map<String, Integer> o1, Map<String, Integer> o2) {
Integer name1 = o1.get("tdindex") ;//name1是从你list里面拿出来的一个
Integer name2 = o2.get("tdindex") ; //name1是从你list里面拿出来的第二个name
return name1.compareTo(name2);
}
});
for(Map<String,Integer> m:rowtrList) {
Integer index = m.get("index");
if(index>0 && index< m.get("rowspanindex")) {
strsss.add( m.get("tdindex"),"NAN");
// index--;
m.put("index", index-1);
}else {
// index--;
m.put("index", index-1);
}
}
System.out.println(strsss.toString());
RowRenderData row = Rows.of(strsss.stream().toArray(String[]::new)).verticalCenter().create();
table.addRow(row);
for(Map<String,Integer> m:tdList) {
int jiaobiao = 0;//横向
int trindex = tr.siblingIndex();
int tdindex = m.get("a");
for(Map<String,Integer> m2 :listmap) {
Integer index = m2.get("trindex");//纵向合并出现在第几行
Integer tdindexend = m2.get("tdindex");//当前列第几行开始合并
Integer indexend = m2.get(String.valueOf(index));//以列标记为key获取到几行结束合并
if(trindex>index && trindex<indexend && tdindex>=tdindexend) {
jiaobiao++;
}
}
for(Map<String,Integer> m2 :listmap2) {
Integer index = m2.get("trindex");//横向合并出现在第几行
Integer tdindexend = m2.get("tdindex");//当前行第几列开始合并
Integer indexend = m2.get(String.valueOf(index));//以行标记为key获取合并的数
if(trindex==index && tdindex>tdindexend) {
jiaobiao=jiaobiao+indexend;
}
}
if(jiaobiao>0) {
System.out.println(tr.siblingIndex()+"***"+m.get("a")+"***"+m.get("b")+jiaobiao);
mergeCellRuleBuilder.map(Grid.of(tr.siblingIndex(), m.get("a")+jiaobiao), Grid.of(tr.siblingIndex(), m.get("b")+jiaobiao));//横向合并
}else {
System.out.println(tr.siblingIndex()+"***"+m.get("a")+"***"+m.get("b"));
mergeCellRuleBuilder.map(Grid.of(tr.siblingIndex(), m.get("a")), Grid.of(tr.siblingIndex(), m.get("b")));//横向合并
// mergeCellRuleBuilder.map(Grid.of(1,2), Grid.of(1,4));//横向合并
}
}
}
for(Map<String,Integer> m:trList) {
System.out.println(m.get("c")+"===="+m.get("a")+"===="+m.get("b"));
mergeCellRuleBuilder.map(Grid.of(m.get("c"), m.get("a")), Grid.of(m.get("b"), m.get("a")));//横向合并
}
// mergeCellRuleBuilder.map(Grid.of(3, 6), Grid.of(6, 6));
// mergeCellRuleBuilder.map(Grid.of(0, 1), Grid.of(3, 1));
/**
* MergeCellRule支持多合并规则,会以Map的形式存入可以看一下源码
* !!! 一定要设置完规则后再调用 MergeCellRule的build方法进行构建
*/
table.setMergeRule(mergeCellRuleBuilder.build());
Map<String, Object> datas = new HashMap<String, Object>();
datas.put("table1", table);
XWPFTemplate.compile("设计评估符合证明附页.docx").render(datas).writeToFile("a.docx");
}

















 1193
1193

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









