




 本文探讨了Golang中变量分配在栈或堆的问题,通过逃逸分析决定变量的存储位置。逃逸分析在编译时进行,如果变量作用域超出函数范围或满足特定条件,变量可能分配在堆上。理解逃逸分析有助于优化程序,减少内存分配开销和GC压力。适当使用指针传递可以平衡性能和内存管理。
本文探讨了Golang中变量分配在栈或堆的问题,通过逃逸分析决定变量的存储位置。逃逸分析在编译时进行,如果变量作用域超出函数范围或满足特定条件,变量可能分配在堆上。理解逃逸分析有助于优化程序,减少内存分配开销和GC压力。适当使用指针传递可以平衡性能和内存管理。
本节讨论golang声明变量时,是放在栈上还是堆上的问题
引言
我:“golang 函数传参是不是应该跟 c 一样,尽量不要直接传结构体,而要传结构体指针?“
leader:“不对,咱们项目很多都是直接传结构体的。“
我:“那样不会造成不必要的内存 copy 开销吗?”
leader:“确实会有,但这样可以减小 gc 压力,因为传值会在栈上分配,而一旦传指针,结构体就会逃逸到堆上。“
我:“有道理。。。“
下面看一段代码
package main
func foo(arg_val int)(*int) {
var foo_val int = 11;
return &foo_val;
}
func main() {
main_val := foo(666)
println(*main_val)
}
编译运行
$ go run pro_1.go
11
这段代码在golang中是可以正常运行的,但了解C/C++的同学都知道,这种情况是一定不被允许的。因为外部函数使用了子函数的局部变量, 理论来说,子函数的foo_val 的声明周期早就销毁了,导致无法运行。
但是golang却没有任何问题,这是为什么呢?
因为foo_val变量被分配在了堆上
堆和栈
应用程序的内存载体,我们可以简单地将其分为堆和栈。
在Go中,栈的内存是由编译器自动进行分配和释放,栈区往往存储着函数参数、局部变量和调用函数帧,它们随着函数的创建而分配,函数的退出而销毁。一个goroutine对应一个栈,栈是调用栈(call stack)的简称。一个栈通常又包含了许多栈帧(stack frame),它描述的是函数之间的调用关系,每一帧对应一次尚未返回的函数调用,它本身也是以栈形式存放数据。
举例:在一个goroutine里,函数A()正在调用函数B(),那么这个调用栈的内存布局示意图如下。
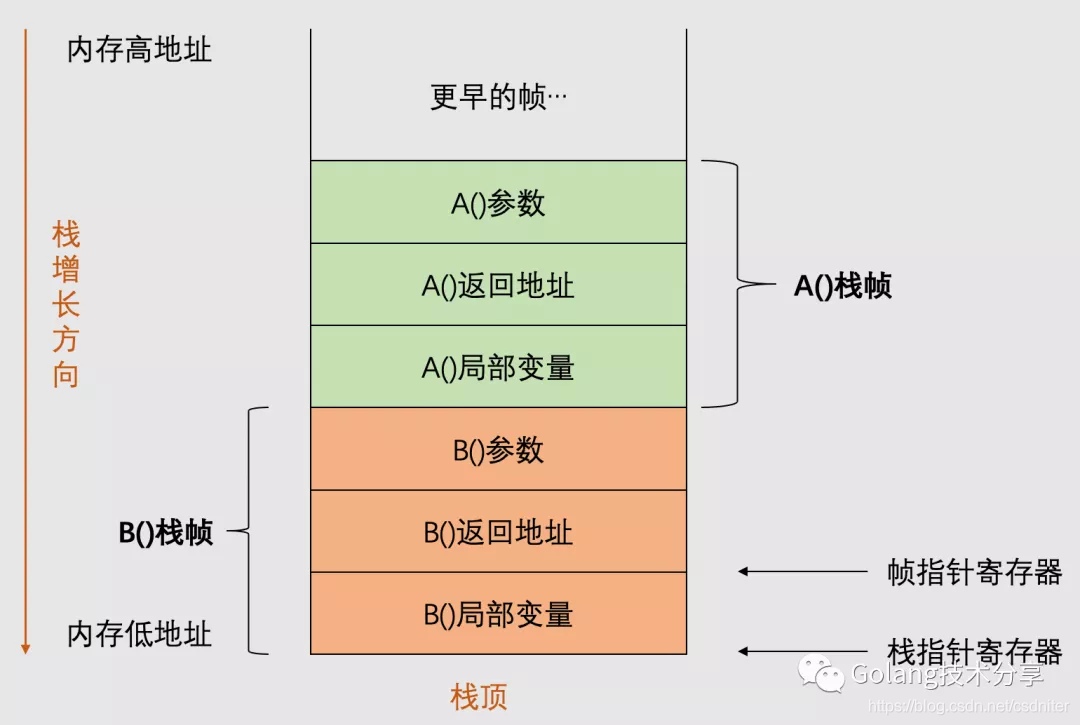
与栈不同的是,应用程序在运行时只会存在一个堆。狭隘地说,内存管理只是针对堆内存而言的。程序在运行期间可以主动从堆上申请内存,这些内存通过Go的内存分配器分配,并由垃圾收集器回收。
栈是每个goroutine独有的,这就意味着栈上的内存操作是不需要加锁的。而堆上的内存,有
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1187
1187

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









