



/**
* @author jiasongfan
* @date 2022/5/31
* @apiNote
*/
import org.apache.flink.api.common.state.{ListState, ListStateDescriptor, ValueState, ValueStateDescriptor}
import org.apache.flink.streaming.api.functions.KeyedProcessFunction
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows
import org.apache.flink.util.Collector
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.api.windowing.windows.TimeWindow
import org.apache.flink.api.common.functions.AggregateFunction
import org.apache.flink.api.common.typeinfo.{TypeHint, TypeInformation}
import org.apache.flink.streaming.api.scala.function.WindowFunction
import scala.collection.JavaConverters.iterableAsScalaIterableConverter
object Test06 {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val text: DataStream[String] = env.socketTextStream("hdp1", 9999)
val mapDS: DataStream[StuScore] = text.map(line => {
val li: Array[String] = line.split(",")
StuScore(li(0), li(1), li(2).trim.toInt,li(3).trim.toLong*1000)
})
//分数出现连续下滑报警
val timeDS: DataStream[StuScore] = mapDS.assignAscendingTimestamps(_.ts)
val keyS: KeyedStream[StuScore, String] = timeDS.keyBy(_.id)
val winDS: WindowedStream[StuScore, String, TimeWindow] = keyS.window(TumblingEventTimeWindows.of(Time.seconds(5)))
val avgDS: DataStream[Ws] = winDS.aggregate(new MyAvg2, new MyAvgFunc2)
val keyS2: KeyedStream[Ws, Long] = avgDS.keyBy(_.end)
val top3:DataStream[List[Ws]] = keyS2.process(new TopNProcess)
env.execute()
}
}
class MyAvg2 extends AggregateFunction[StuScore,(Int,Int),Double] {
//初始化中间变量
override def createAccumulator(): (Int, Int) = (0,0)
//局部运算
override def add(in: StuScore, acc: (Int, Int)): (Int, Int) = (acc._1+in.score,acc._2+1)
//合并局部数据
override def merge(acc: (Int, Int), acc1: (Int, Int)): (Int, Int) = (acc._1+acc1._1,acc._2+acc1._2)
//最终输出
override def getResult(acc: (Int, Int)): Double = acc._1/acc._2
}
//[IN, OUT, KEY, W <: Window]
//输入,输出
case class Ws(start:Long,end:Long,stuid:String,avgscore:Double)
class MyAvgFunc2 extends WindowFunction[Double,Ws,String,TimeWindow] {
override def apply(key: String, window: TimeWindow, input: Iterable[Double], out: Collector[Ws]): Unit = {
for(t <- input){
out.collect(Ws(window.getStart,window.getEnd,key,t))
}
}
}
//<K, I, O>
class TopNProcess extends KeyedProcessFunction[Long,Ws,List[Ws]]{
val descriptor = new ListStateDescriptor[Ws](
"buffered-elements",
TypeInformation.of(new TypeHint[Ws]() {})
)
lazy val liststate: ListState[Ws] = getRuntimeContext.getListState(descriptor)
override def processElement(i: Ws, context: KeyedProcessFunction[Long, Ws, List[Ws]]#Context, collector: Collector[List[Ws]]): Unit = {
//添加数据
liststate.add(i)
context.timerService.registerEventTimeTimer(i.end)
}
override def onTimer(timestamp: Long, ctx: KeyedProcessFunction[Long, Ws, List[Ws]]#OnTimerContext, out: Collector[List[Ws]]): Unit = {
out.collect(liststate.get().asScala.toList.sortBy(-_.avgscore).take(3))
}
}
需要注意
1.先求出平均值 之后使用的是结果的时间进行keyby
2.然后在process
3.agg的输出 记得写一个样例类 在process里面使用
4.list的找
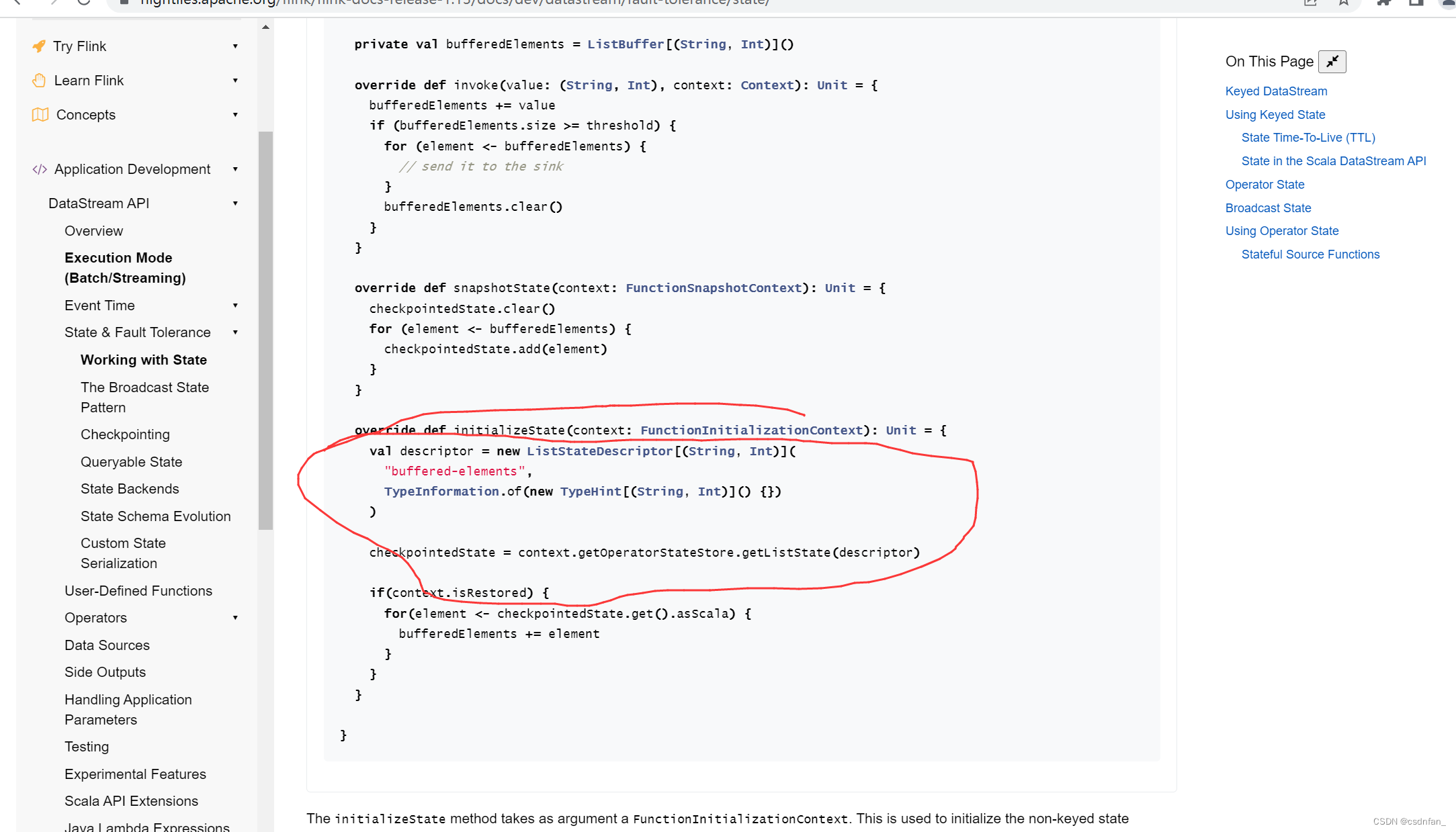
需要修改第二个为getruntime
5.输出记得asscala


















 1936
1936

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









