




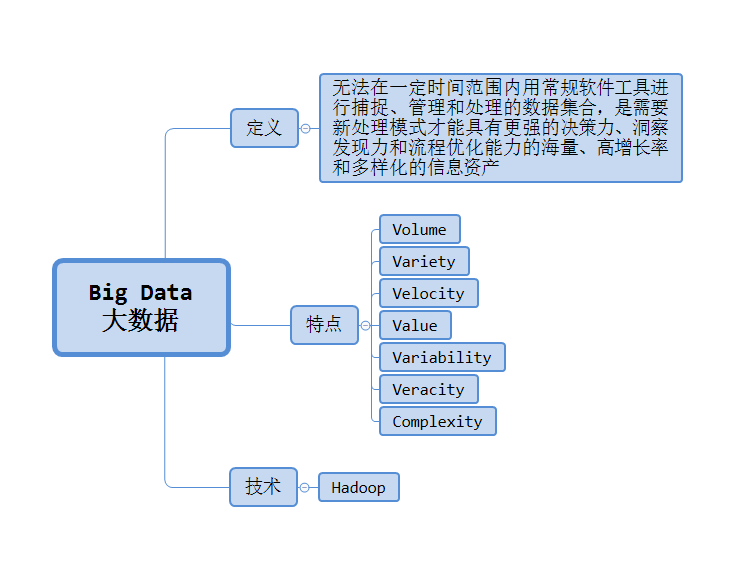
 本文是作者大数据学习系列的先导,介绍了学习方法和使用思维导图辅助学习。阐述了大数据的定义、特征(5V模型),强调了数据的海量、多样性和高速增长,并指出传统方式无法应对大数据的存储和计算需求,引出了分布式系统和Hadoop在大数据技术中的重要性。
本文是作者大数据学习系列的先导,介绍了学习方法和使用思维导图辅助学习。阐述了大数据的定义、特征(5V模型),强调了数据的海量、多样性和高速增长,并指出传统方式无法应对大数据的存储和计算需求,引出了分布式系统和Hadoop在大数据技术中的重要性。
📚这是一个文章系列的先导
1️⃣关于标题
首先,标题很直白,这篇文章与大数据学习有关,而实际上这将会是系列文章,本篇是整个系列的先导。
其次,学习知录并不是“学习之路”的错写。比起将一步步学习看作是在走一条长长的路并将其记载下来,我更倾向于将学习的过程理解为“不知➡️了解➡️熟悉➡️掌握➡️怀疑自不知”的螺旋向上、不断摸索的求知过程,引用我的学习榜样敖丙的座右铭——你知道的越多,你不知道的越多,标题的“知”表达的就是这层意思,录就是记录的意思了,系列记录的是大数据技术求知的文章,文章不一定是静态的,而可能会根据学习的进度、深度、广度做必要的更新。
2️⃣如何学习
必须放在前头声明的是,笔者是大数据技术的初学者,在这里输出的学习方式和风格仅保证适合自己,不做推荐,读者大大们理性看待。
使用的笔记工具以思维导图XMind和绘图工具Visio为主
-
使用思维导图将大数据技术栈的知识点串起来,当学习进行到某个具体的技术时,深入它,以达到既深入抽丝剥茧,也不忘统揽全局的效果
-
某些可以做关联想象的技术和原理,我就会想象先行,帮助自己先简单地理解它,然后才去细究。以HDFS的架构为例,我会把它和现实中的仓储公司与业务做联想
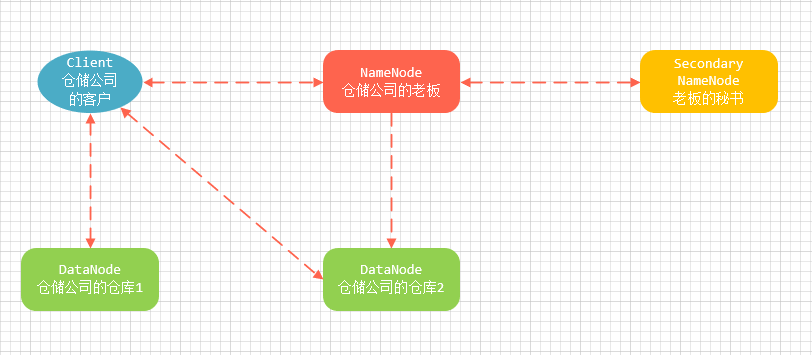
3️⃣大数据的简介
大数据的定义
什么是大数据呢?偏学术的诠释如下
txt 大数据是指无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。
说白了,大数据是信息资产,信息时代,数据为王。计算机存储单位一般用B、KB、MB、GB、TB、PB、EB、ZB、YB、BB、NB、DB来表示,它们之间存在着每两级之间是1024倍的进制关系。
大数据的特征
大数据的特征是随着它的发展而不断丰富的,早期IBM定义了大数据的特征有**Volume(海量)、Variety(多样)、Velocity(高速)三个,后来又有学者将Value(价值)**加到其中,随着时间推移、行业推动和人们思考的进一步完善,又有三个大数据的特性被提出:Variability(易变),Veracity(准确性)、Complexity(复杂性)。
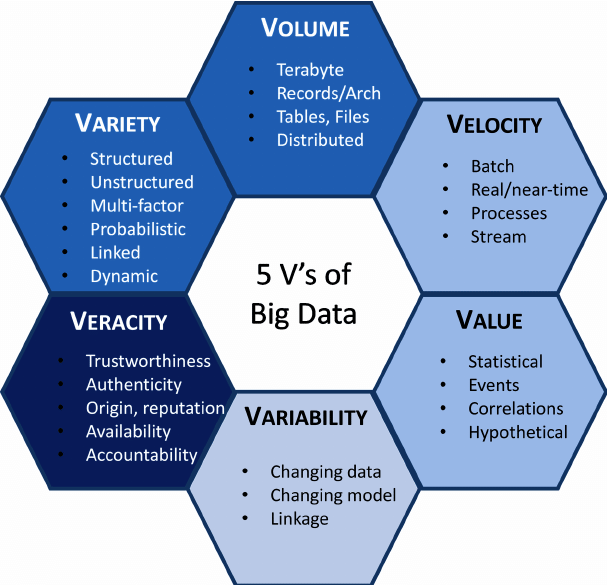
The five V’s of Big Data (改编自("IBM大数据平台--将大数据带入企业",2014))
-
Volume 海量
1986年,全球有0.02EB(约2.1万TB)的数据量,到2007年,全球数据量已增长到280EB(约3亿TB)的数据量;近年来伴随着云计算、大数据、物联网、人工智能等信息技术的快速发展和传统产业数字化的转型,数据量呈现几何级增长,2019年底信通院发布了大数据白皮书(2019)表示全球数据量在该年有望达到41ZB;据IDC预测,全球数据总量预计2020年达到44个ZB,我国数据量将达到8060个EB。ZB和EB是什么概念呢?以EB为例,如果一个15秒的小视频大小为1MB,那么总量1EB的小视频可以让我们看52万年以上,由上可见,我们所处的世界的数据量已经大到爆。
-
Variety 多样化
泛指数据类型及其来源的多样化 (Troester, 2012),进一步可以把数据的结构归纳为结构化(structured)、半结构化(semi-structured)、非结构化(unstructured) (SAS, 2014),具体表现为网络日志、图片、音频、视频、地理位置信息等,多类型的数据对数据的处理能力有更高的要求。
-
Velocity 高增速
在大数据时代,数据的产生是高速的,因此对数据的存储和分析也必须要高速进行,比如电商网站的个性化推荐尽可能要求实时完成推荐,这也是大数据区别于传统数据挖掘的显著特征。
-
Value 价值性
关于大数据特征之Value有好几种解释:低价值/有价值/高价值的,三种结论的得出都有落脚点。因为数据是海量的,所以价值密度就低,在大体积低密度的数据中挖掘数据的价值可以看作是大海捞针,即使如此,我们依然要承认海里的针确实值得去捞,而在催生了大量数据的互联网大海中结合业务逻辑、通过强大的机器算法来挖掘数据价值,便是大数据时代最需要解决的高难度课题。
-
Variability 易变性
伴随数据高增速的特征,数据流会呈现一种波动的特征。不稳定的数据流会随着日、季节、特定事件的触发出现周期性峰值 (Troester, 2012)
-
Veracity 准确性
也有资料将这点称为真实性或数据保证(data assurance)。它指的是保证数据的质量/完整性/可信度/准确度,大数据的数据是由多个不同的方式、渠道收集的,数据分析和输出结果的错误程度和可信度在很大程度上取决于收集到的数据质量的高低 (W.Raghupathi & Raghupathi, 2014),我们需要在使用数据进行商业洞察之前检查数据的准确性,没有数据保证,大数据分析就毫无意义
-
Complexity 复杂性
大数据的复杂性体现在数据的管理和操作上。随着数据来源和数据量的爆发,各种不同渠道数据的大量涌现,数据的管理和操作已经变得原来越复杂,如何抽取,转换,加载,连接,关联以把握数据内蕴的有价值信息已经变得越来越有挑战性
4️⃣分布式与大数据技术

由于数据的日益倍增,我们传统的采集、存储、处理、分析数据的方式已经越来越不好使了,“不好使”体现在两个大方面,一个是存储,一个是计算,海量的数据可以将集中式环境轻松击垮。
以文件的读取与分析为例,数据量级只有KB时,我们可以写个简单的程序或脚本处理,甚至可以用个人机完成这项任务。
待数据量级上MB时,用同样的程序和服务器处理就可能变得捉襟见肘了,如果算法欠佳或是服务器配置不高,那么这项任务的处理效率可能肉眼可见地降低,于是我们会尝试优化处理逻辑,升级机器配置,一顿操作猛如虎后,我们在一定程度上缓解了处理效率低下的问题。
可现在是大数据时代啊,单台机器性能再高也是有天花板的,集中式系统奉行的”个人英雄主义“已经无法进行下去了,我们只能朝”众人拾柴火焰高“的方向去思考,于是分布式系统诞生了。
分布式系统就是为解决海量数据的存储和计算问题而生的,而支撑分布式系统、在分布式环境中大放光彩的,我们统称其为大数据技术。Hadoop——一个适合大数据的分布式存储和计算平台,便是我大数据技术学习的开始。
5️⃣总结
📚这是一个文章系列的先导
这句话写给自己。这个系列写的是大数据学习,但在本篇文章写作时笔者尚未对大数据有一个全面、系统、完整的认识,“笃定”会写一个系列,实际上是给自己立的flag,系列文章会随着笔者学习的进度、深度、广度持续更新,若文章存在任何疏漏或者建议,还请各位看官老爷小姐留言赐教。
本篇后半部分对大数据做了简单的介绍,主要介绍了大数据的特征,到分布式存储和计算,最后引出适合大数据的分布式存储和计算平台——Hadoop ,下一篇就来搞搞它,从Hadoop开始逐步切入大数据技术栈。


















 724
724

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









