



- 安装python,以及相关库:
python.exe -m pip install --upgrade pip #可以先更新pip版本,非必要
pip install pandas scikit-learn xgboost joblib
- 训练模型,提前准备数据,excel/csv格式
表头数据:
A stat_cost 消耗金额
B show_cnt 展示数
C click_cnt 点击数
D convert_cnt 转化数
E arpu ARPU值,充值/消耗
F money 充值金额
G roi roi
H ctr 点击率,点击数/展示数100%
I convert_rate 转化率,转化数/点击数100%
J active_rate 激活率,激活数/点击数*100%
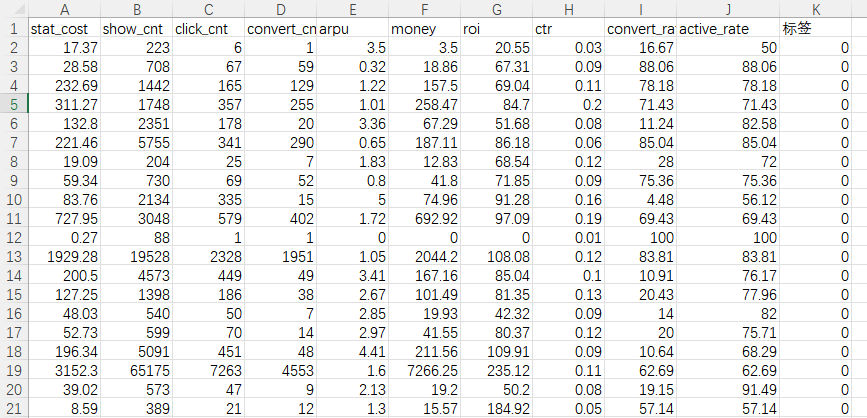
K列是优化动作,需要打好动作标签,如果数据没有,那么就自己打,不然只有数据,没有动作。
我打的标签规则是:
标签 ID 优化动作名称 触发规则
0 优化素材 / 文案 ctr(点击率)<0.3%(提高了原 0.2% 的阈值,减少该标签出现频率)
1 优化落地页 / 转化链路 ctr≥0.3% 且 convert_rate(转化率)<20%
2 收缩定向(减少无效流量) roi<1.0(原 0.9)且 active_rate(激活率)<60%(原 50%)
3 扩大流量(提高出价 / 放宽定向) show_cnt(展示数)<1000 且 roi≥1.2(原 1)
4 无需调整 所有指标达标(ctr≥0.3%、convert_rate≥20%、roi≥1.2 等)
如果你只有数据,没有动作,就先手动打标签训练模型,我使用python处理excel给K列打标签:
import pandas as pd
# 加载数据
df = pd.read_csv('/mnt/data.csv')
# 定义函数,根据调整后的规则返回对应的标签
def get_label(row):
# 提高点击率阈值到 0.3%,减少标签 0 的出现
if row['ctr'] < 0.3:
return 0
elif row['ctr'] >= 0.3 and row['convert_rate'] < 20:
return 1
# 调整 roi 和 active_rate 的阈值组合
elif row['roi'] < 1.0 and row['active_rate'] < 60:
return 2
elif row['show_cnt'] < 1000 and row['roi'] >= 1.2:
return 3
return 4
# 应用函数,添加标签列
df['标签'] = df.apply(get_label, axis=1)
# 查看标签分布
label_distribution = df['标签'].value_counts()
print('标签分布:')
print(label_distribution)
# 将结果保存为 csv 文件
csv_path = '/mnt/data_labeled_adjusted.csv'
df.to_csv(csv_path)
执行上面训练模型代码,接下来,我将使用带标签的数据 data.csv 训练一个随机森林分类模型,并将训练好的模型保存下来,以便后续对新的广告数据进行预测。
执行python train_model.py 最后生成两个文件:
- label_encoder.pkl 是生成的 标签编码器
- 广告优化模型_XGBoost.pkl 是训练出来的 模型文件
- 后续你可以使用这个模型对新的广告数据进行预测,具体操作如下:
import pandas as pd
import joblib
import numpy as np
# 加载模型
loaded_model = joblib.load('C:/Users/zhagnshi/Desktop/moxing/py/广告优化模型_XGBoost.pkl') # 根据实际路径修改
label_encoder = joblib.load('C:/Users/zhagnshi/Desktop/moxing/py/label_encoder.pkl') # 根据实际路径修改
# 准备新的广告数据(示例)
new_ad_data = pd.DataFrame({
'stat_cost': [100.0],
'show_cnt': [1500],
'click_cnt': [10],
'convert_cnt': [2],
'arpu': [5.0],
'money': [100.0],
'roi': [1.5],
'ctr': [0.67],
'convert_rate': [20.0],
'active_rate': [50.0]
})
# 进行预测
prediction_encoded = loaded_model.predict(new_ad_data)
prediction = label_encoder.inverse_transform(prediction_encoded)
print('预测结果:', prediction)
调用模型进行预测
python predict_model.py
- 增量训练模型
正确的 “增量训练” 操作(针对 scikit-learn 接口的 XGBoost 模型)
如果你是用joblib保存的.pkl模型(即XGBClassifier),增量训练的正确步骤如下:
用joblib加载已保存的模型
import joblib
import pandas as pd
from sklearn.preprocessing import LabelEncoder
# 1. 加载用joblib保存的XGBClassifier模型
model = joblib.load('C:/Users/zhagnshi/Desktop/moxing/py/广告优化模型_XGBoost.pkl')
# 2. 加载新数据(和之前的特征、标签格式一致)
new_df = pd.read_csv('new_data.csv') # 你的新广告数据
X_new = new_df[['stat_cost','show_cnt', 'click_cnt', 'convert_cnt', 'arpu','money', 'roi', 'ctr', 'convert_rate', 'active_rate']]
y_new = new_df['标签'] # 新数据的标签(按你的规则打好的)
# 3. 对标签编码(如果之前编码过,需用同一个LabelEncoder)
# 注意:必须加载之前保存的LabelEncoder,不能重新初始化!
label_encoder = joblib.load('C:/Users/zhagnshi/Desktop/moxing/py/label_encoder.pkl')
y_new_encoded = label_encoder.transform(y_new) # 用已有的编码器转换新标签
# 4. 增量训练(在新数据上继续训练)
model.fit(
X_new,
y_new_encoded,
verbose=False # 不输出训练日志,可选
)
# 5. 保存更新后的模型
joblib.dump(model, 'C:/Users/zhagnshi/Desktop/moxing/py/广告优化模型_XGBoost_updated.pkl')
为什么这样可行?
XGBClassifier的fit方法默认会 “累加训练”:第一次训练是从 0 开始,后续调用fit会在已有模型的基础上,用新数据继续优化参数,实现增量训练。
必须用同一个LabelEncoder 处理新标签:否则标签编码不一致会导致模型混乱(比如原来的 “0” 代表 “优化素材”,新编码器可能把 “0” 对应别的动作)。
总结:避免报错的核心
用joblib.save保存的模型 → 必须用joblib.load加载。
用model.save_model()保存的原生模型 → 必须用Booster.load_model()加载。
按上面的步骤操作,就能基于新数据增量优化模型了。如果还有问题(比如新数据格式不对),可以把具体报错发给我,我再帮你调~

















 2147
2147

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









