




本文来源公众号“OpenCV与AI深度学习”,仅用于学术分享,侵权删,干货满满。
原文链接:https://mp.weixin.qq.com/s/qbTpF4pozQZ9flG1mYCi9A
立体3D视频可以在用户佩戴Apple Vision Pro 类XR设备时,模仿人类双眼观察世界的方式(左眼和右眼从两个略微不同的角度观察世界,大脑会将这两幅图像进行处理和融合,从而产生深度感),获得更加沉浸的观看感受。
但制作高质量的立体视频,通常需要专业的双摄像设备,成本高昂、流程复杂,对普通创作者来说门槛不低。
那有没有可能,把我们手机里、网络上存量巨大的普通2D视频,直接变成效果逼真的3D立体视频呢?这正是本文要介绍的“StereoWorld”想要解决的问题。
来自北京交通大学、多伦多大学等机构的研究者们提出了一个端到端的框架,能够将任意单目视频(也就是我们常见的2D视频)转换成具有出色视觉保真度和几何一致性的立体视频。
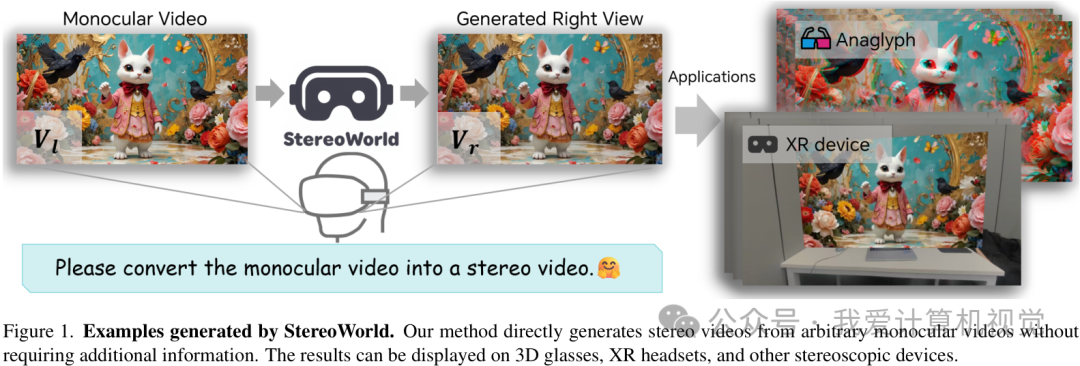
简单来说,它的核心思想就是利用一个预训练的视频生成模型,通过一种巧妙的“几何感知”方法,不仅生成右眼的画面,还确保这个画面和左眼(原始视频)组合起来时,能形成稳定、舒适的3D效果。

-
论文标题:StereoWorld: Geometry-Aware Monocular-to-Stereo Video Generation
-
作者:Ke Xing, Xiaojie Jin, Longfei Li, Yuyang Yin, Hanwen Liang, Guixun Luo, Chen Fang, Jue Wang, Konstantinos N. Plataniotis, Yao Zhao, Yunchao Wei
-
机构:北京交通大学,Dzine AI,多伦多大学
-
论文地址:https://arxiv.org/abs/2512.09363
-
项目主页:https://ke-xing.github.io/StereoWorld/
当前技术的困境
在StereoWorld之前,将2D视频转为3D主要有两条技术路线。
第一种是“三维重建”的思路,比如用经典的SfM(Structure-from-Motion)或者酷炫的NeRF、3D高斯溅射等技术,先尝试把视频里的场景恢复成3D模型,然后再从一个新的视角(右眼位置)渲染出画面。听起来很完美,但在真实世界的动态、复杂的视频面前,这种方法很容易因为相机位姿估计不准或者物体运动,导致生成的3D效果不稳定,看着头晕。
第二种是目前更主流的“深度-扭曲-修复”管线。它先估计出视频每一帧的深度图,然后根据深度信息将左眼图像“扭曲”到右眼的位置,最后用一个修复模型(通常是扩散模型)来填充扭曲后产生的空白区域。这个方法虽然直接,但“修复”这一步和“立体几何”是脱节的,很容易破坏像素级别的对应关系,导致纹理细节错乱、时序上闪烁等问题。
StereoWorld则另辟蹊径,它认为不应该将生成过程割裂开,而是要让模型在生成右眼画面的同时,就直接“感知”到3D几何结构。
StereoWorld的核心方法
为了实现这个目标,研究者们设计了一个精巧的框架。整个过程可以理解为,模型以左眼视频作为输入,直接端到端地生成对应的右眼视频。
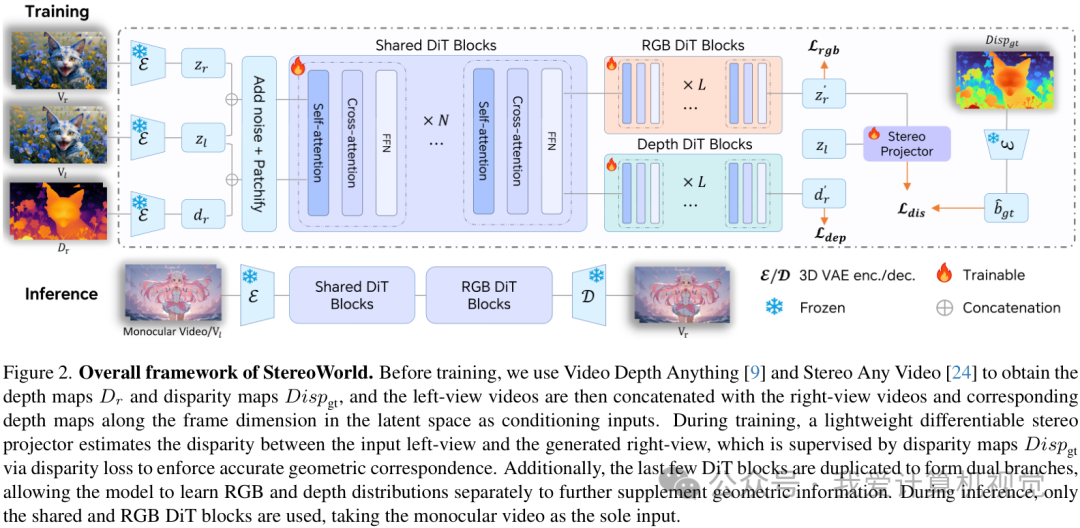
其成功的关键在于一种被称为“几何感知正则化” (Geometry-aware Regularization)的训练策略。这个策略包含两个互补的部分:视差监督和深度监督。
视差监督 (Disparity Supervision)
为了让生成的右眼画面和左眼形成准确的立体对应,模型在训练时会引入一个轻量级的、可微分的“立体投影仪”。这个投影仪会实时估计输入左眼画面和生成右眼画面之间的视差图,并与一个预先计算好的“真实”视差图进行比较,通过一个损失函数 L_dis 来惩罚偏差。
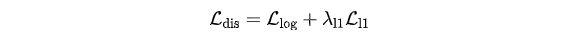
这个损失函数能够显式地引导模型去学习左右视图之间的几何对应关系,从而生成几何上一致的立体视频。
深度监督 (Depth Supervision)
然而,只靠视差监督还不够。因为当相机水平移动拍摄左右眼视图时,总会有一些区域只在其中一个视图中可见,我们称之为“非重叠区域”。视差只能处理重叠的部分,对这些新出现的区域就无能为力了。

为了解决这个问题,研究者们引入了额外的深度监督。他们让模型不仅要生成右眼的RGB图像,还要同时预测出右眼的深度图。通过一个专门的深度损失 L_dep,来保证生成的场景结构是合理的。
为了让模型能同时处理好RGB和深度这两种不同的数据分布,他们还对网络结构做了个小改动:在DiT(Diffusion Transformer)模型的最后几层,将参数复制成两个独立的分支,一个专门负责RGB,另一个专门负责深度。这样一来,模型既能学习共享的底层特征,又能在高层对纹理和结构进行精细化的分工处理。
最终,总的训练目标函数是三者的结合:
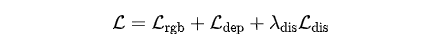
这种集成式的目标函数,共同促进了视觉保真度和几何正确性,让生成的3D视频既好看又真实。
处理高分辨率和长视频
模型训练时的分辨率是480p,时长也只有几秒。为了能处理更高分辨率、更长的视频,StereoWorld采用了两种“切片”策略。
-
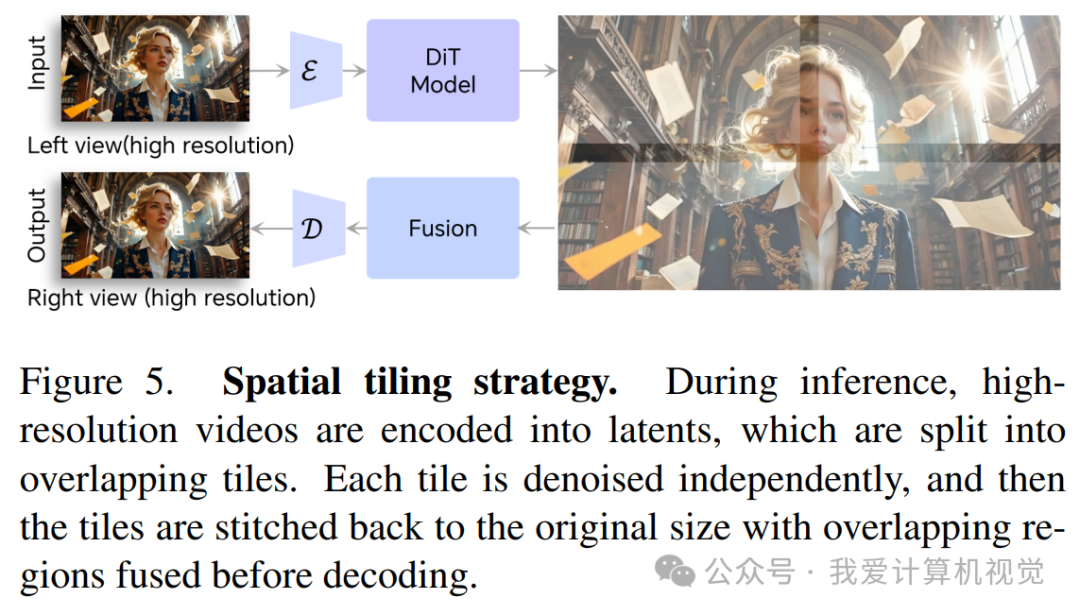
空间切片:对于高分辨率视频,先将其编码到隐空间,然后切成带重叠的小块。每个小块独立进行去噪生成,最后再拼接融合起来。这样就实现了高效的高分辨率合成。
-
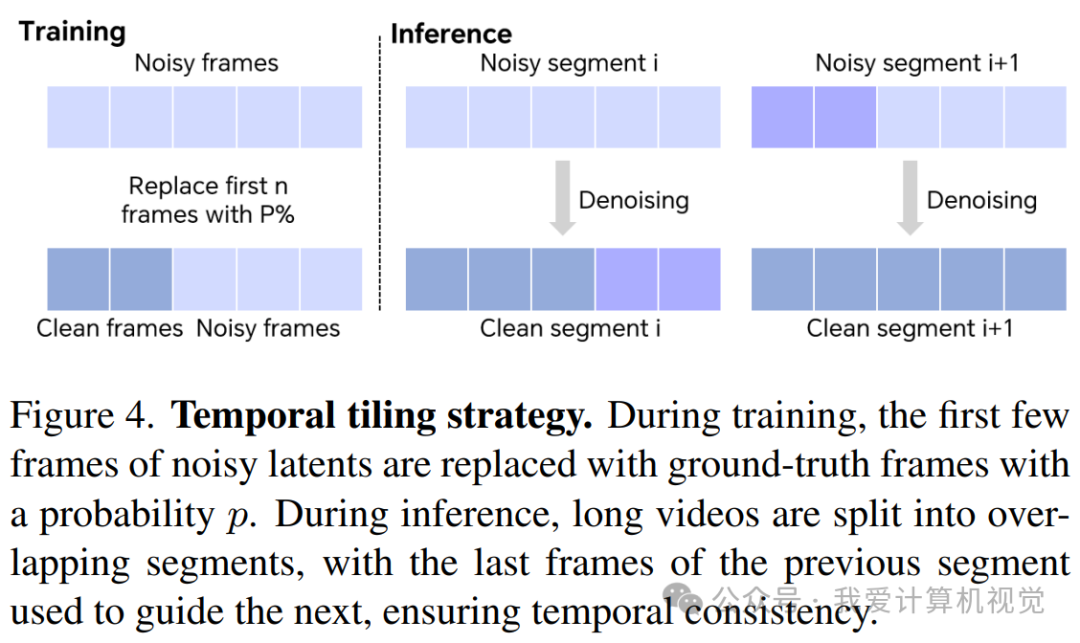
时间切片:对于长视频,同样是切分成带重叠的片段。前一个片段的最后几帧会被用来引导后一个片段的生成,像接力一样,保证了时间上的连贯性。
海量数据与惊艳效果
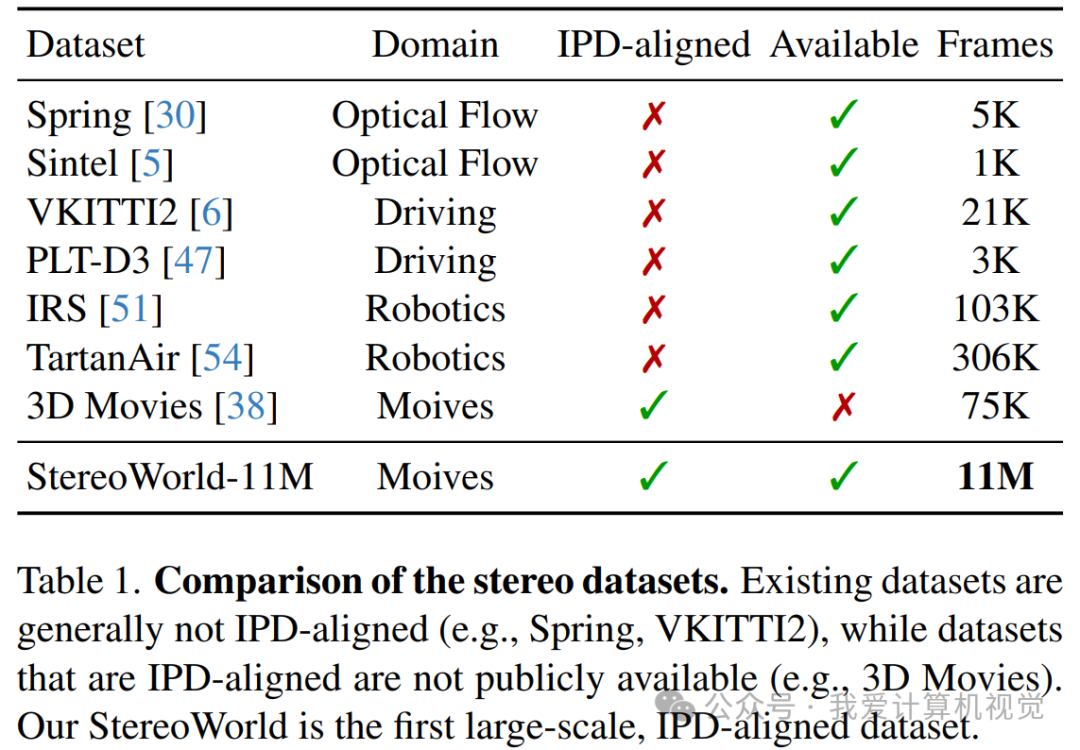
高质量的训练数据是成功的关键。现有的立体数据集要么是为自动驾驶等任务设计的,相机基线(可以理解为“眼间距”)过大,不符合人眼观看习惯;要么就是不公开。
为此,团队下大力气构建了一个全新的、专为人类感知优化的立体视频数据集——StereoWorld-11M。他们从网上收集了上百部高清蓝光3D电影,涵盖了动画、写实、科幻等多种类型,经过清洗和处理,最终得到了一个包含超过 1100万帧、与自然人眼瞳距(IPD)对齐的高质量数据集。这是目前第一个如此大规模且符合人类观看习惯的公开立体视频数据集。
有了强大的方法和海量的数据,StereoWorld的效果自然非常出色。
从定性对比来看,无论是细节保留、与左眼的视觉一致性,还是非常考验模型能力的文字渲染,StereoWorld都全面优于之前的方法。

从定量结果来看,基于图像的基线方法GenStereo和无训练方法SVG的综合得分最低,这与定性观察结果一致。
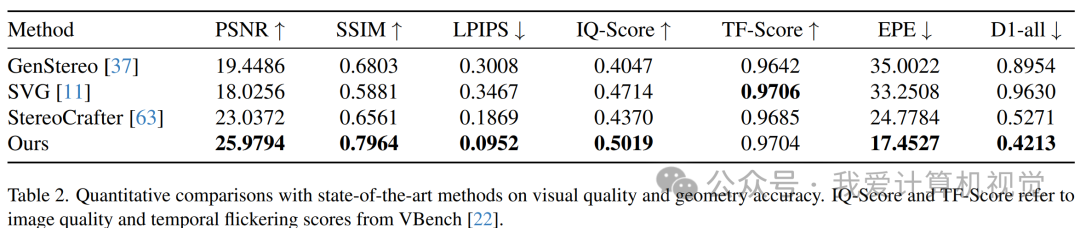
在时间维度上,其他方法可能会出现闪烁或不稳定的情况,而StereoWorld则保持了卓越的时间一致性,画面流畅自然。

写在最后
总而言之,StereoWorld的出现,为我们提供了一个将海量2D视频资源转化为沉浸式3D体验的新思路。它通过创新的几何感知正则化和专门构建的大规模数据集,显著提升了单目到立体视频生成的质量和真实感。不过文中称速度还需要进一步优化,目前的模型转一段几秒钟的视频需要6分钟。
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









