






本文来源公众号“AI生成未来”,仅用于学术分享,侵权删,干货满满。
原文链接:https://mp.weixin.qq.com/s/NBun9lSWDFr-RpyL8UeJbg

文章链接:https://arxiv.org/abs/2511.18271
本文第一作者Tianyang Han是美团MeiGen团队的算法研究科学家,主要研究方向是图像生成和多模态大语言模型。
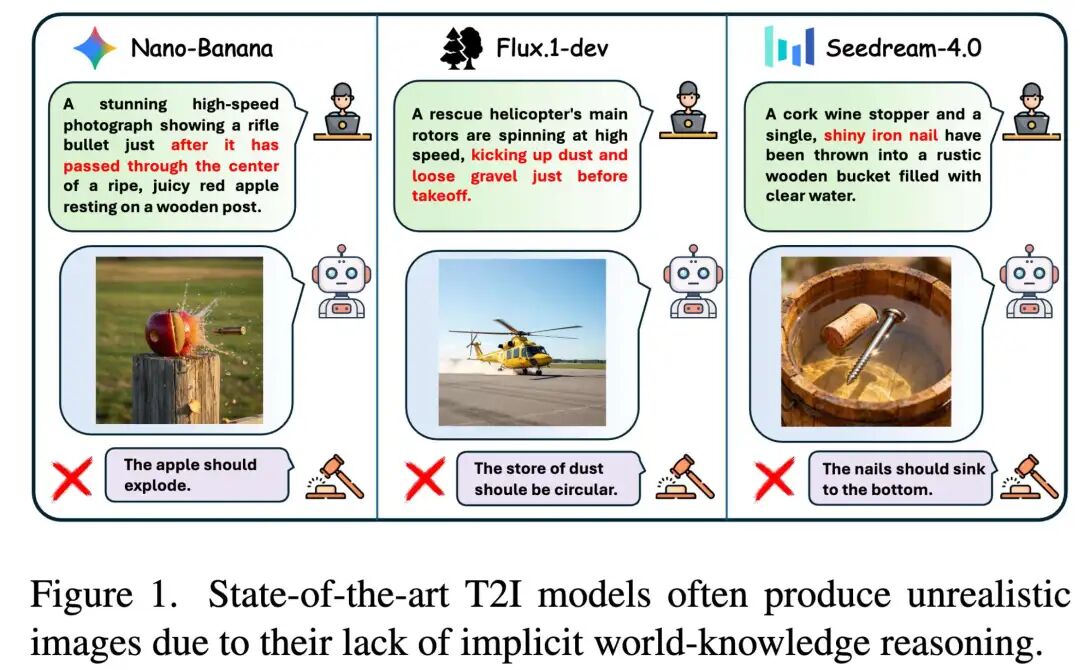
亮点直击
PicWorld,一个旨在评估文本到图像模型隐含推理能力的综合性基准。据我们所知,PicWorld是首个大规模、系统性的基准,专门用于评估模型对隐含世界知识(如遵循基本物理定律)和逻辑因果推理的理解。
提出了PW-Agent,一种新颖的自动化评估框架,它采用基于智能体分解的层次化评估。这种多智能体流程系统地将复杂提示分解为可验证的物理和逻辑组件,从而实现对模型在基准上表现的可复现和可扩展分析。
全面实验表明,现有的文本到图像模型,特别是开源模型,在物理和逻辑推理能力上表现出局限性,这凸显了未来需要改进的关键领域。
总结速览
解决的问题
-
核心能力缺失:当前文生图模型缺乏对隐含世界知识和物理因果推理的理解。它们能生成逼真且符合指令的图像,但在需要常识和逻辑推理的提示词上经常失败。
-
评估体系不完善:现有的评估方法要么侧重于组合对齐(即图像是否包含提示词中提到的元素),要么依赖单轮视觉问答进行打分。这导致对知识基础、多物理交互和可审计的证据等关键维度的测试严重不足。
-
评估方法不可靠:依赖多模态大语言模型进行整体评判的现有方法存在幻觉(看到不存在的东西)、中心倾向偏差(打分趋于中庸)等问题,无法进行精细、可靠的评估。
提出的方案
-
PicWorld基准:提出了第一个用于系统评估文生图模型隐含世界知识掌握程度和物理因果推理能力的综合基准。它包含1,100个提示词,涵盖三个核心类别:
-
物理世界
-
抽象知识
-
逻辑与常识推理
-
-
PW-Agent评估框架:设计了一个基于证据的多智能体评估管道,以进行分层、精细化的评估。该框架包含四个专门化的智能体:
-
世界知识提取器:将提示词分解为原子化的、可图像验证的期望。
-
假设构建器:根据分解出的期望,构建可验证的视觉问题。
-
视觉感知器:从图像中寻找视觉证据来回答问题。
-
推理评判器:通过基于演绎的连续评分方案,结合检查清单式的原子性和重要性权重,汇总答案并给出最终分数。
-
应用的技术
-
多模态大语言模型:
-
基准构建:利用先进的MLLM(文中提及Gemini-2.5-Pro)来生成初始提示词,并辅以人工严格筛选以确保质量。
-
评估框架:PW-Agent的核心组件(如WKE, HF, VP, RJ)本质上是基于MLLM构建的智能体,协同完成解析、提问、感知和推理评判的任务。
-
-
多智能体系统:采用分工协作的多智能体框架,将复杂的评估任务分解为更专业、可管理的子任务,以提高评估的准确性、可靠性和可解释性。
-
分层评估维度:PW-Agent从三个层次对图像进行评估:
-
指令遵循
-
物理/逻辑真实性
-
细节与细微差别
-
达到的效果
-
系统性评估:PicWorld基准首次系统性地测试了文生图模型对场景隐含后果的理解,而不仅仅是其显式描述的组件。
-
精细化和可解释的分析:PW-Agent通过分解提示词和基于证据的验证,提供了细粒度、多层面的分数,能够深入且可解释地分析模型的推理能力缺陷。
-
揭示模型根本性局限:对17个主流文生图模型的全面分析表明,它们在不同程度上普遍存在对隐含世界知识和物理因果推理能力的根本性局限。
-
指明未来方向:该研究强调了未来文生图系统需要集成推理能力和知识的架构,而不仅仅是提升图像质量和显式指令跟随能力。
PicWorld 基准测试
当前的评估方法主要关注语义的一致性和组合的准确性,在很大程度上未对模型理解基本世界动态的能力进行评估。为了填补文本生成图像(T2I)模型隐性世界认知评估的空白,本工作构建了 PicWorld,旨在对 T2I 模型学习到的隐性自然规律进行整体且细粒度的评估。
PicWorld 基准构建
如下图 3 所示,PicWorld 包含总共 1,100 个精心策划的提示词(prompts),系统地组织在三个主要领域中。本工作手动设计了复杂的提示词模板,每个模板都针对世界理解的特定方面。随后,利用 Gemini-2.5-Pro 生成了大量的候选提示词语料库,并经过人类专家的严格筛选和完善,以确保清晰度和复杂性。具体而言,这三个部分的细节如下:
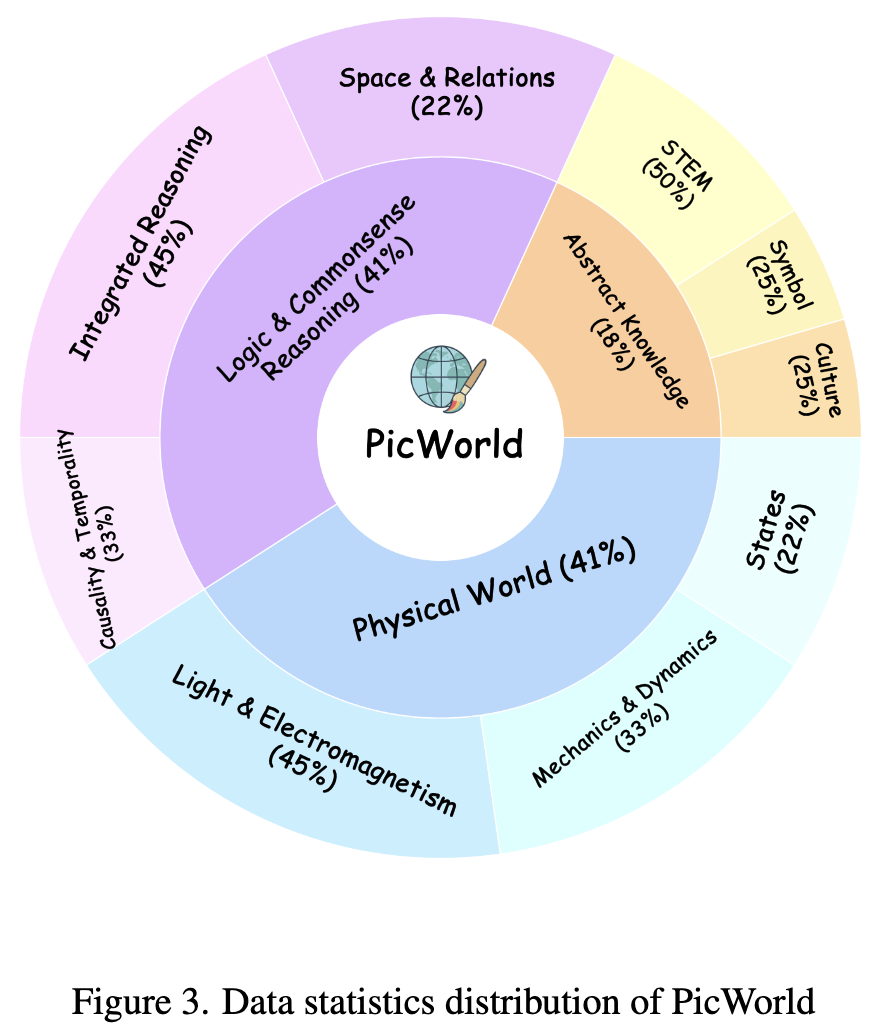
物理世界
PicWorld 的物理世界领域旨在评估模型理解和视觉模拟支配现实的基本规律的能力。一个真正理解世界的模型不仅应该识别物体,还应该呈现它们在各种物理约束下的行为。缺乏这种内在物理引擎的模型只能是一个非智能的生成器,只能描绘静态物体,无法捕捉世界的动态因果本质。本工作将该领域进一步细分为三个核心类别:
-
力学与动力学:评估模型对变形、运动、流体动力学和抛体运动等概念的理解。
-
光与电磁学:考察模型对反射、折射、阴影和电现象等现象的掌握情况。
-
热力学:评估相变和热传递的知识。 最终,本工作为此方面生成了 550 个提示词。
抽象知识
该领域包含 200 个提示词,旨在评估模型理解并准确再现纯粹存在于人类认知和文化空间中的概念的能力。缺乏这种能力的模型只能生成字面描绘,而无法掌握概念、图表和文化叙事在世界中扮演的抽象符号角色。它分为三个类别:
-
STEM 概念 :测试模型作为精确事实概念的视觉知识库的能力。例如,“水分子的球棍模型 的干净、极简主义科学教科书插图”这一提示词直接测量模型的化学结构知识,其中原子类型、数量和键角的准确性至关重要。
-
文化与历史 :评估模型对文化和历史意义系统的熟悉程度。
-
人文符号系统 :要求模型进一步分解为理解非叙事符号,如旗帜、图标和乐谱。
逻辑与常识推理
该领域评估需要模型推断逻辑关系并构建连贯场景的高阶认知能力。没有这种推理能力的模型生成的图像虽然包含正确的元素,但在逻辑上是有缺陷的、空间不一致的或因果关系破裂的。本工作将该领域构建为三个类别:
-
因果性与时间性:旨在测试模型对因果关系和时间流逝的理解。例如,“一把湿的、黑色的长柄伞被带进室内,打开并立在光滑、抛光的木地板上”这样的提示词,挑战模型推断出伞下有干燥的地板以及周围有一滩水这一逻辑结果。
-
空间关系:探究模型对复杂和精确空间排列的理解。
-
综合推理:设计为对最先进模型(SOTA)的上限测试,要求它们同时模拟和协调多个不同的物理定律。 本工作最终为此方面生成了 350 个提示词。
如下图 2 所示,本工作展示了 PicWorld 的一些数据样本。

通过代理分解进行层次化评估
与以前直接评估图像真实性或美学质量的方法不同,本工作设计了 PW-Agent,这是一个层次化、分步的分析框架,采用结构化、非线性且感知置信度的评分机制。PW-Agent 能够对 AI 生成图像的物理世界理解进行最终判断,该判断既具有高度区分性又非常可靠。PW-Agent 的整体流程如下图4 所示。
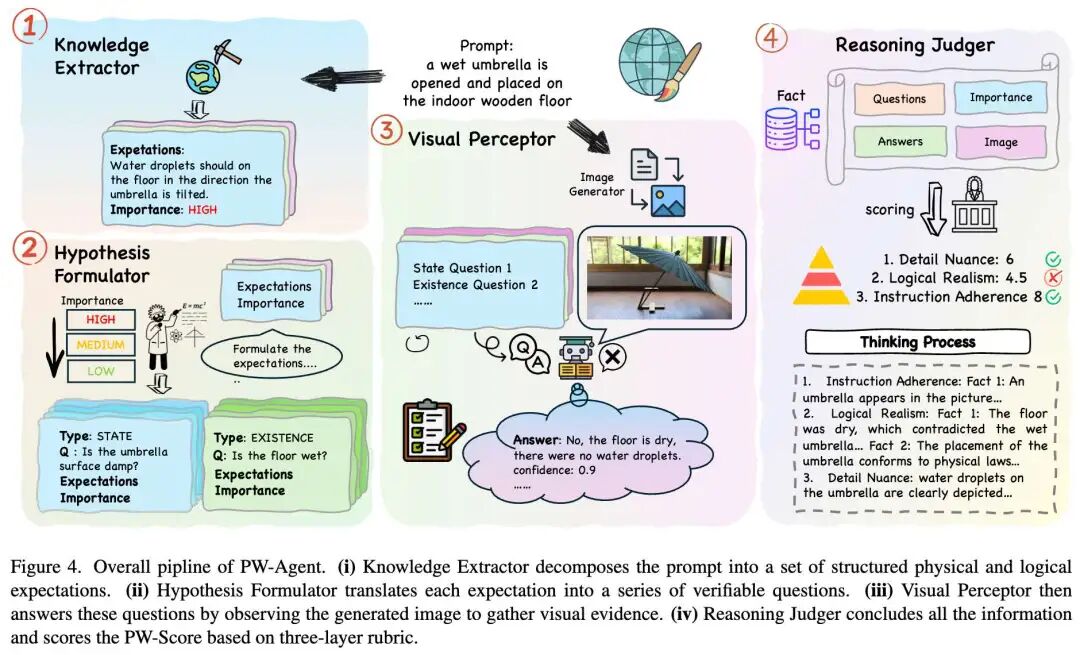
本工作通过一个包含四个模块的证据驱动管道来评估针对提示词 生成的图像 :世界知识提取器 (World Knowledge Extractor, WKE)、假设制定器 (Hypothesis Formulator, HF)、视觉感知器 (Visual Perceptor, VP) 和 推理评判器 (Reasoning Judger, RJ) 。这种设计是受到单次评判和粗略代理指标失败的启发,以及近期在问题驱动评估和以能力为中心的 T2I 基准测试(强调组合性、常识、物理和世界知识)方面取得的进展所驱动。
本工作在补充材料中提供了 PW-Agent 的伪代码。
世界知识提取器 (WKE)

假设制定器 (HF)

视觉感知器 (VP)

推理评判器 (RJ)
RJ 模块并不进行简单的平均,而是应用逻辑层次结构来计算最终得分。它通过三个层次聚合证据:


为了进一步利用 MLLM 强大的推理能力,还需要模型记录一个人类可读的思维过程,枚举满足/失败的期望、应用的惩罚/奖励以及上述公式中的中间值。
实验
实验设置
本工作选择了 17 个最先进的模型进行评估,涵盖三类架构:
-
基于扩散的模型:包括 FLUX.1-dev/schnell, Stable Diffusion (SD) 3.5 Large/Medium, SD 3 Medium, HiDream-l1-Full, Lumina-Image-2.0。
-
统一多模态模型:包括 Emu3, JanusPro-1B/7B, JanusFlow-1.3B, Show-o-512, Bagel (带/不带 Thinking)。
-
闭源模型:包括 DALL-E-3, Nano-Banana, SeedDream-4.0。 PW-Agent 使用 Qwen2.5-VL-72B 作为基础模型。
主要结果
如下表 1 所示:
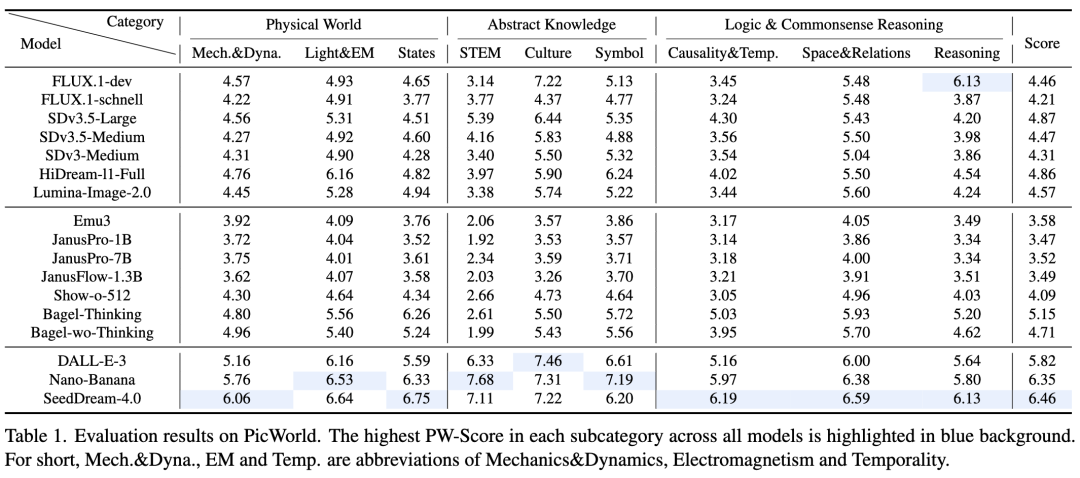
-
T2I 模型在隐性世界逻辑推理方面能力有限:几乎所有模型在 STEM 和“因果性与时间性”类别上的得分都持续较低。即使是表现最好的 SeedDream-4.0,在 Symbol 和 STEM 上的得分也相对较低。这表明模型擅长复制视觉外观(如阴影),但难以推断隐性后果(如热源附近的冰融化)。
-
闭源模型显著优于开源模型:闭源模型(如 SeedDream-4.0)与大多数公开模型之间存在明显的性能差距。这部分归因于闭源系统在推理管道中集成了复杂的预处理和提示词工程(利用 MLLM 重写提示词,将隐性挑战转化为显性指令)。
-
模型在基于知识的任务上表现优于基于推理的任务:模型在 Culture(文化)和 Symbol(符号)类别上的表现普遍优于 STEM 和“因果性与时间性”。这是因为训练数据通常包含丰富的显性名义知识,但缺乏学习隐性因果或时间关系所需的结构化信息。
-
开源统一多模态模型的表现明显低于领先的扩散模型:如 Emu3 和 JanusPro 系列等自回归模型在 PicWorld 基准测试中通常处于较低的性能层级。这可能表明在模型的通用性与高保真物理模拟的专业能力之间存在权衡。
PW-Agent 的评估 (验证 PW-Agent 的有效性):
-
与人类评估者的一致性:如下图 5 所示,通过人类研究(3位资深工程师,成对比较),PW-Agent 与人类偏好的一致率达到 **90.5%**,表明其能有效辨别图像质量和物理合理性的细微差别。
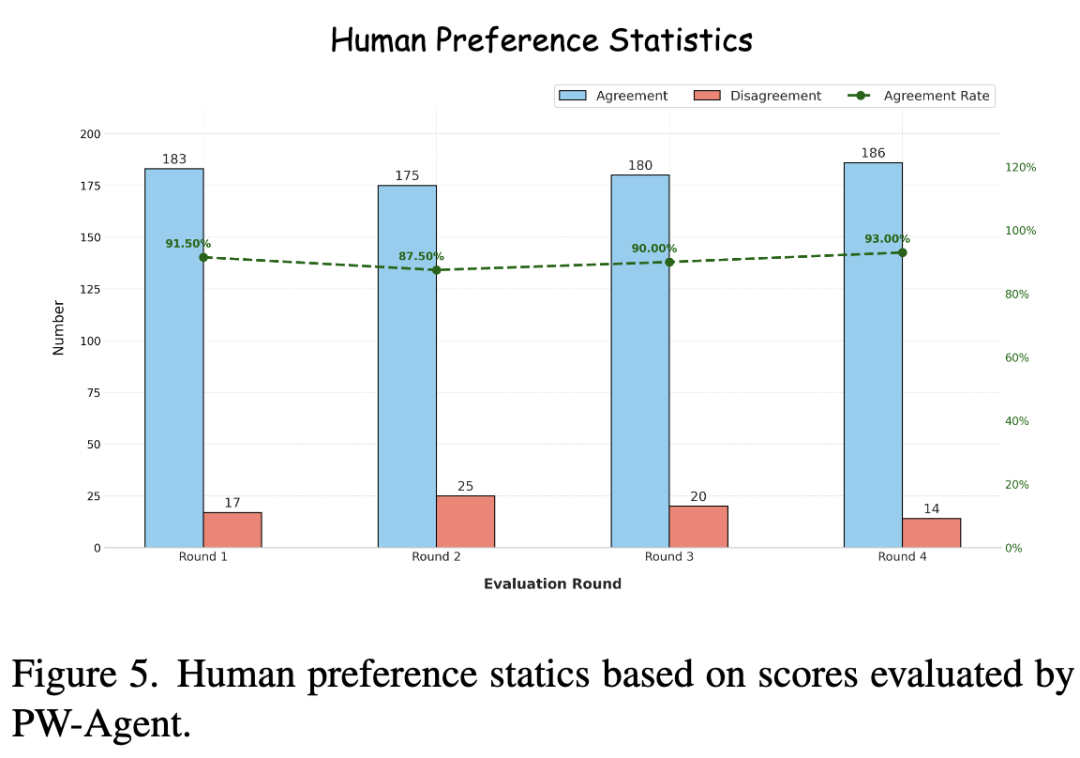
-
消融研究 (PW-Agent vs. 直接评判) :
-
将 PW-Agent 与使用 GPT-4o 进行零样本直接评分的基线进行比较。
-
人类评估者在 81.5% 的情况下倾向于 PW-Agent 的评分和推理(如下表 2 所示)。
-
如下图 6 所示,直接评判表现出强烈的集中趋势偏差(分数分布压缩),而 PW-Agent 利用了完整的评分范围,具有更高的方差和区分度。

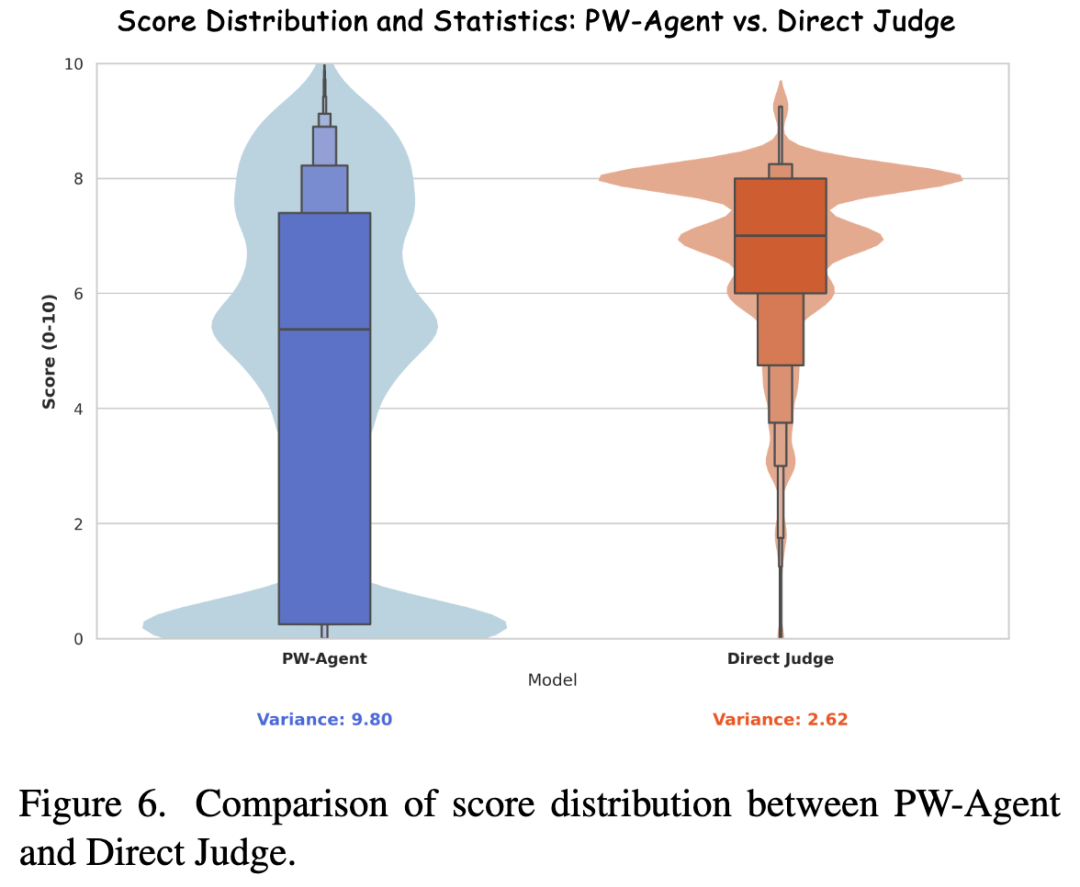
-
结论
PicWorld,这是一个以能力为中心的基准测试,直接测试 T2I 模型是否可以利用隐性世界知识并生成符合物理定律和因果逻辑的图像。PicWorld 将评估从粗略的“提示词-图像”相关性转变为经过验证的、针对每个事实的证据,揭示了模型在知识落地、多物理交互以及超出提示词显式说明的逻辑后果方面的行为。
本工作进一步提出了 PW-Agent,这是一个基于证据的评估器,它将提示词转化为可审计的检查项,并将像素级的发现聚合成透明的、分层的分数。这种方法既保留了基于查询的评估的可扩展性,又减少了单次(one-shot)评判的偏差和不可靠性。
在 PicWorld 上的实验表明,尽管具有强大的提示词依从能力,最先进的系统——尤其是开源模型——在物理真实感和因果推理方面仍然举步维艰。本工作希望 PicWorld 和 PW-Agent 的结合使用能为模型比较提供可操作的诊断,从而指导数据整理和推动方法的进一步发展。
参考文献
[1] Beyond Words and Pixels: A Benchmark for Implicit World Knowledge Reasoning in Generative Models
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。

















 973
973

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









