




 本文详细介绍了数据结构如数组、链表、索引和散列,以及并发控制机制如悲观锁和乐观锁。特别讨论了ArrayList、Vector、CopyOnWriteArrayList等List实现的特性,Set的HashSet、LinkedHashSet和TreeSet的区别。此外,还涵盖了HashMap、Hashtable和ConcurrentHashMap等Map实现,以及各种阻塞队列的内部工作原理和应用场景。最后,文章提及了volatile、CAS等并发原理解析。
本文详细介绍了数据结构如数组、链表、索引和散列,以及并发控制机制如悲观锁和乐观锁。特别讨论了ArrayList、Vector、CopyOnWriteArrayList等List实现的特性,Set的HashSet、LinkedHashSet和TreeSet的区别。此外,还涵盖了HashMap、Hashtable和ConcurrentHashMap等Map实现,以及各种阻塞队列的内部工作原理和应用场景。最后,文章提及了volatile、CAS等并发原理解析。
数据结构
一、数组
1、一段连续的内存空间
2、优点:随机访问,可以快速进行数据的查询
3、缺点:插入删除效率低,因为数组长度是固定的,所以在插入和删除的时候就需要对原来的数组进行复制操作,将数组原来的长度扩大或是变小。
二、链表
1、不连续的内存空间
2、优点:大小动态扩展,插入删除效率高
3、缺点:不能随机访问,在查找元素的时候需要对整个链表进行遍历才能查询到。
三、索引
如同,使用数组来存储对象的引用。
四、散列
如同,对对象用hash值来存储对象。
锁
一、悲观锁
不管怎样都是加锁
synchronized(对象锁)
1、是关键字
2、自动加锁,自动释放
ReentrantLock
1、是个对象
2、需要手动加锁,手动释放
二、乐观锁
当出现并发时才加锁?
cas + 自旋
cas(Compare And set) 比较然后设置
Unsafe类,操作系统提供的指令
List
一、ArrayList
扩容会,按照数组原来的大小的1.5倍进行扩容。
快速失败(fail-fast)机制
1、通过iterator()获取迭代器时,保存modCount(操作次数)快照,游标cursor初始化为0;
2、hasNext判断条件:cursor != size,如果有其他线程修改了集合长度(新增删除元素),会导致size变化,modCount和快照会有差;
3、next()取元素时,为防下标越界(取出错误数据),先判断modCount和快照是否相同,不同意味着size发生了改变。
总结:ArrayList 不支持线程安全,所以为了防止错误的操作而引入“快速失败”机制
拷贝
######## 浅拷贝
1、基本数据类型,拷贝就会在栈中新增一个数据,因为基础数据类型存放在栈中所以相互独立。
2、对象(数组)类型,拷贝就会在栈中新增引用,因为对象的数据存储在堆中,拷贝的只是引用,所以数据并不是相互独立。
3、String类型,拷贝就会在栈中新增一个引用,因为String类型的数据时存放在常量池中,而且String的数据是无法修改的,当String修改数据其实就是重新赋值,所以数据相互独立。
######## 深拷贝
就是将堆中的数据,也拷贝一份。
序列化
重写了序列化方法,因为存放元素的数组elementData里面有很多占位用的null,序列化时只需要按照size读写。
Arrays.asList
接收的是可变参数,基本类型不支持泛型化,会把整个数组当成一个元素放入新的数组,传入可变参数。
二、Vector
1、线程安全
2、就是在ArrayList基础上添加synchronized
三、CopyOnWriteArrayList
1、数据结构同ArrayList,数组array。
2、写时加锁复制:ReentrantLock保证线程安全,修改数组之前先将数组拷贝一份,操作新数组,并赋值给array,旧数组丢弃。
3、读操作无锁,读的是旧数组,不会阻塞读,读写分离
4、弱一致性:写操作会生成新的数组,读的数据可能已经被修改,迭代器也是弱一致性,读的是快照。
四、LinkedList
1、数据结构:链表,双向链表
2、实现Deque接口,支持首部和尾部存取元素
Set
集合中元素不可重复,可以作用在需要去重的集合中,因为Set.add方法中会判断是否存在相同元素
一、HashSet
1、底层使用HashMap存储数据,用map的key存储元素
- 元素不重复,key不能重复
- 元素是无序的,key是无序的
- 元素允许一个null值,key允许一个null
- 非线程安全,没有get()方法
2、虚拟对象PRESENT,存map时,value的固定为此值
二、LinkedHashSet
没有成员变量及api,全部使用LinkedHashMap替代
三、TreeSet
底层使用NavigableMap存储元素,实际上大部分情况就是TreeMap
四、CopyOnWriteArraySet
底层使用CopyOnWriteArrayList,添加了addIfAbsent方法保证元素的不可重复。
五、ConcurrentSkipListSet
底层使用ConcurrentSkipListMap
Map
一、HashMap


1、只允许存一个key为null的元素。
2、哈希冲突,通过hash值计算出来的下标值相同,用链表存储相同下标的元素。
3、HashMap中key值是唯一的,查找同一下标下的元素时就通过key来查找值。
4、当链表高度达到8,数组长度达到64,链表就转变为红黑树。
二、Hashtable
1、数据结构同HashMap(同jdk7,没有红黑树),操作也一致。
2、synchronized保证线程安全
三、ConcurrentHashMap
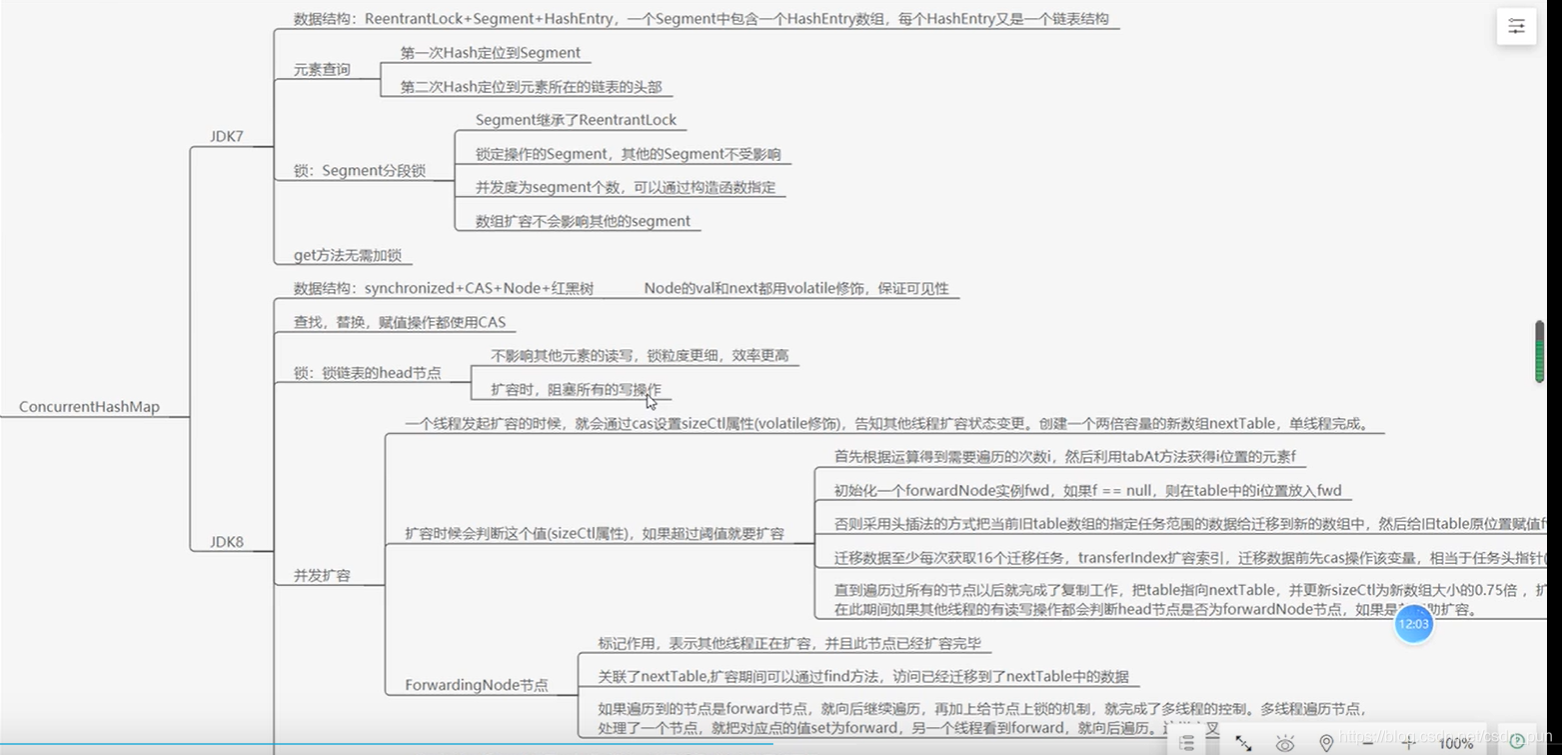

四、其他Map

阻塞队列BlockingQueue
一、数组阻塞队列ArrayBlockingQueue
1、静态数组,容量固定必须指定长度,没有元素的下标位置null占位。
2、锁:ReentrantLock 存取是同一个锁,操作同一个数组。
3、阻塞(在线程存取队列时阻塞)
- notEmpty 出队:队列count为0,无元素可取时,阻塞在该对象上。
- notFull 入队:队列count为数组的length,放不进元素时,阻塞在该对象上。
4、入队,从队首开始添加元素,记录putIndex(数组入队的索引,记录下一个需要入队的位置),到队尾时置为0。唤醒notEmpty(),继续进行出队操作。
5、出队,从队首开始取元素,记录takeIndex(数组出队的索引,记录下一个需要出队的位置),到队尾时置为0。唤醒notFull(),继续入队操作。
6、先进先出,读写互相排斥.
二、链表阻塞队列LinkedBlockingQueue(推荐)
1、链表Node,内存有多大空间,队列就能有多长。
2、锁分离,存取互相不排斥,因为操作的是不同的对象,takeLock(取Node的锁),putLock(存Node的锁)。
3、阻塞,与ArrayBlockingQueue相同。
4、入队:队尾入队,记录last节点。
5、出队:队首出队,记录head节点。
6、删除元素(不是出队),时两个锁要一起加。
7、先进先出。
三、链表阻塞双端队列LinkedBlockingDeque
1、数据结构:同LinkedBlockingQueue
2、锁:同ArrayBlockingQueue,因为能选择头尾进行出队入队,进可能会存取操作同一个元素,所以不能用两个锁。
3、阻塞:同ArrayBlockingQueue
4、入队:队首队尾都可
5、出队:队首队尾都可
四、同步队列SynchronousQueue
1、存取调用同一个方法:transfer
- put、offer为生产者,携带了数据e,为Data模式,设置到QNode属性中。
- take、poll为消费者,不携带数据,为Request模式,设置到QNode属性中。
2、数据结构:链表Node。
3、锁:cas+自旋。
4、阻塞: LockSupport。
5、判断队尾节点或者栈顶节点Node与入队模式是否相同。
- 相同则构造节点Node入队,并阻塞当前线程,元素e和线程赋值给Node属性。
- 不同则将元素e(不为null)返回给取数据线程,配对线程配唤醒,出队。
6、公平模式(队列),在实例化时设置,队尾匹配,队头出队,先进先出。
7、非公平模式(栈),在实例化时设置,栈顶匹配,栈顶出栈,后进先出。
五、延迟队列DelayQueue
1、数据结构:同PriorityQueue,与PriorityBlockingQueue类似,没有阻塞功能。
2、锁:ReentrantLock
3、阻塞: Condition available
4、入队:不阻塞,无界队列,与优先级队列入队相同,唤醒available
5、出队:
- 为空则阻塞available
- 检查堆顶元素过期时间
1、小于等于0,则取出
2、大于0,则阻塞,判断leader线程是否为空。
不为空,直接阻塞;为空将当前线程设置为leader,并按照过期时间进行阻塞。
六、LinkedTransferQueue
1、数据结构:链表
2、锁:cas+自旋
3、阻塞:LockSupport
4、入队:可以自己控制放元素是否需要阻塞线程,比如使用四个添加元素的方法就不会阻塞线程,只入队元素,使用transfer()会阻塞线程。
5、取元素与SynchronousQueue基本一样,都会阻塞等待有新的元素进入被匹配到。
七、优先级的阻塞队列PriorityBlockingQueue
1、数据结构:数组+平衡二叉树(第一个元素为null,为了方便查找父结点),可以指定初始容量,最大容量为Integer.MAX_VALUE。
2、锁:ReentrantLock存取时同一把锁
3、阻塞:notEmpty,出队,队列为空时阻塞
4、入队
- 不阻塞,永远返回成功,无界,除非内存不够
- 根据比较器进行堆化:根据二叉堆进行排序,自上而下。
5、出队
- 弹出堆顶元素
- 堆尾元素放到堆顶,堆化
- 自上而下堆化
- 为空则阻塞
其他重要知识点
volatile
cas
CAS机制: 解决并发问题
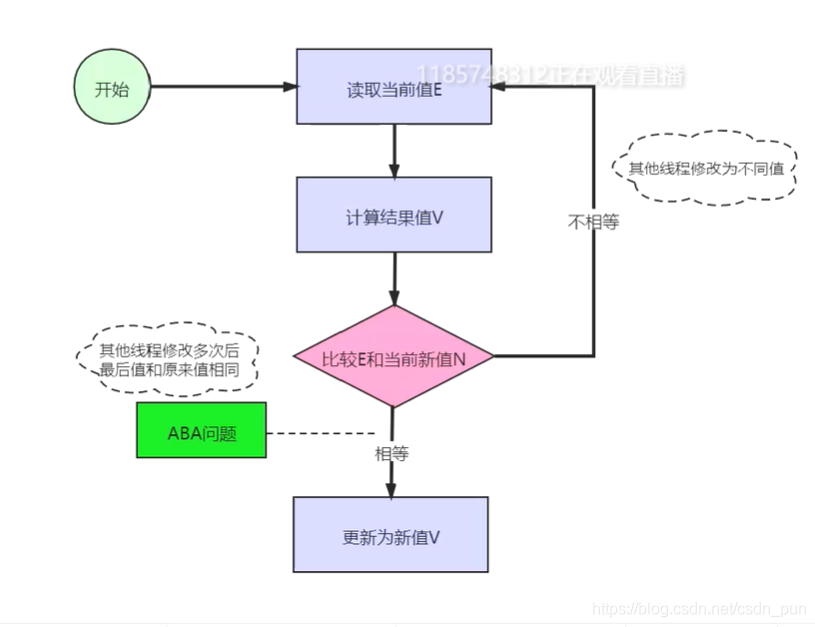
CAS的ABA问题:
问题描述
1、A线程操作途中为操作完
2、B线程操作进行 加与减 实际上内存中的数据没有改变
3、A线程因为,内存数值没有变化会继续执行
解决办法:为该值添加一个boolean来判断该值是否改变过?
自旋

















 3452
3452

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









