




 本文详细指导了MySQL 5.7.19的安装过程,包括环境配置、初始化、启动/停止服务及修改密码。深入讲解了数据库三层结构,SQL语句分类,从创建数据库、表到备份恢复,再到各种查询操作、索引和约束的使用。适合初学者快速上手。
本文详细指导了MySQL 5.7.19的安装过程,包括环境配置、初始化、启动/停止服务及修改密码。深入讲解了数据库三层结构,SQL语句分类,从创建数据库、表到备份恢复,再到各种查询操作、索引和约束的使用。适合初学者快速上手。
Mysql 安装与使用
学习内容来自B站韩顺平老师的Java基础课
Mysql 5.7.19 安装
- 将下载的压缩包进行解压
- 把安装目录下的 bin 文件夹的路径加入到环境变量(此电脑右键属性–>高级系统设置–>环境变量–>path)
- 在安装目录下添加配置文件 my.ini,内容为
[client]
port=3306
default-character-set=utf8
[mysqld]
# 设置为自己 MYSQL 的安装目录
basedir=D:\mysql\mysql-5.7.19-winx64\
# 设置为 MYSQL 的数据目录
datadir=D:\mysql\mysql-5.7.19-winx64\data\
port=3306
character_set_server=utf8
# 跳过安全检查,注释后需要输入正确的账户密码才能登录
skip-grant-tables
- 使用管理员模式打开命令行,进入到 bin 目录下,输入`mysqld -install
- 上一步可能失败,会报错:如果是服务已经存在的错误,需要将原来的卸载;如果是 .dll 之类的文件缺失,需要安装或者修复 VS C++ 2013 运行库,直接去官网下载即可
- 之后输入
mysqld --initialize-insecure --user=mysql进行数据库初始化
启动关闭服务
启动
net start mysql
停止
net stop mysql
修改密码
修改密码
1. mysql -u root -p # 连接mysql 的简洁指令
2. use mysql;
3. update user set authentication_string=password('XXX') where user='root' and Host='localhost';
4. flush privileges;
5. quit
6 停止服务再重启
连接 mysql 服务器的完整指令
mysql -h 主机IP -P 端口 -u 用户名 -p密码
注意:
- 密码和 -p 之间没有空格
- -p 后面没有密码,回车后需要输入密码
- 没有写 -h 主机,默认就是本机
- 没有写-P,默认就是 3306
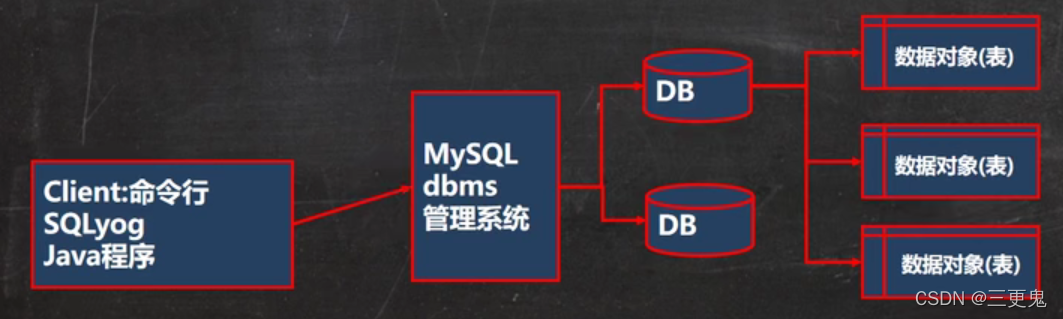
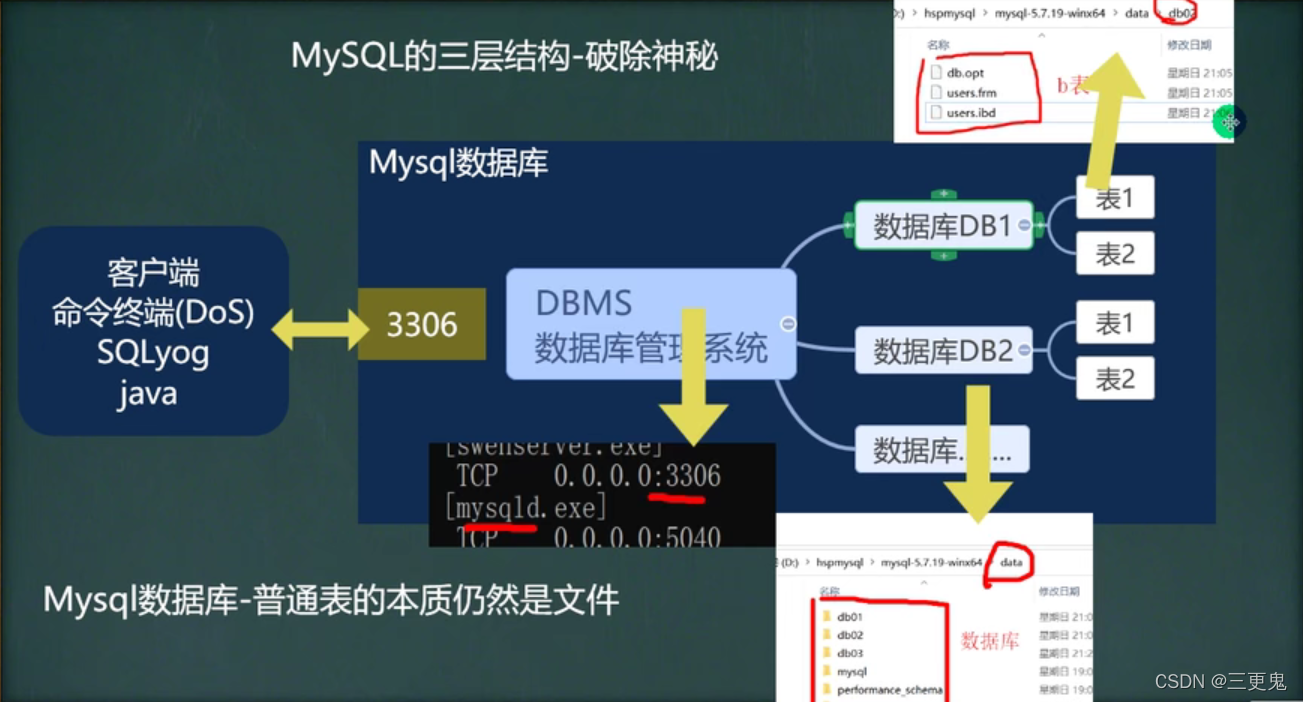
数据库三层结构
-
安装 Mysql 数据库,就是在主机安装一个数据库管理系统,这个管理程序可以管理多个数据库
-
一个数据库中可以创建多个表,用来保存数据
-
数据库管理系统、数据库和表的关系:
-
数据在数据库中的存储方式为表,一个表可以含有多条记录
SQL 语句分类
- DDL:数据定义,create
- DML:数据操作,增加、删除、修改
- DQL:数据查询,selet
- DCL:数据控制,管理数据库,比如用户权限 grant(授予) revoke(撤销)
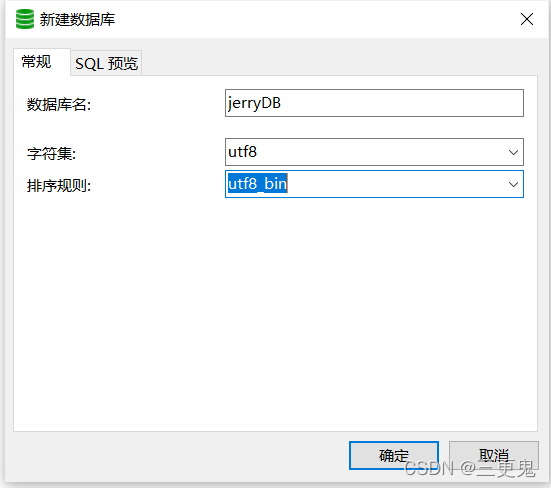
创建数据库
CREATE DATABASE [IF NOT EXISTS] db_name [create_specification[, create_specification]…]
上述语句表示创建名为 db_name 的数据库(如果不存在时才创建),create_specification 是参数,一般需要两个:
- CHARACTER SET: 指定数据库采用的字符集,如果不指定,默认为 utf8
- COLLATE: 指定数据库字符集的校对规则(常用的 utf8_bin [区分大小写],utf8_general_ci [不区分大小写],默认是 utf8_general_ci)
例子:
navicat
# 创建
CREATE DATABASE jerryDB;
# 删除
DROP DATABASE jerryDB
# 创建并指定字符集
CREATE DATABASEjerryDB_02 CHARACTER SET utf8
# 创建并指定字符集和校对规则
CREATE DATABASEjerryDB_03 CHARACTER SET utf8 COLLATE utf8_bin
关于校对规则和字符集:
- 创建表的时候也可以另外指定表的校对规则和字符集,如果不指定则按照数据库的校对规则和字符集
查看和删除数据库
显示数据库的语句:SHOW DATABASES
显示数据库创建时候的指令:SHOW CREATE DATABASE db_name
数据库删除语句:DROP DATABASE [IF EXISTS] db_name
注意,在创建数据库表的时候,为了规避关键字,可以将其进行转义:通过反引号 ` 包起来
备份和恢复数据库
备份
需要在命令行执行以下语句
mysqldump -u 用户名 -p -B 数据库1 数据库2 数据库n > 文件名.sql
上述指令表示把 数据库1 数据库2 数据库n 备份到文件 文件名.sql 中
例子:
把数据库 db01 备份到文件 bak.sql 中

备份后的文件就是 sql 语句组成的程序
恢复
进入 Mysql 命令行再执行
Source 文件名.sql

其实也可以直接使用原始方法:把备份文件的 sql语句复制执行
备份表
nysqldump -u 用户名 -p密码 数据库1 表1 表2 表n > 文件名.sql
该语句与之前的备份数据库的差别在于 -p 后不需要加 -B
表操作
创建表
CREATE TABLE table_name
(
field1 datatype,
field2 datatype,
field3 datatype
)character set 字符集 collate 校对规则 engine 存储引擎;
其中:
- field: 指定列名
- datatype:指定列(字段)类型
- character set: 字符集,默认为数据库的字符集
- collate: 校对规则,默认为数据库的校对规则
- engine:存储引擎
例子1:
CREATE TABLE `user` (
id INT,
`name` VARCHAR(255),
`password` VARCHAR(255),
`birthday` DATE)
CHARACTER SET utf8 COLLATE utf8_bin ENGINE INNODB;
例子2:
创建一个表结构和 tableA 相同的 tableB
create table tableB like tableA;
修改表
使用 ALTER TABLE 语句追加、删除、修改列,语法:
# 添加列 default expr 表示使用表达式 expr 表示的默认值
ALTER TABLE table_name
ADD (COLUMN datatype [defualt expr],
[, COLUMN datatype]... );
# 修改列
ALTER TABLE table_name
MODIFY (COLUMN datatype [defualt expr],
[, COLUMN datatype]... );
# 删除列
ALTER TABLE table_name
DROP (COLUMN);
例子:
# 在表格 emp 的 sex 列后加上一列 image ,类型为 varchar,最大长度60,默认值为 ''
ALTER TABLE `emp`
ADD image VARCHAR(60) NOT NULL DEFAULT '' AFTER `sex`;
# 修改表格 emp 的 job 列长度为 60
ALTER TABLE `emp`
MODIFY job VARCHAR(60);
# 删除 sex 列
ALTER TABLE `emp`
DROP sex;
# 显示表的描述信息,即所有列的所有类型信息
DESC employee;
# 重命名表
RENAME TABLE `emp` TO employee;
# 修改字符集
ALTER TABLE employee CHARACTER SET utf8;
# 修改 name 列为 user_name 并且设置默认值和长度
ALTER TABLE employee
CHANGE `name` `user_name` VARCHAR(64) NOT NULL DEFAULT '';
CRUD
- create
- read
- update
- delete
insert
用来向表中插入数据
insert into table_name [(column1 [, column2...])]
values (value1 [, value2...])
# value1 对应 column1,value2 对应 column2,以此类推
例子:
# 创建
CREATE TABLE `goods` (
id INT,
goods_name VARCHAR(64),
price DOUBLE
);
# 插入数据
INSERT INTO `goods` (id, goods_name, price)
VALUES(10, '手机支架', 20);
INSERT INTO `goods` (id, goods_name, price)
VALUES(20, '手机', 2000);
# 查看
SELECT * FROM goods;
注意:
- 插入数据的类型应当与列类型相同。不过 sql 语句含有自动转型的功能,比如一个字段类型为整形,如果给的是 ‘30’ 这种可以转为整形的字符串,那么也是可以的,但是 ‘ab’ 这种显然不行
- 数据长度应该在给定的范围内
- 字符和日期型数据应该保存在单引号中
- 如果列类型允许为空的话,可以插入 null
- 如果给所有字段(列)都添加数据,可以省略掉前面的字段(列)名称
- 可以通过
insert info table_name (列名...) values (), (), ()的形式添加多条记录
select
基本语法:
SELECT [DISTINCT] * | {column1, column2...} FROM tablename;
其中,
- [] 包起来的 distinct 是去重,可以不写
- column 指定列名
- * 表示所有列
例子:
从 student 表查询 name 和 score 列,并去重
SELECT DISTINCT `name`, score FROM student;
使用表达式对查询的列进行运算
SELECT -| {column1|expression, column2|expression...} FROM tablename;
在 select 中使用 as 语句
SELECT column_name as other_name FROM tablename;
例子:
查询并统计学生表的总分,并重命名为 total_score
SELECT `name`, (chinese + math + english) AS total_score FROM student;
where 中常用运算符
使用 select 查询时可以使用 where 语句限定查询的范围,常用的运算符如下
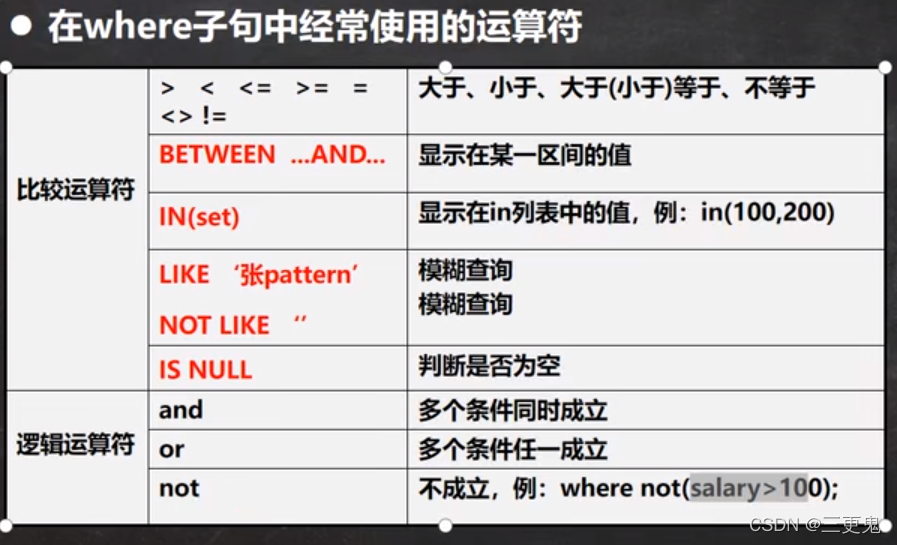
- where 语句主要起到过滤的作用
like 操作符
- % 表示 0 到多个任意字符
- _ 表示单个任意字符
比如where ename like __O%表示匹配 ename 第三个字符为 O 的记录
使用 order 语句对查询结果排序
语法:
SELECT column1, column2...
FROM tablename
order by column asc|desc;
- order by 指定排序的列,该列可以是表中原来的列名,也可以是指定的列名
- asc 是升序(默认),desc 是降序
- order by 应该位于 select 语句末尾
统计函数
count
返回行的总数,语法
SELECT count(*) | count(列名) FROM tablename [WHERE ...]
例子1:
统计表中的记录数
SELECT count(*) FROM tablename;
注意:
- count(*) 是统计满足条件的记录数
- count(列名) 是统计满足条件的某列有多少个,并且会排除 null
sum
返回满足条件的列的和,一般用在数值列
SELECT sum(列名) {, sum(列名)...} FROM tablename [WHERE ...]
例子:
统计表中所有学生的数学成绩和
SELECT sum(math) FROM student;
注意:
- sum 只能用在数值列
- 多列求 sum 需要间隔 ‘,’
avg
返回满足条件的一列的平均值
SELECT avg(列名) {, avg(列名)} FROM tablename [WHERE ...]
注意:
- avg 只能用在数值列
- 多列求 avg 需要间隔 ‘,’
max
返回满足条件的一列的最大值
SELECT max(列名) {, max(列名)} FROM tablename [WHERE ...]
min
返回满足条件的一列的最小值
SELECT min(列名) {, min(列名)} FROM tablename [WHERE ...]
group by
对查询到的列进行分组
SELECT column1, column2.. FROM tablename GROUP BY column;
然后可以使用 having 对分组结果进行过滤
SELECT column1, column2.. FROM tablename
GROUP BY column HAVING ...;
例子:
在一个员工表中查询平均工资(salary)低于 2000 的部门(dept)和它的平均工资
SELECT avg(salary), dept
FROM tablename GROUP BY dept
HAVING avg(salary) < 2000;
字符串相关函数
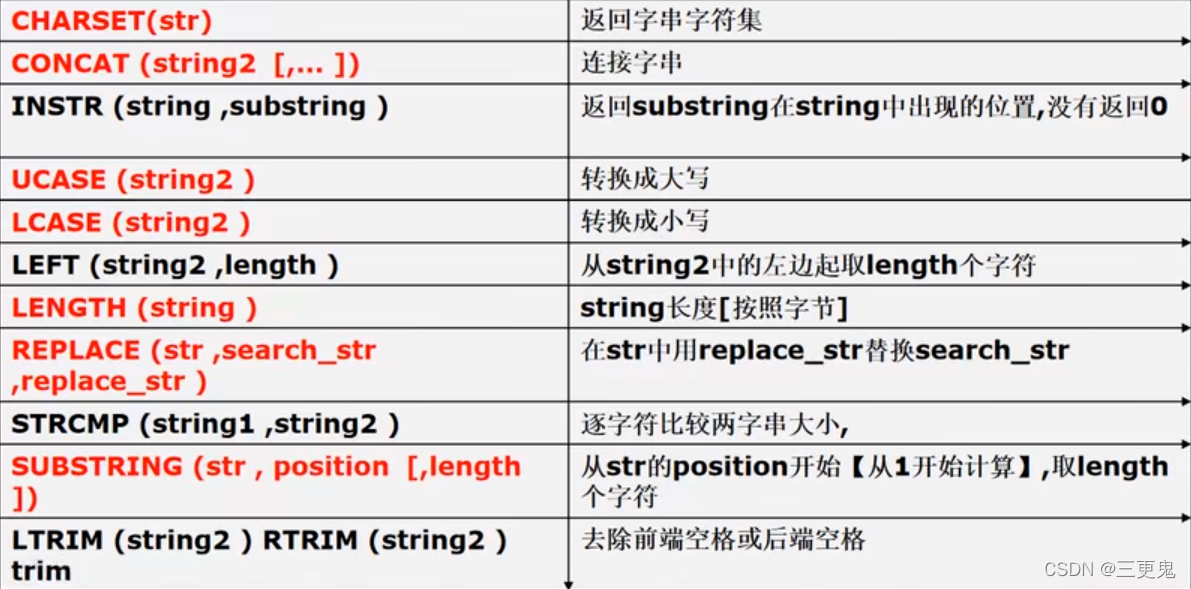
部分函数的解释:
- CHARSET(col),返回列对应的字符集
- CONCAT(STRING|COL [, …]), 将多个列拼接成一个列,如
SELECT CONCAT(ename, ' job is ', job) FROM table;,表示将姓名列和工作列拼接,并且在中间加上字符串 “ job is ”
数学相关函数
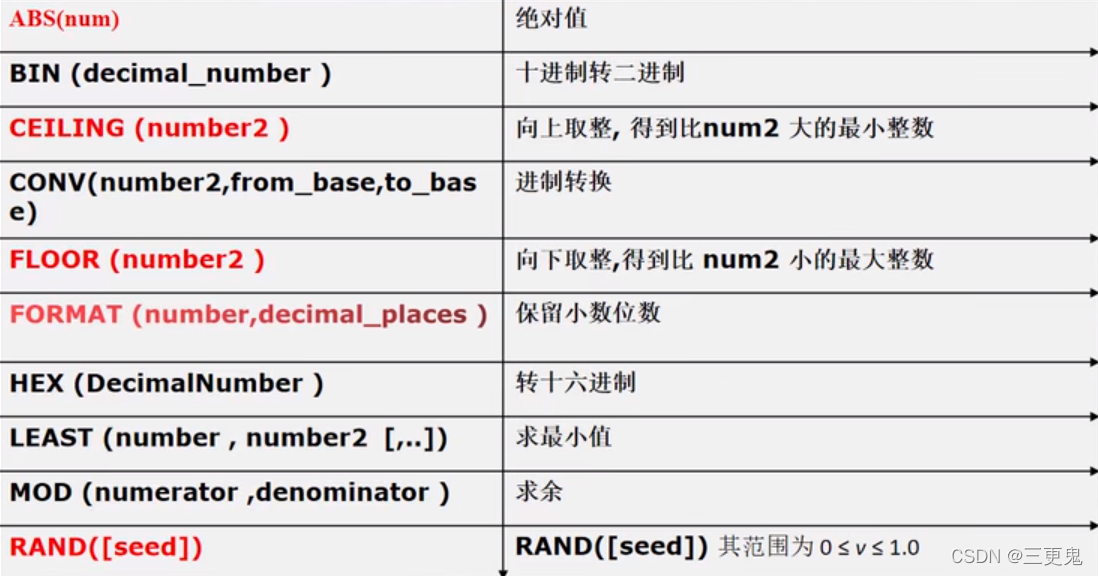
部分函数的解释:
- 使用 rand() 每次返回不同的随机数
- 使用 rand(seed) 返回随机数,如果 seed 不变,那么随机数也不变
日期相关函数
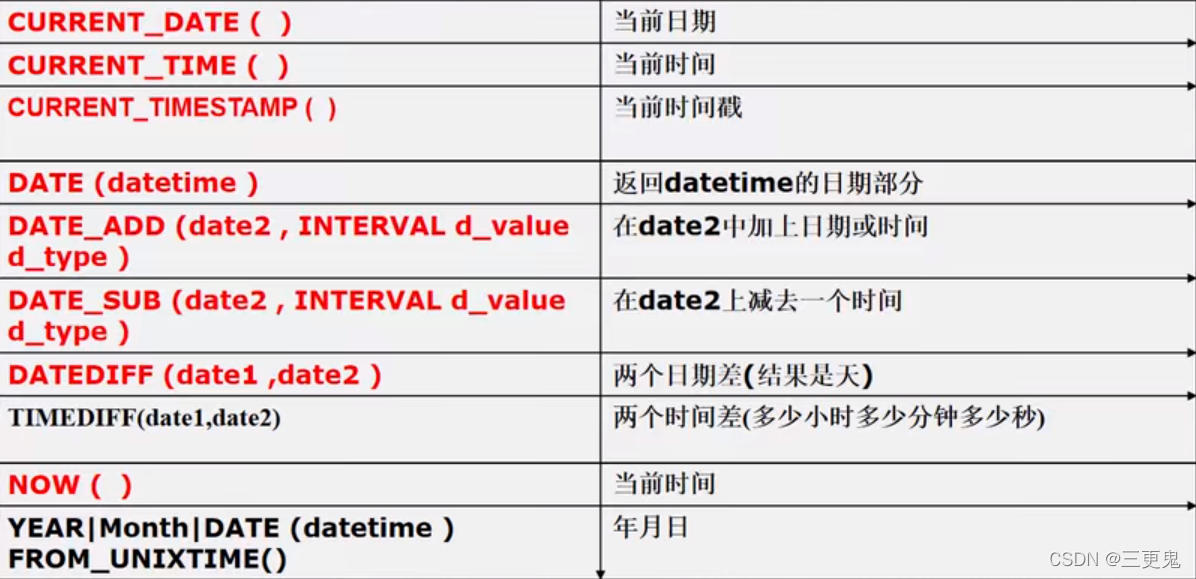
部分函数的解释:
- CURRENT_DATE() 只返回当前的日期,如 2021-12-21
- CURRENT_TIME() 只返回当前的时间,如 16:41:27
- CURRENT_TIMESTAMP() 返回日期加时间,如 2021-12-21 16:41:27。可以在添加记录的时候使用,记录下该条记录创建时间
- DATE_ADD(data2, INTERVAL d_value d_type),其中 d_value 是要加上的时间/日期的数量, d_type 是要加上的时间/日期的类型。比如加上十分钟就是 DATE_ADD(data2, INTERVAL 10 MINUTE)
- d_type 有 YEAR MONTH DAY HOUR MINUTE SECOND
- data2 的类型可以是 date、datetime、timestamp
- SELECT _UNIXTIME() FROM DUAL; 返回从 1970-01-01 到现在的秒数
- SELECT _UNIXTIME() FROM DUAL;
- FROM_UNIXTIME(秒数,格式) 可以把秒数转为对应的日期格式。如
SELECT FROM_UNIXTIME(1618483100, '%Y-%m-%d %H:%i:%s') FROM DUAL;返回对应 年-月-日 时:分:秒 的格式
其他日期函数:
- last_day(date):返回对应日期月份的最后一天
加密函数和系统函数
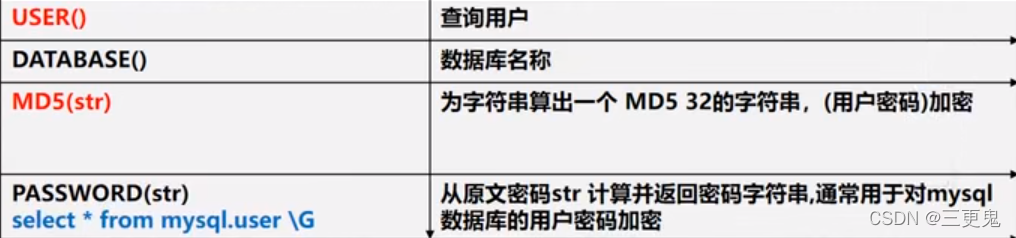
使用方式:
SELECT USER() FROM DUAL;
SELECT DATABASE() FROM DUAL;
SELECT md5('password') FROM DUAL;
-- 返回所有用户的信息,包括权限信息和加密过的密码,加密方式和 PASSWORD(str) 函数的相同
SELECT * FROM mysql.user;
流程控制函数
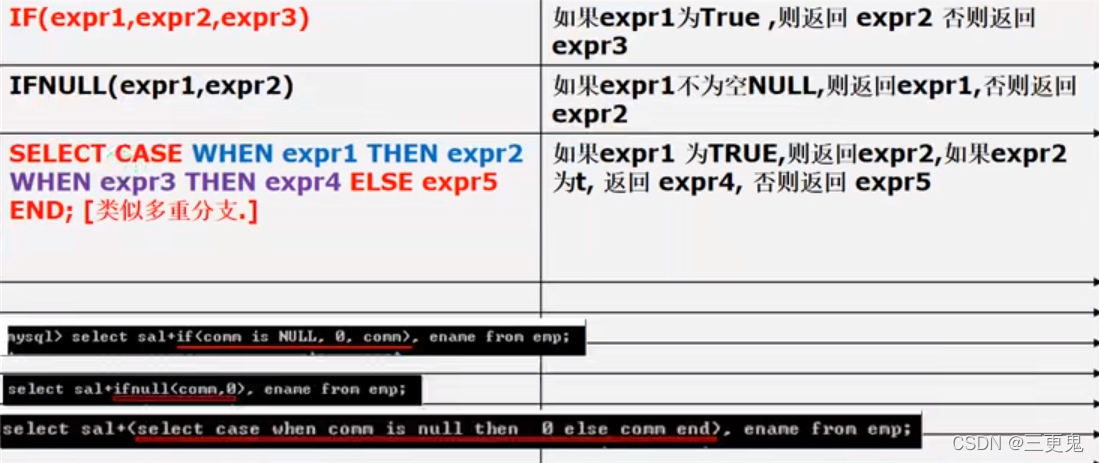
- IF(expr1, expr2, expr3) 类似三元运算符
- 判断为 null 可以使用 is null,判断非空可以用 is not null
分页查询
语法:
select ... limit start, rows
表示从 start + 1 行开始取,取 rows 行,start 从 0 开始算
多表查询
select ... from tableA, tableB;
- 若 tableA 中有 m 条记录,tableB 中有 n 条记录,那么会返回 m*n 条记录
- 一般需要加 where 进行过滤
自连接
可以简单理解为多表查询时,两张表名相同,即把一张表当两张表使用
- 使用时需要加别名 如
select * from tableA nameA, tableA nameB,其中 nameA,nameB 就是取的表别名
mysql 表子查询
子查询是指嵌入在其它 sql 语句中的 select 语句,也叫嵌套查询
- 单行子查询:只返回一行数据的子查询语句
- 多行子查询:返回多行数据的子查询语句
单行子查询
例子1:
假设有一张员工表 emp,表中有 name 列、dept(部门) 列等,要求查出 name 为 jerry 的部门所有成员
- 查到 jerry 所在 dept
- 返回所有与上一步 dept 相同的记录
select *
from emp
where dept = (
select dept
from emp
where name = 'jerry'
);
多行子查询
例子2:
假设有一张员工表 emp,表中有 dept 列、job 列,要求查出与 dept 为 10 的员工相同的 job 的所有记录,但是不包括 dept 为 10 的记录
- 查询到 dept 为 10 的所有 job
- 把上一步查询结果当作子查询使用
select *
from emp
where job in (
select distinct job
from emp
where dept = 10
) and dept <> 10;
子查询作临时表
子查询可作临时表使用
例子:
查询一个商品表 shop 中的各个类别 cat_id 中价格 price 最高的商品
- 查询出各个类别的最高价格和对应类别,然后将查询结果作子表
- 对子查询的临时表和原表做多表查询,使用 where 过滤
select *
from (
select cat_id, max(price) as max_price
from shop
group by cat_id
) temp, shop
where temp.cat_id = shop.cat_id
and temp.max_price = shop.price;
all
例子:
要求返回工资比所有部门 30 的员工工资高的记录
select *
from emp
where salary > all(
select salary
from emp
where dept = 30
);
也可以这样写
select *
from emp
where salary > (
select max(salary)
from emp
where dept = 30
);
any
例子:
要求返回工资比其中一个部门 30 的员工工资高的记录
select *
from emp
where salary > any(
select salary
from emp
where dept = 30
);
也可以这样写
select *
from emp
where salary > (
select min(salary)
from emp
where dept = 30
);
多列子查询
查询返回多个列数据的子查询
例子:
查询与 jerry 的部门和岗位完全相同的所有员工,不含 jerry 本人的记录
- 查询 jerry 的部门和岗位
- 把上一步的查询当作子查询,使用多列子查询的语法进行匹配
例子:
要求返回所有工资比部门 30 的员工工资高的记录
select *
from emp
where (dept, job) = (
select dept, job
from emp
where name = 'jerry'
) and name != 'jerry';
表复制和去重
表复制
自我复制数据(蠕虫复制)
insert into tablename
select * from tablenamne;
表去重
- 先创建一个和待去重的表 tableA 结构相同的临时表 temp
- 把 tableA 的记录通过 distinct 处理后复制到 temp 中
- 清空 tableA
- 把 temp 的记录复制到 tableA
- 删除 temp
create temp like tableA;
insert into temp
select distinct * from tableA;
delete from tableA;
insert into tableA;
select * from temp;
drop table temp;
合并查询
可以通过集合操作符号合并多个 select 语句的查询结果
union all
合并两个查询结果,不去重
select * from emp
union all
select * from emp;
union
合并并去重
select * from emp
union
select * from emp;
外连接
- 左外连接:左侧的表记录完全显示
- 右外连接:右侧的表记录完全显示
例子1:

使用左外连接,显示所有人成绩,如果没有成绩,也要显示这个人的姓名和 id
select `name`, stu.id, grade
from stu left join exam
on stu.id = exam.id;
例子2:
使用右外连接,显示所有人成绩,如果没有对应的学生,也要显示成绩
select `name`, stu.id, grade
from stu right join exam
on stu.id = exam.id;
mysql 约束
约束用来确保数据库的数据满足特定的规则:
- not null:定义该约束后,该列不可以为空
- unique:定义该约束后,该列不可以重复
- primary key:表示主键
- foreign key:表示外键
- check:强制要求数据必须满足的条件。注:mysql 5.7 还不支持 check,只会语法校验,但不生效
primary key
注意事项
- 用来唯一表示一行数据,定义主键约束后,该列不可重复
- 一张表只能有一个主键,但可以是复合主键(多列拼接)
- 主键不能重复,也不能为空
- 使用 desc 表名,可以看到 primary key 的信息
主键的定义方式有两种:
- 直接在字段名后指定:字段名, primary key
- 在表定义最后写 primary key(列名)
例子·:
id 为主键
create table tableA (
id int primary key,
`name` varchar(32),
);
id 和 name 为复合主键
create table tableA (
id int,
`name` varchar(32),
email varchar(32)
primary key (id, `name`) -- 复合主键
);
unique
使用细节
- 如果 unique 约束的列没有加 not null 约束,则 unique 字段可以有多个 null
foreign key
外键用于定义主表(外键指向的表)和从表(定义外键约束的表)之间的关系
外键约束要定义在从表上,主表对应的列则必须为主键或者有 unique 约束
语法:
foreign key (本表字段名) references
主表名(主键名或者 unique 字段名)
使用细节
- 定义外键约束后,外键列数据必须在主表的主键列存在或者为 null
- 表的存储引擎类型必须是 innodb 才支持外键
- 外键字段类型和主键字段类型需要一致(长度可以不同)
- 一旦建立主外键联系,就不能随意删除数据
例子:
创建表 stu ,外键为 class_id,指向 class 表的主键 id
create table stu (
`name` varchar(32),
class_id int,
foreign key (class_id) references class(id)
);
自增长
在某张表中,存在一个 id 列, 如果想要在添加数据的时候该列从 1 开始自动增长,如何处理?
这就需要用到自增长了
语法:
字段名 整数类型 primary key auto_increment
注意事项:
- 在插入数据时,自增长列数据需要为 null
- 一般来说自增长是配合 primary key 使用
- 自增长也可以配合 unique 使用
- 自增长修饰的列类型需要为整型
- 自增长默认从 1 开始,也可以通过
alter table 表名 auto_increment = xxx修改 - 如果添加数据时给自增长列指定了值,会以指定值为准。而且该列之后的值会从该给定值开始增长
mysql 索引
用来提高数据库性能
语法
create index 索引名 on 表名(索引列);
创建索引后,会加快查询速度(只对加索引的列加速),也会增加存储容量
索引的原理
在添加索引之前,查询是顺序查询。添加索引就像加了一个可以快速查询的数据结构,如 B+树
因而,添加索引虽然增加了查询效率,但是:
- 会增加数据表的磁盘占用
- 也会影响到更新、删除、插入的效率
索引类型
- 主键索引,主键自动为主索引,即主键不需要特地添加索引
- 唯一索引,即 unique 约束也自动为索引
- 普通索引,普通列添加为索引
- 全文索引,mysql自带的有带式效率较低,开发中一般使用 Solr 和 ElasticSearch
索引使用
- 添加索引
create [unique] index index_name on table_name (col_name[()length] [asc|desc], ...)
- 添加主键
alter table table_name add primary key (col_name...)
- 删除索引
drop index index_name on table_name
- 删除主键索引
alter table table_name drop primary key
- ss1
可以查看表索引的方法
show indexes from table_name;
show index from table_name;
show keys from table_name;
desc table_name; -- 这种方式仅仅显示哪个列为索引
例子1:
添加普通索引
-- 1
create index id_index on table_name (id);
-- 2
alter table table_name add index id_index (id);
例子2:
添加主键索引
-- 1 创建表时加主键约束
create table tableA (
id int primary key,
`name` varchar(30)
);
-- 2
alter table tableA add primary key (id);
使用索引的细节
- 频繁被查询的列
- 唯一性太差的字段不适合建立索引,哪怕会被频繁查询。比如性别
- 更新频繁的字段不适合创建索引
- 不会出现在 where 语句的列不需要建立索引


















 866
866

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











