



 本文详细介绍如何搭建和使用ELK Stack(Elasticsearch、Logstash、Kibana),实现日志数据的实时收集、存储与可视化分析。涵盖环境配置、各组件启动步骤及Logstash与SQL Server数据库的连接配置。
本文详细介绍如何搭建和使用ELK Stack(Elasticsearch、Logstash、Kibana),实现日志数据的实时收集、存储与可视化分析。涵盖环境配置、各组件启动步骤及Logstash与SQL Server数据库的连接配置。
@elasticSearch、logstash、Kibana
全文搜索三大件
elasticEearch:分布式式搜索引擎
logstash:是一个具有实时管道功能的开源数据收集引擎,负责从第三方数据源爬取数据
kibana:是为 Elasticsearch设计的开源分析和可视化平台
注:三大件下载版本要一致,官网上统一提供下载(但是卡卡)
环境要求
1.三大件是有java环境开发出来的,需要安装jdk、配置环境变量
elasticSearch启动
启动elasticSearch 进入elasticsearch-7.0.0\bin目录,双击”elasticsearch.bat“,如图
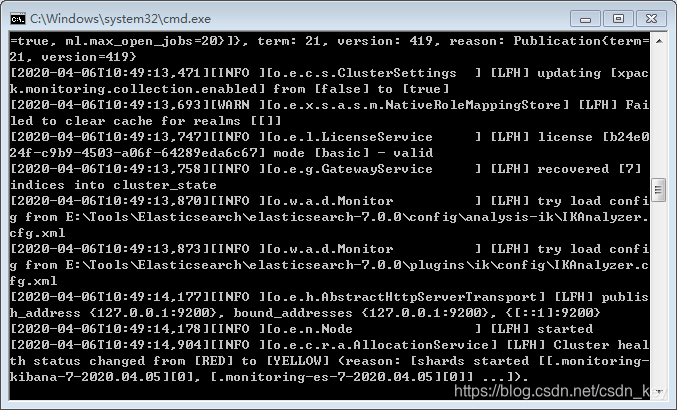
在浏览器中输入localhost:9200

elasticSearch启动成功
Kibana启动
启动kibana 进入kibana-7.0.0-windows-x86_64\bin目录,双击”kibana.bat“,如图
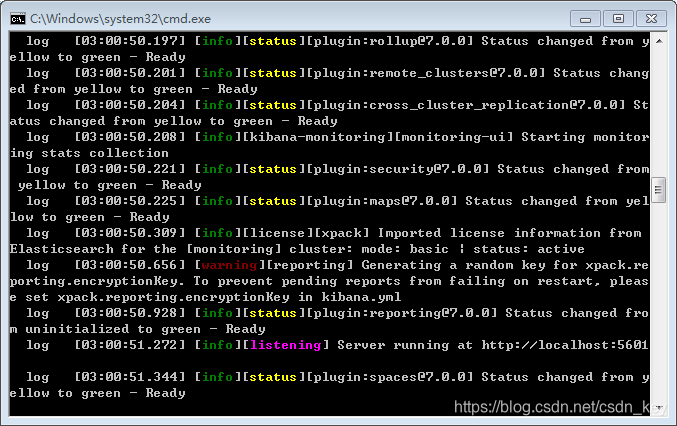
在浏览器中输入localhost:5601
kibana启动成功
logstash启动
采集数据需要连接第三方数据库,需要配置数据库驱动器;这里用jdbc连接sqlserver
1.进入logstash-7.0.0\config创建一个sql.conf
input {
jdbc {
# 数据库驱动器
jdbc_driver_class => "com.microsoft.sqlserver.jdbc.SQLServerDriver"
# 连接字符串
jdbc_connection_string => "jdbc:sqlserver://localhost:1433;databaseName=elasticSearch;"
jdbc_user => "sa"
jdbc_password => "*****"
# 数据库重连尝试次数
# connection_retry_attempts => "3"
# 判断数据库连接是否可用,默认false不开启
# jdbc_validate_connection => "true"
# 数据库连接可用校验超时时间,默认3600s
# jdbc_validation_timeout => "3600"
# 开启分页查询(默认false不开启)
# jdbc_paging_enabled => "true"
# 单次分页查询条数(默认100000,若字段较多且更新频率较高,建议调低此值)
# jdbc_page_size => "500"
# 同步频率(分 时 天 月 年),默认每分钟同步一次
schedule => "* * * * *"
# sql_last_value为内置的变量,存放上次查询结果中最后一条数据tracking_column的值,此处即为rowid
statement => "SELECT * FROM [elasticSearch].[dbo].[User] where CreateTime > :sql_last_value ORDER BY CreateTime"
# 是否将字段名转换为小写,默认true(如果有数据序列化、反序列化需求,建议改为false);
lowercase_column_names => false
# 是否记录上次执行结果,true表示会将上次执行结果的tracking_column字段的值保存到last_run_metadata_path指定的文件中
# record_last_run => true
# 需要记录查询结果某字段的值时,此字段为true,否则默认tracking_column为timestamp的值
use_column_value => true
# 查询结果某字段的数据类型,仅包括numeric和timestamp,默认为numeric
tracking_column_type => "timestamp"
# 需要记录的字段,用于增量同步,需是数据库字段
tracking_column => "CreateTime"
type => "user"
}
}
output {
if [type] == "user"
{
elasticsearch {
hosts => ["127.0.0.1:9200"]
index => "user"
document_id => "%{ID}"
document_id => "%{ID}"
#document_type => "doc"
}
file {
path => "C:\output.txt"
}
}
}
2.进入logstash-7.0.0\bin;shift+右键”在此处打开命令窗口“
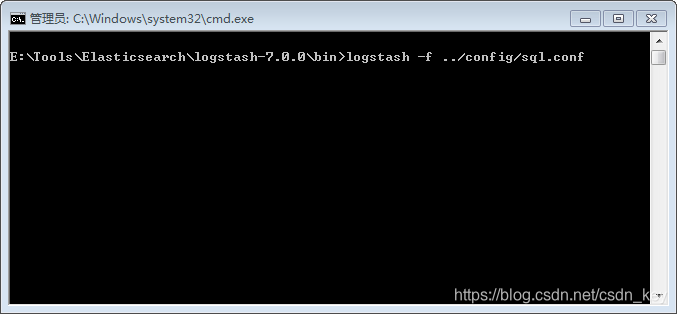
如图
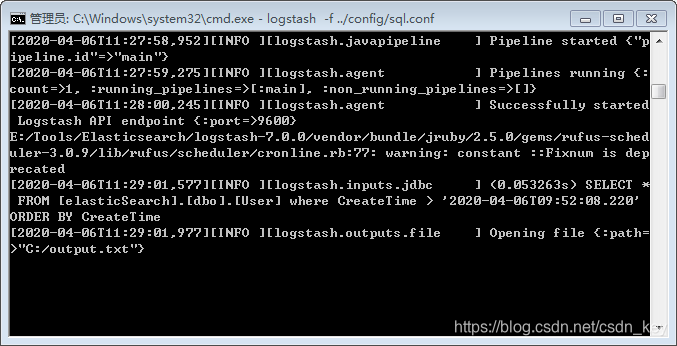
执行sql语句、并且把数据输出到output.txt文件中
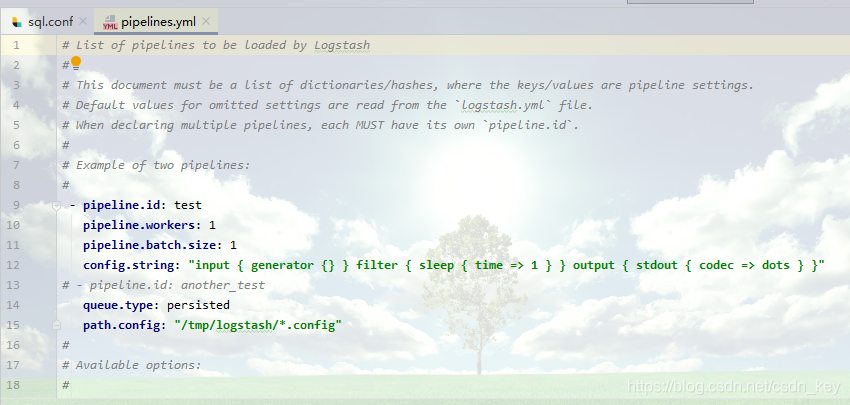
注意:logstash-7.0.0\config目录下pipelines.yml文件注释去掉

















 866
866

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









