




 本文深入剖析了HashSet的源码,揭示了其底层基于HashMap实现的细节。通过示例代码展示了HashSet添加元素的过程,包括HashMap的初始化、扩容、哈希计算以及链表和红黑树的转换。分析了不同情况下元素的插入逻辑,特别是重复元素的处理。此外,还讨论了HashMap的扩容策略和树化条件。
本文深入剖析了HashSet的源码,揭示了其底层基于HashMap实现的细节。通过示例代码展示了HashSet添加元素的过程,包括HashMap的初始化、扩容、哈希计算以及链表和红黑树的转换。分析了不同情况下元素的插入逻辑,特别是重复元素的处理。此外,还讨论了HashMap的扩容策略和树化条件。
HashSet源码剖析记录
结论:HashSet的底层是HashMap,而HashMap的底层是数组+链表+红黑树
例子:
public static void main(String[] args) {
HashSet testMap = new HashSet<>();
testMap.add("java");
testMap.add("oc");
testMap.add("java");
System.out.println("testMap = "+testMap);
}
一段平平无奇的代码,揭露了怎样的人性设计。。。
源码1:
/*
* Copyright (c) 1997, 2017, Oracle and/or its affiliates. All rights reserved.
* ORACLE PROPRIETARY/CONFIDENTIAL. Use is subject to license terms.
*/
package java.util;
import java.io.InvalidObjectException;
import sun.misc.SharedSecrets;
public class HashSet<E>
extends AbstractSet<E>
implements Set<E>, Cloneable, java.io.Serializable
{
static final long serialVersionUID = -5024744406713321676L;
private transient HashMap<E,Object> map;
// Dummy value to associate with an Object in the backing Map
private static final Object PRESENT = new Object();
/**
* Constructs a new, empty set; the backing <tt>HashMap</tt> instance has
* default initial capacity (16) and load factor (0.75).
*/
public HashSet() {
map = new HashMap<>();
}
/**
* Constructs a new set containing the elements in the specified
* collection. The <tt>HashMap</tt> is created with default load factor
* (0.75) and an initial capacity sufficient to contain the elements in
* the specified collection.
*
* @param c the collection whose elements are to be placed into this set
* @throws NullPointerException if the specified collection is null
*/
public HashSet(Collection<? extends E> c) {
map = new HashMap<>(Math.max((int) (c.size()/.75f) + 1, 16));
addAll(c);
}
/**
* Constructs a new, empty set; the backing <tt>HashMap</tt> instance has
* the specified initial capacity and the specified load factor.
*
* @param initialCapacity the initial capacity of the hash map
* @param loadFactor the load factor of the hash map
* @throws IllegalArgumentException if the initial capacity is less
* than zero, or if the load factor is nonpositive
*/
public HashSet(int initialCapacity, float loadFactor) {
map = new HashMap<>(initialCapacity, loadFactor);
}
/**
* Constructs a new, empty set; the backing <tt>HashMap</tt> instance has
* the specified initial capacity and default load factor (0.75).
*
* @param initialCapacity the initial capacity of the hash table
* @throws IllegalArgumentException if the initial capacity is less
* than zero
*/
public HashSet(int initialCapacity) {
map = new HashMap<>(initialCapacity);
}
/**
* Constructs a new, empty linked hash set. (This package private
* constructor is only used by LinkedHashSet.) The backing
* HashMap instance is a LinkedHashMap with the specified initial
* capacity and the specified load factor.
*
* @param initialCapacity the initial capacity of the hash map
* @param loadFactor the load factor of the hash map
* @param dummy ignored (distinguishes this
* constructor from other int, float constructor.)
* @throws IllegalArgumentException if the initial capacity is less
* than zero, or if the load factor is nonpositive
*/
HashSet(int initialCapacity, float loadFactor, boolean dummy) {
map = new LinkedHashMap<>(initialCapacity, loadFactor);
}
/**
* Returns an iterator over the elements in this set. The elements
* are returned in no particular order.
*
* @return an Iterator over the elements in this set
* @see ConcurrentModificationException
*/
public Iterator<E> iterator() {
return map.keySet().iterator();
}
/**
* Returns the number of elements in this set (its cardinality).
*
* @return the number of elements in this set (its cardinality)
*/
public int size() {
return map.size();
}
/**
* Returns <tt>true</tt> if this set contains no elements.
*
* @return <tt>true</tt> if this set contains no elements
*/
public boolean isEmpty() {
return map.isEmpty();
}
/**
* Returns <tt>true</tt> if this set contains the specified element.
* More formally, returns <tt>true</tt> if and only if this set
* contains an element <tt>e</tt> such that
* <tt>(o==null ? e==null : o.equals(e))</tt>.
*
* @param o element whose presence in this set is to be tested
* @return <tt>true</tt> if this set contains the specified element
*/
public boolean contains(Object o) {
return map.containsKey(o);
}
/**
* Adds the specified element to this set if it is not already present.
* More formally, adds the specified element <tt>e</tt> to this set if
* this set contains no element <tt>e2</tt> such that
* <tt>(e==null ? e2==null : e.equals(e2))</tt>.
* If this set already contains the element, the call leaves the set
* unchanged and returns <tt>false</tt>.
*
* @param e element to be added to this set
* @return <tt>true</tt> if this set did not already contain the specified
* element
*/
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
/**
* Removes the specified element from this set if it is present.
* More formally, removes an element <tt>e</tt> such that
* <tt>(o==null ? e==null : o.equals(e))</tt>,
* if this set contains such an element. Returns <tt>true</tt> if
* this set contained the element (or equivalently, if this set
* changed as a result of the call). (This set will not contain the
* element once the call returns.)
*
* @param o object to be removed from this set, if present
* @return <tt>true</tt> if the set contained the specified element
*/
public boolean remove(Object o) {
return map.remove(o)==PRESENT;
}
/**
* Removes all of the elements from this set.
* The set will be empty after this call returns.
*/
public void clear() {
map.clear();
}
/**
* Returns a shallow copy of this <tt>HashSet</tt> instance: the elements
* themselves are not cloned.
*
* @return a shallow copy of this set
*/
@SuppressWarnings("unchecked")
public Object clone() {
try {
HashSet<E> newSet = (HashSet<E>) super.clone();
newSet.map = (HashMap<E, Object>) map.clone();
return newSet;
} catch (CloneNotSupportedException e) {
throw new InternalError(e);
}
}
/**
* Save the state of this <tt>HashSet</tt> instance to a stream (that is,
* serialize it).
*
* @serialData The capacity of the backing <tt>HashMap</tt> instance
* (int), and its load factor (float) are emitted, followed by
* the size of the set (the number of elements it contains)
* (int), followed by all of its elements (each an Object) in
* no particular order.
*/
private void writeObject(java.io.ObjectOutputStream s)
throws java.io.IOException {
// Write out any hidden serialization magic
s.defaultWriteObject();
// Write out HashMap capacity and load factor
s.writeInt(map.capacity());
s.writeFloat(map.loadFactor());
// Write out size
s.writeInt(map.size());
// Write out all elements in the proper order.
for (E e : map.keySet())
s.writeObject(e);
}
/**
* Reconstitute the <tt>HashSet</tt> instance from a stream (that is,
* deserialize it).
*/
private void readObject(java.io.ObjectInputStream s)
throws java.io.IOException, ClassNotFoundException {
// Read in any hidden serialization magic
s.defaultReadObject();
// Read capacity and verify non-negative.
int capacity = s.readInt();
if (capacity < 0) {
throw new InvalidObjectException("Illegal capacity: " +
capacity);
}
// Read load factor and verify positive and non NaN.
float loadFactor = s.readFloat();
if (loadFactor <= 0 || Float.isNaN(loadFactor)) {
throw new InvalidObjectException("Illegal load factor: " +
loadFactor);
}
// Read size and verify non-negative.
int size = s.readInt();
if (size < 0) {
throw new InvalidObjectException("Illegal size: " +
size);
}
// Set the capacity according to the size and load factor ensuring that
// the HashMap is at least 25% full but clamping to maximum capacity.
capacity = (int) Math.min(size * Math.min(1 / loadFactor, 4.0f),
HashMap.MAXIMUM_CAPACITY);
// Constructing the backing map will lazily create an array when the first element is
// added, so check it before construction. Call HashMap.tableSizeFor to compute the
// actual allocation size. Check Map.Entry[].class since it's the nearest public type to
// what is actually created.
SharedSecrets.getJavaOISAccess()
.checkArray(s, Map.Entry[].class, HashMap.tableSizeFor(capacity));
// Create backing HashMap
map = (((HashSet<?>)this) instanceof LinkedHashSet ?
new LinkedHashMap<E,Object>(capacity, loadFactor) :
new HashMap<E,Object>(capacity, loadFactor));
// Read in all elements in the proper order.
for (int i=0; i<size; i++) {
@SuppressWarnings("unchecked")
E e = (E) s.readObject();
map.put(e, PRESENT);
}
}
/**
* Creates a <em><a href="Spliterator.html#binding">late-binding</a></em>
* and <em>fail-fast</em> {@link Spliterator} over the elements in this
* set.
*
* <p>The {@code Spliterator} reports {@link Spliterator#SIZED} and
* {@link Spliterator#DISTINCT}. Overriding implementations should document
* the reporting of additional characteristic values.
*
* @return a {@code Spliterator} over the elements in this set
* @since 1.8
*/
public Spliterator<E> spliterator() {
return new HashMap.KeySpliterator<E,Object>(map, 0, -1, 0, 0);
}
}
看HashSet,其实是继承了AbstractSet,实现了Set接口的一个类,在调用 new HashSet的时候,就是new了一个HashMap,此时HashMap是空的
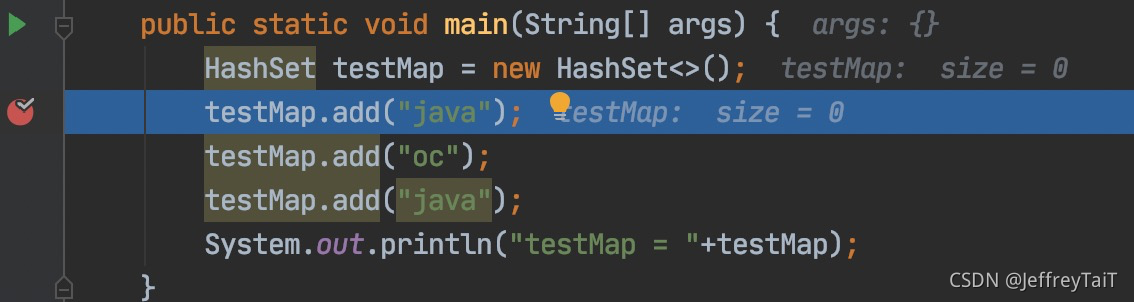
add(“java”)阶段:
Set里的add方法:
源码2:
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
其实就是传入参数E(java)到刚刚创建的map中,其中的PRESENT(private static final Object PRESENT = new Object())是一个全局静态对象,看官方注解是映射中与对象关联的虚拟值,可以理解为一个常量,在put进map时作为value传入,防止高并发场景下,引起循环链表。
1. Set中的put方法:
源码3:
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
1.1 Map中put的调用方法,其中对key进行hash计算:
源码4:
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
如果key不为null,把key的地址赋值到h中,并与该地址无符号右移十六位后进行异或运算,并返回值。其中hashCode为native方法,每个Object都具有的。
1.1.1 putVal方法,也是最终实现存放逻辑的方法:
源码5:
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
局部变量定义:
Node<K,V>[] tab:定义一个tab数组;
Node<K,V> p:定义一个结点p;
int n, i:定义两个int常量n和i;
1> if ((tab = table) == null || (n = tab.length) == 0)
table为一个全局变量,初始值为null。
先判断逻辑或的第一个表达式:将table值赋值给tab,table为null,故tab为null,此时逻辑或后第二个表达式将被短路。此时if语句判断为true,第一次添加元素“java”时,将走这个逻辑判断。
其中n = (tab = resize()).length:
resize()在初始化时,将tab赋给oldTab,为null,会走最后一个else逻辑:
newCap = DEFAULT_INITIAL_CAPACITY; DEFAULT_INITIAL_CAPACITY是一个int(16),newCap=16,
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
DEFAULT_LOAD_FACTOR = 0.75f,newThr=12;
threshold = newThr;
计算得到当前扩容临界值,此为12,
把newTab赋值给table,所以table的地址等于newTab,然后返回newTab,这时通过tab = resize()将newTab赋值给tab,所以tab地址也等于newTab,所以此时,tab和table指向同一个地方。此时,n即为数组长度:16
源码如下:
源码6:
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
初始化后newTab的值

2> if ((p = tab[i = (n - 1) & hash]) == null):
(n - 1) & hash: 计算得到存放的索引位置,并判断当前tab的该位置是否为空,如果为空,则new 一个node(hash,key,value,next:null),将node存放在该位置。
3> ++modCount;:
操作数++
4> if (++size > threshold)
判断当前seze是否大于threshold(上面计算的结果12),如果大于则需扩容后再返回。
5> afterNodeInsertion
此为父类方法,提供为子类实现使用(如LinkedHashMap,需要输出的顺序和输入时的相同)
最后返回null,return map.put(e, PRESENT)==null结果返回了true,add元素成功。
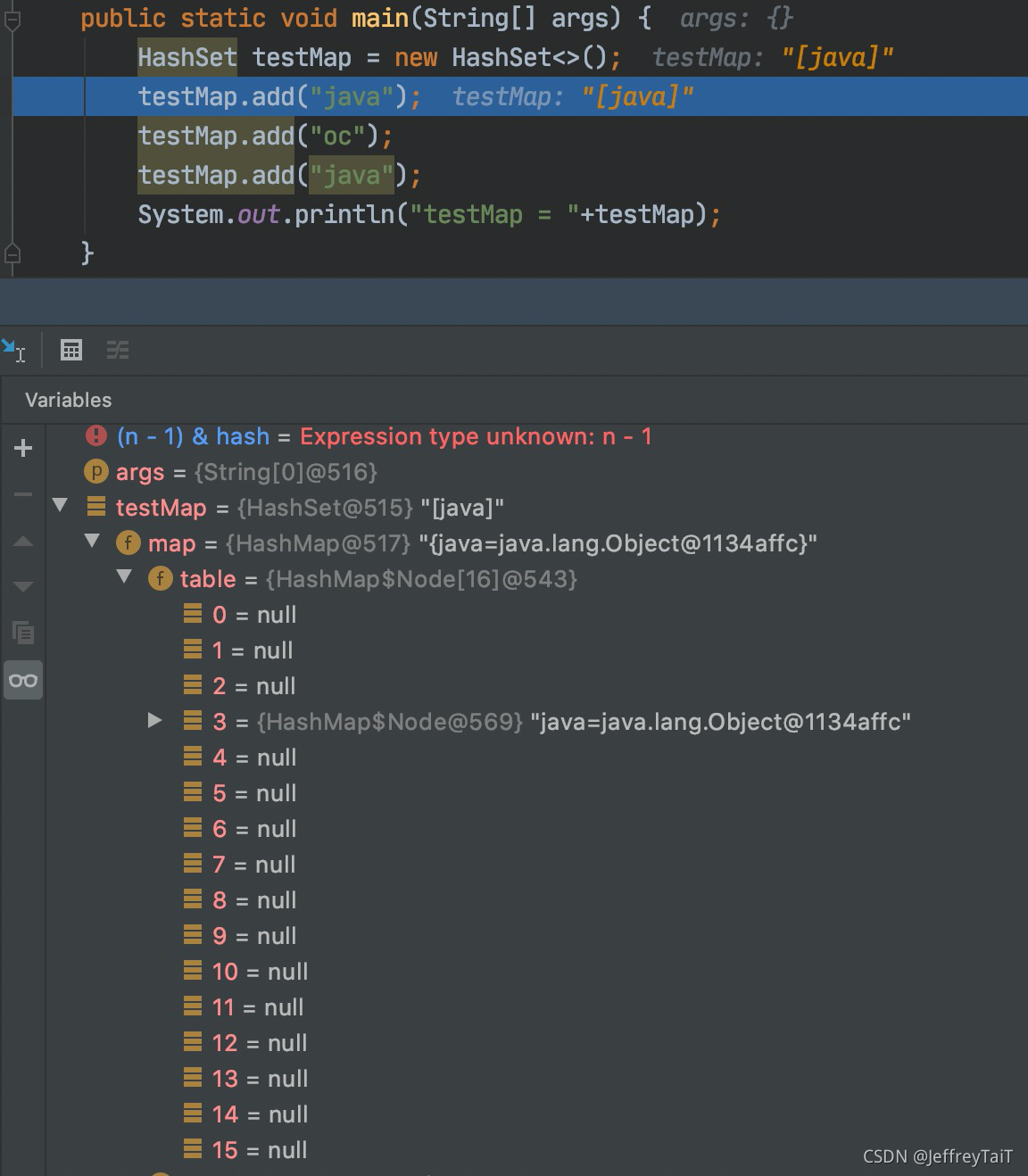
add(“oc”)阶段:

再到 putVal 方法:
因为 (p = tab[i = (n - 1) & hash]) == null,所以,对于元素oc来说,创建node后直接存放在对应的位置,modCount++,最后返回null。
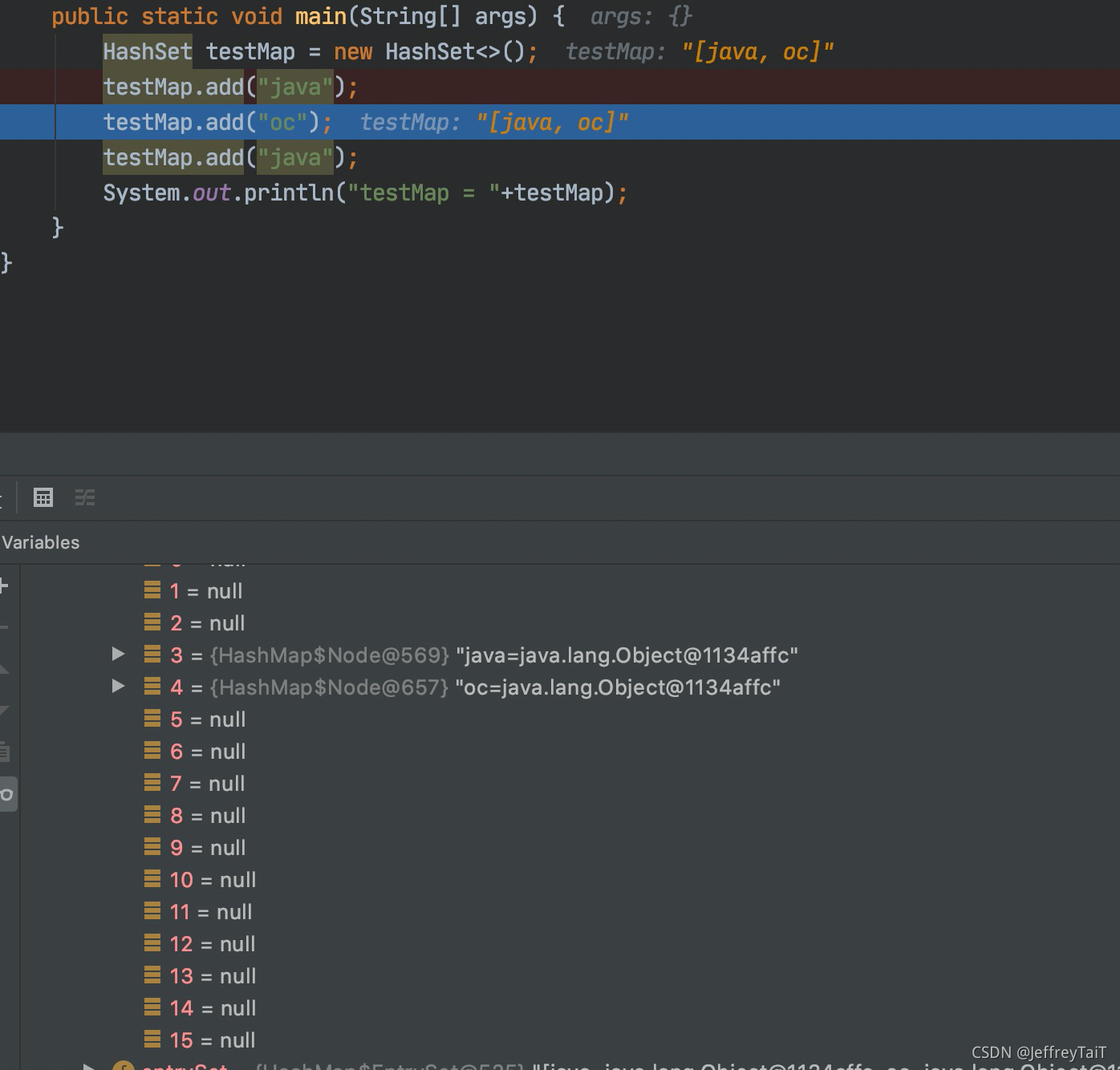
add(“java”)重复元素阶段:
因为此次tab不为null,n也不等于0,**if ((tab = table) == null || (n = tab.length) == 0)为false,并且if ((p = tab[i = (n - 1) & hash]) == null)**经过hashCode计算得到的tab表该位置已经有一个元素存在,所以也为false,此次应该走 源码5 的else的逻辑,即:
源码7
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
.
.
.
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
1>if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k)))):
条件一:当前索引位置对应的链表的第一个元素和准备添加元素的key的hash值一样
条件二:满足以下其一
1>准备加入的key和p指向的Node结点的key是同一个对象
2>p指向的Node结点的key的equals()和准备添加的key比较后相同
条件一、二,满足其一,则把p赋给临时结点e,再返回null。结果仍然是之前的两个元素。
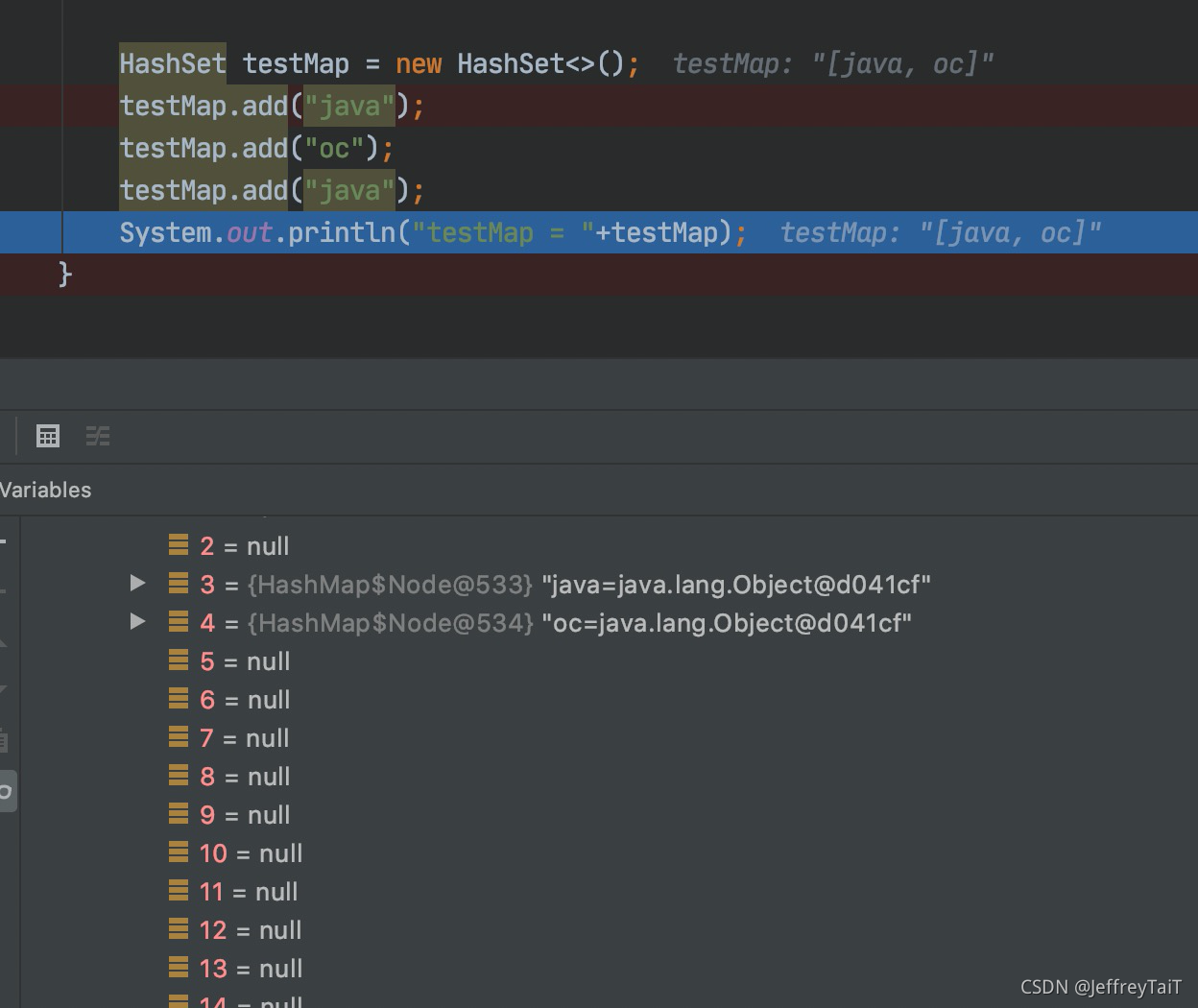
2>else if (p instanceof TreeNode):
判断p是否是红黑树,如果是红黑树,则调用红黑树的put方法
3>else:
如果前两个判断都是false,则进行for循环遍历链表,判断链表中的元素是否跟准备加入的元素相同。
结果一:有相同的情况,直接break
结果二:都不相同,则 p.next = newNode(hash, key, value, null),将元素插到该链表的最后
结果三:binCount >= TREEIFY_THRESHOLD(8)-1时,进行树化,即链表元素到达8个时,执行treeifyBin方法准备进行树化,内部会再判断if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY),tab数组大小是否到达64,如果小于则先进行扩容,否则进行树化。
所以hashmap转红黑树的两个条件:
1.一个是链表长度大于8
2.组长度是大于等于64
注意:
1.put第二个元素的时候才开始走else逻辑;
2.p每次都是从第一个元素开始,当binCount=0时,表里已有一个元素,此时如果(e = p.next) != null,p=e,也就是说,此时表里有两个元素,以此内推,当binCount=6时,表里已经有8个元素,当再循环,满足(e = p.next) == null,此时,binCount=7,tab表里已经有8个,准备加入第9个元素key,满足了binCount >= TREEIFY_THRESHOLD - 1=7,进入树化逻辑。
不放心的我又找了几个hashcode相同的字符,进行验证:
public static void main(String[] args) {
HashSet testMap = new HashSet();
testMap.add("轷龚");
testMap.add("轸齻");
testMap.add("轹齜");
testMap.add("轺鼽");
testMap.add("轻鼞");
testMap.add("轼黿");
testMap.add("载黠");
testMap.add("轾黁");
testMap.add("轿麢");
System.out.println("testMap = "+testMap);
}
结果自然在添加第九个元素"轿麢"时,才进入树化逻辑。
如果
核心调用方法链:
- add(E e)
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
- put(K key, V value)
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
2.1 hash(Object key)
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
- putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict)
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
3.1 resize()
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
待续…

















 1283
1283

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









