




 本文详细介绍了使用Python爬取动漫壁纸的过程,从分析网站结构、提取图片链接到多线程下载,展示了完整的爬虫实现步骤。
本文详细介绍了使用Python爬取动漫壁纸的过程,从分析网站结构、提取图片链接到多线程下载,展示了完整的爬虫实现步骤。
一、爬虫准备
1.用到的python第三方库
import requests
'''
pip 进行安装如果遇到time out 可以使用国内镜像源
这里推荐一下国内镜像源
阿里云: http://mirrors.aliyun.com/pypi/simple/
中国科技大学: https://pypi.mirrors.ustc.edu.cn/simple/
豆瓣(douban): http://pypi.douban.com/simple/
清华大学 https://pypi.tuna.tsinghua.edu.cn/simple/
中国科学技术大学: http://pypi.mirrors.ustc.edu.cn/simple/
例如:
短时间使用:
pip install "库名"-i https://pypi.tuna.tsinghua.edu.cn/simple/ --trusted-host pypi.tuna.tsinghua.edu.cn
长时间使用:
需要在自己的这个目录下(C:\Users\12720\AppData\Roaming)自己的看着做
新建一个pip文件夹在建一个pip.txt写入内容保存以后改扩展名为ini
内容:
[global]
index-url = https://pypi.tuna.tsinghua.edu.cn/simple
[install]
trusted-host=mirrors.aliyun.com
'''
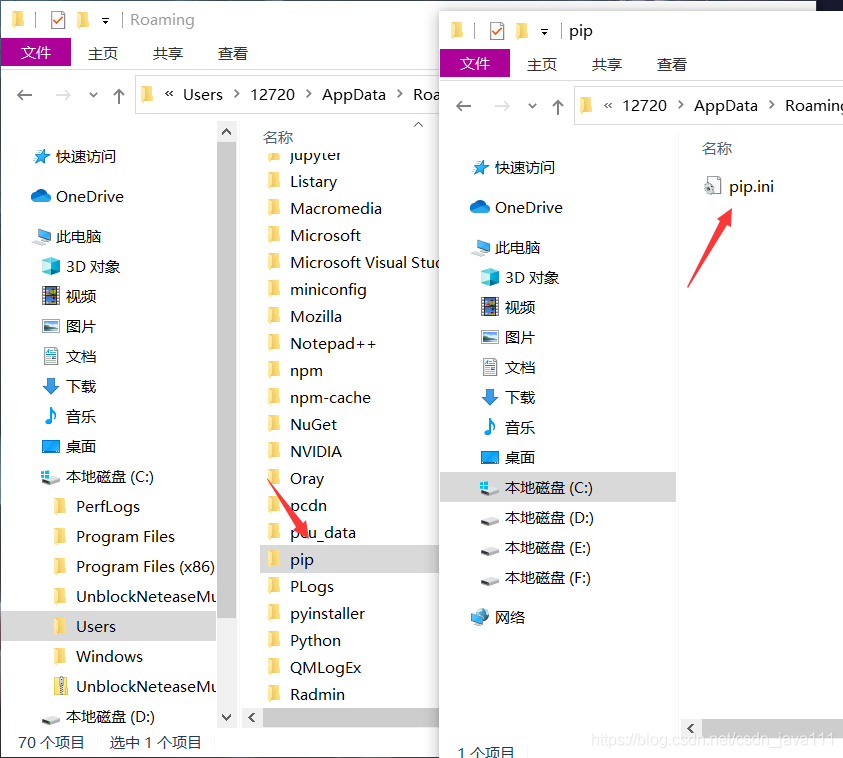
下面pip操作就会非常的快。。。
2.网站分析
- URL链接
- 主网页分析
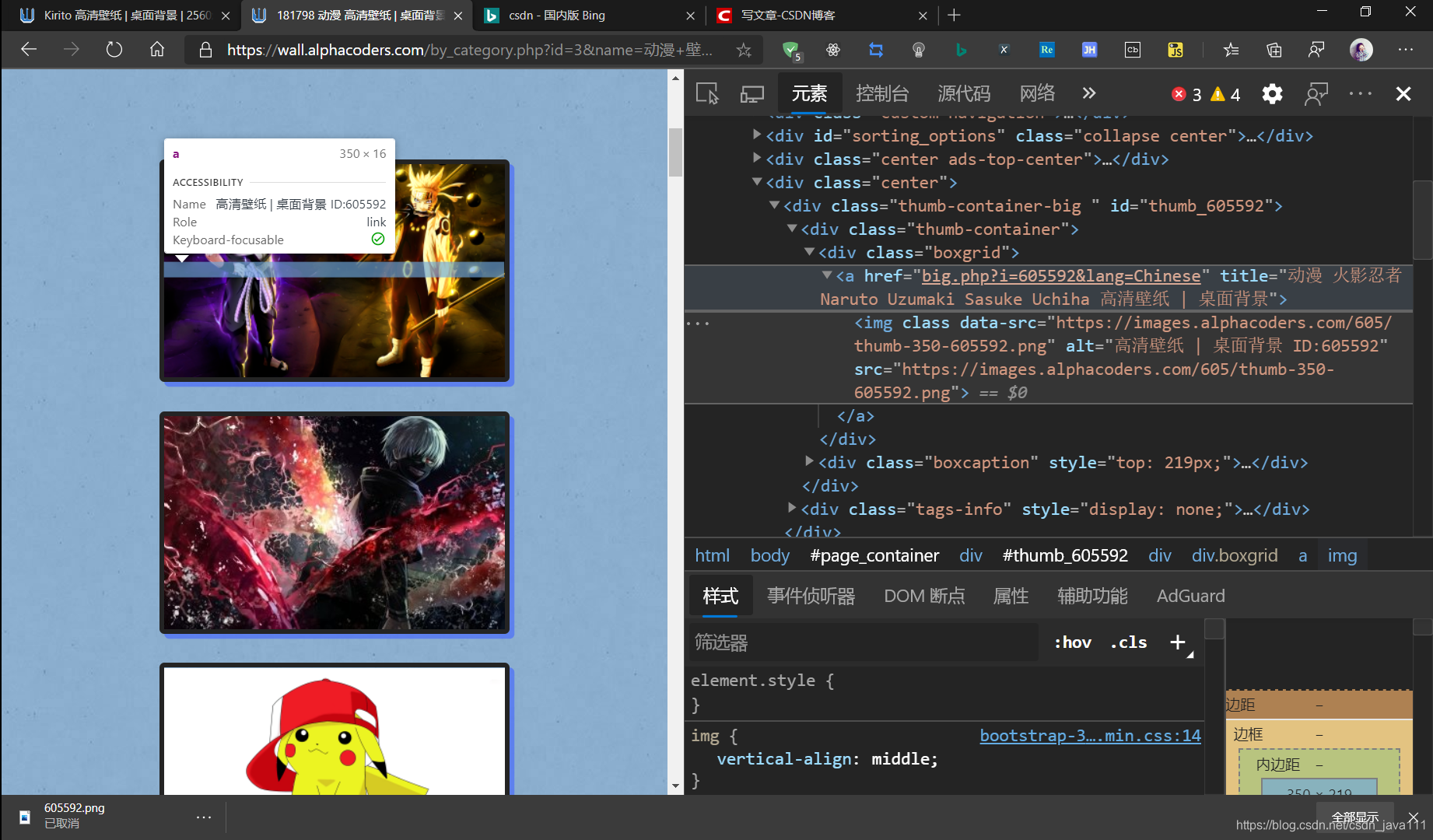
好吧看不出什么。。 - 详情页分析
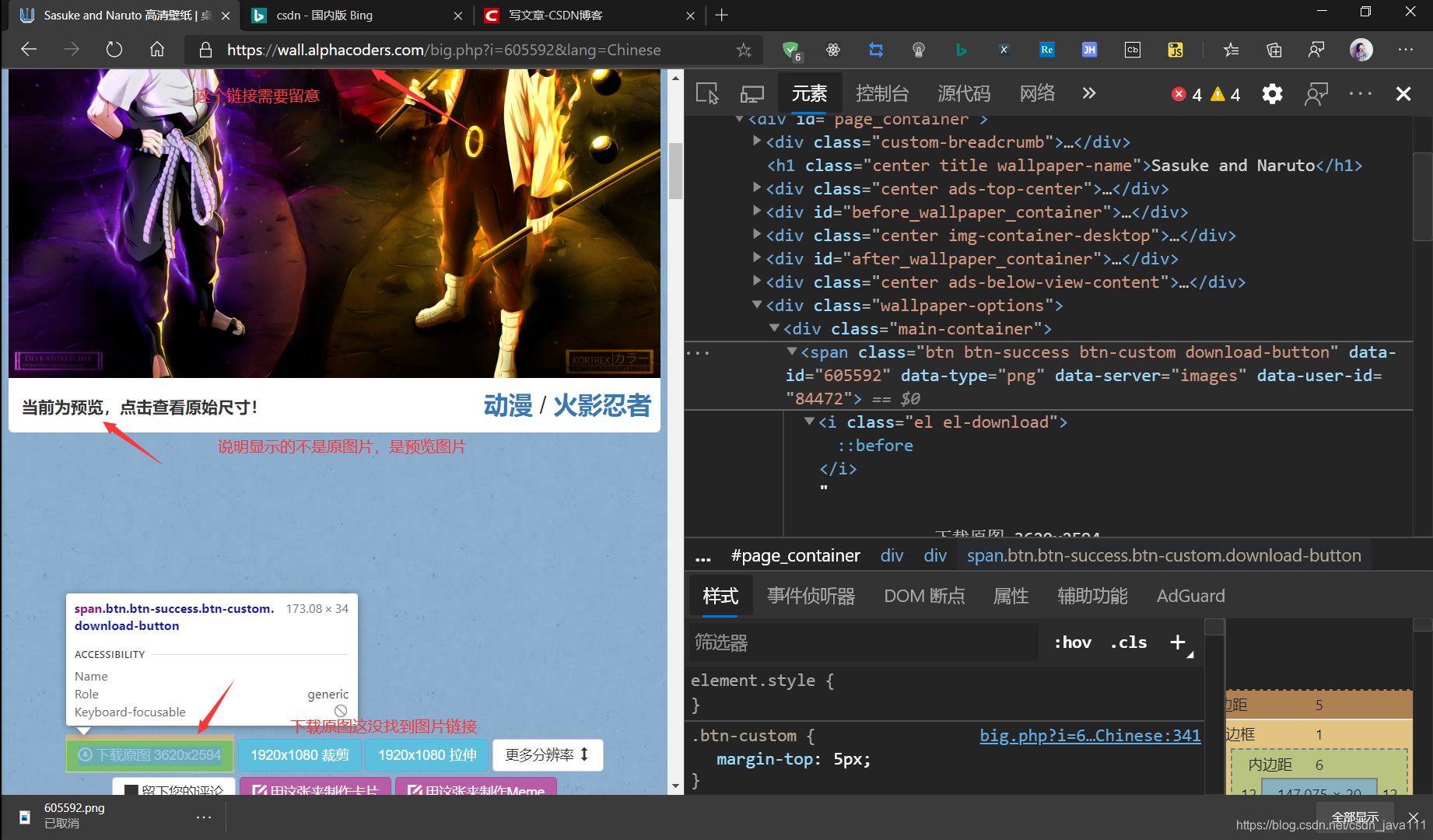
好吧,真实图片链接在哪呢。。。那个图片不是可以点下载吗,点进去试试看,说不定有意外收获!!!
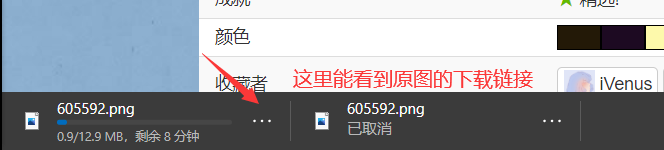
看终于找到了吧。。。
3.接下来分析url链接
- 分析原图片链接

发现前半部分是一样,那我们是不是有个想法,想办法拼接它,以此来获得原图片url链接,好的思路来了开始开干,测试过程中发现最后面的可以不用它,找不到方法,看看前面的页面。 - 详情页图片链接分析
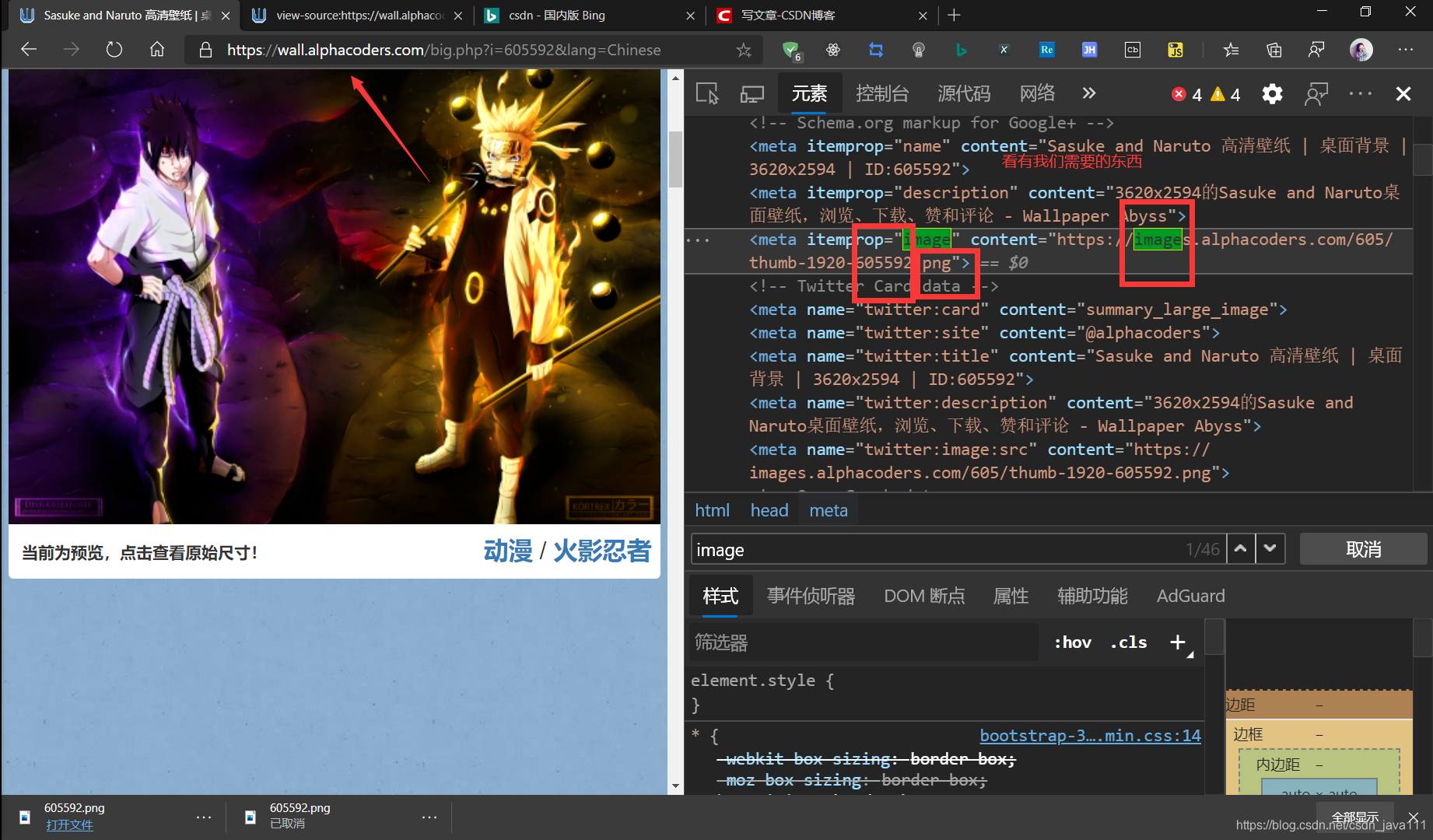 看我们能找到我们需要的东西,那是不是有个想法,打开这个页面,找到这个图片链接进行拆分它,获取我们想要的部分
看我们能找到我们需要的东西,那是不是有个想法,打开这个页面,找到这个图片链接进行拆分它,获取我们想要的部分 - 主页面链接分析


仔细观察,是不是这两个链接的i参数不同,就把i当作这个图片id吧,那是不是意味着我们在主页面里找到图片id进行拼接详情页链接,是不是就能获得那个图片链接,紧接着通过一些操作获得原图片链接!!!前提,主页面是否有图片id
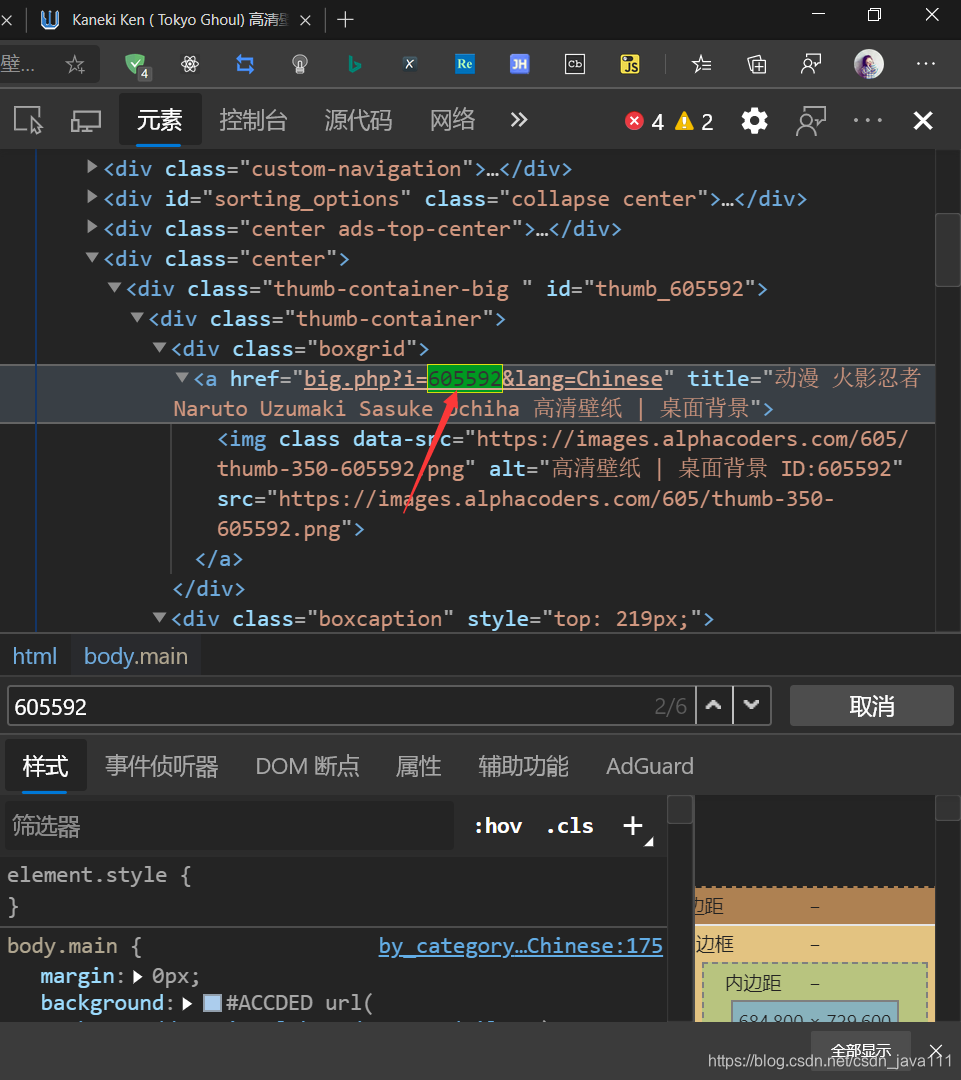
- 看看是否可以翻页


欧克,看图片id,到这里是不是就大功告成了,写代码的前提首先必须你有思路,否则你都不知道最后自己写的什么,接下来是不是就是一步步完成前面分析的东西,说干就干开始撸代码。。。
二、代码解析
- 请求页面
import requests
import re
import threading
import time
thread_lock=threading.BoundedSemaphore(value=10)
headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36 Edg/84.0.522.52'}
def get_page(url): #获得页面
resp=requests.get(url,headers=headers).text
return resp
'''
发现过程中或多次用到请求页面,避免重复劳动干脆定义一个get_page的方法
幸运的是这个没什么反爬,就不过多介绍。
'''
- 获得详情页链接
def get_url(link_url): #获得粗略链接
resp=get_page(link_url)
menu_url = 'https://wall.alphacoders.com/big.php?i={}&lang=Chinese'
pic_ids=re.compile(' <div class="thumb-container-big " id="thumb_(.+?)">').findall(resp)
menu_links=[menu_url.format(pic_id) for pic_id in pic_ids]
return menu_links
'''
这里使用format格式化字符来拼接图片id,我这里使用的正则表达式来获得图片id的
当然也可以使用xpath,BeautifulSoup,建议多使用列表表达式,节省代码行数。
'''
- 获得图片链接
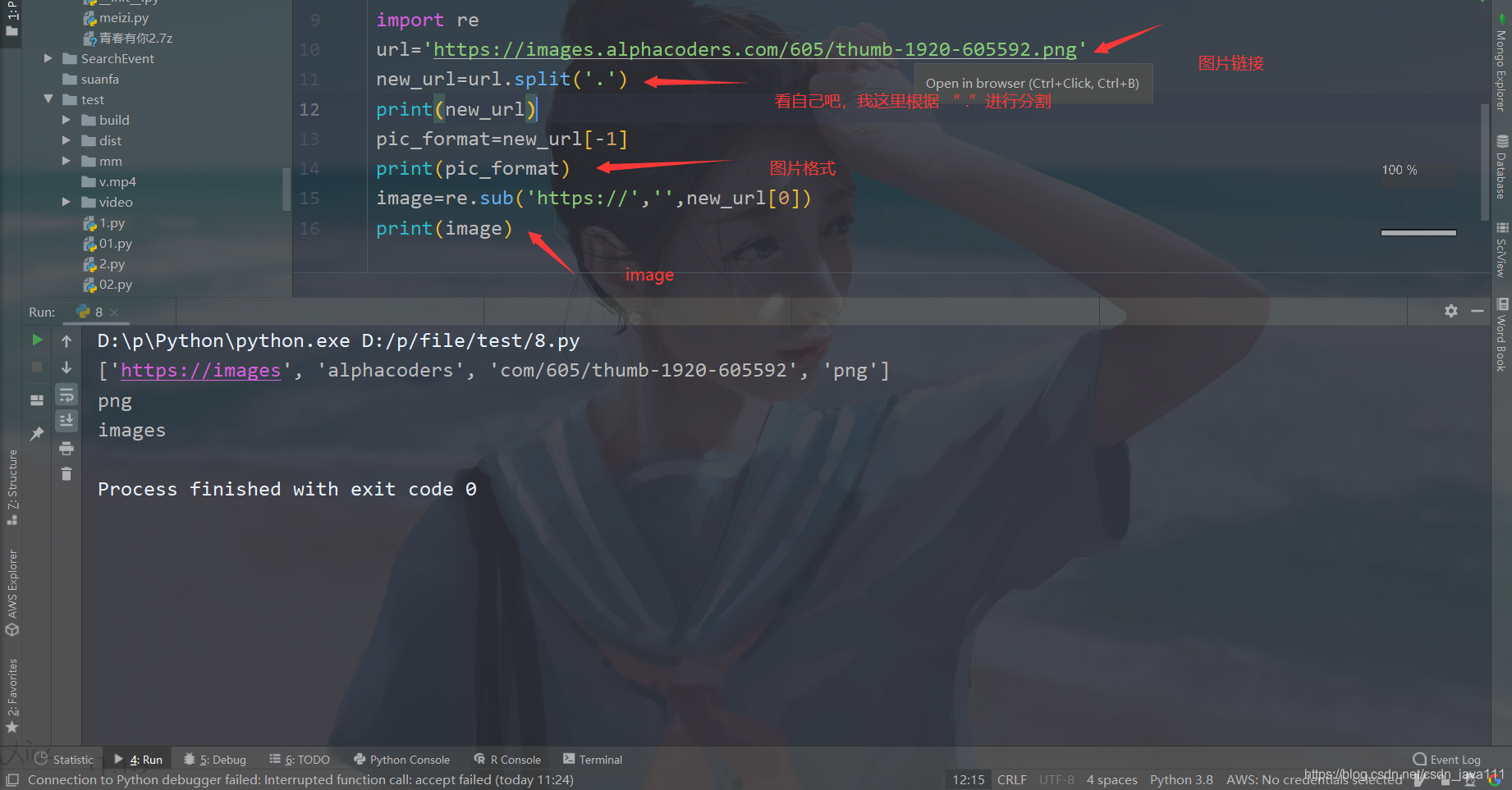
def parser_url(picture_url): #获得原图链接
resp=get_page(picture_url)
get_url = re.compile('"image" content="(.+?)" />').findall(resp)[0].split('.')
pic_format = get_url[3]
image = re.sub('https://', '', get_url[0])
id = get_url[2].split('-')[-1]
base_url = 'https://initiate.alphacoders.com/download/wallpaper/{}/{}/{}'
pic_url = base_url.format(id, image, pic_format)
return pic_url,pic_format
'''
找到那个图片链接,先用split进行拆分,然后取值,有些不好取值的处理下,我这里使用re里一些方法进行替换把不需要替换成空白字符。
单独拿出来说一下,见下图。。。
'''
上面已经拿到图片的id,都拿到了以后进行链接拼接来获得原图片链接,最好一个返回一个图片格式,下载保存时防止图片失真。
- 保存图片和主程序入口
ef download(picu,count): #下载图片
picture=requests.get(picu,headers=headers).content
print('第{}张.{}下载完成'.format(count, pic[1]))
with open('./动漫/{}.{}'.format(count, pic[1]), 'wb') as fp:
fp.write(picture)
if __name__ == '__main__':
url = 'https://wall.alphacoders.com/by_category.php?id=3&name=%E5%8A%A8%E6%BC%AB+%E5%A3%81%E7%BA%B8&lang=Chinese&page={}'
count=0
for i in range(1,10):
time.sleep(0.5)
page=url.format(i)
menu_links=get_url(page)
for menu_link in menu_links:
count+=1
time.sleep(1)
pic=parser_url(menu_link)
picu=pic[0]
print('第{}张.{}下载完成'.format(count,pic[1]))
process=threading.Thread(target=download,args=(picu,count))
process.start()
三、成果展示
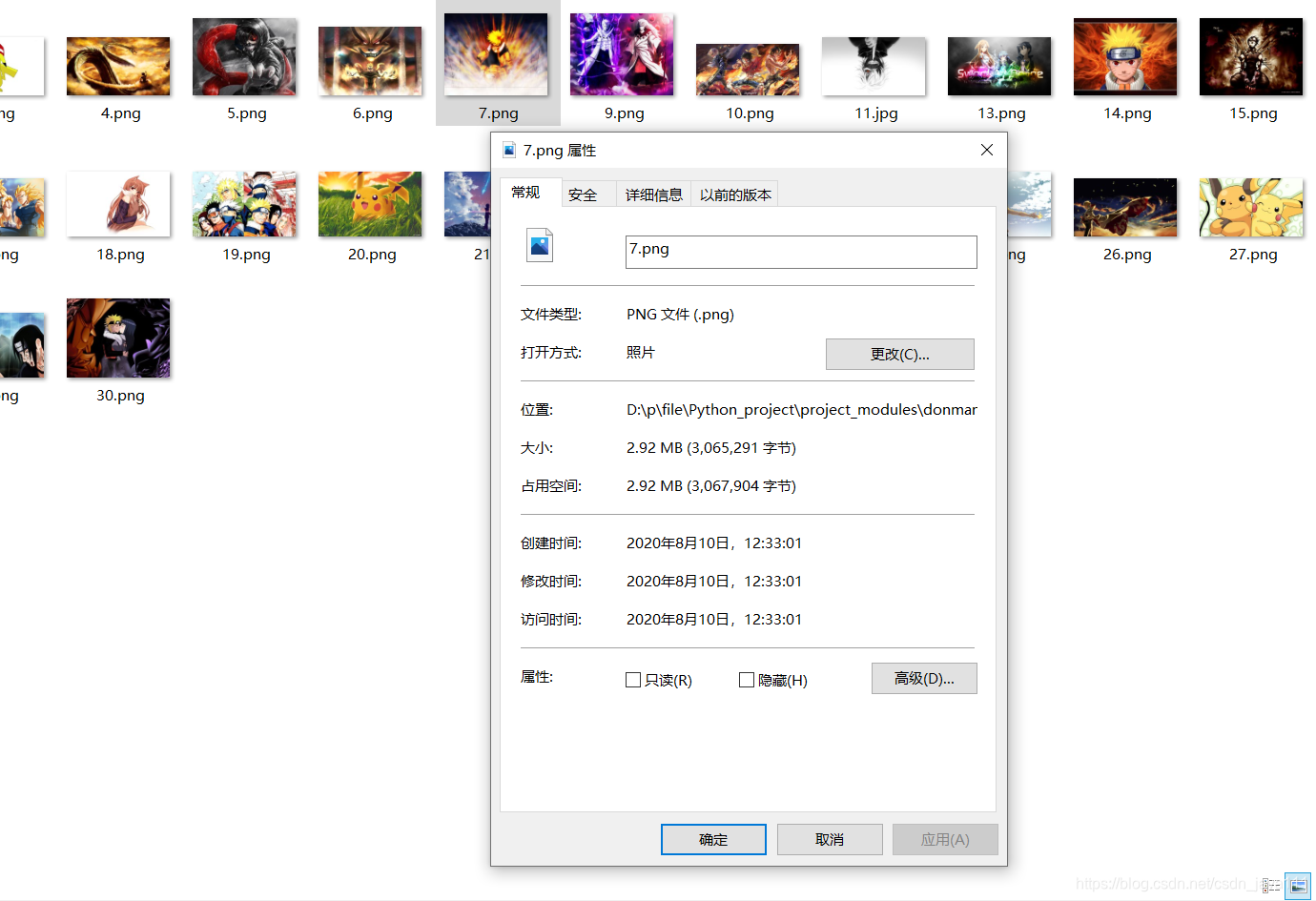
看这大小是原图没错了。。。
四、代码展示
import requests
import re
import threading
import time
thread_lock=threading.BoundedSemaphore(value=10)
headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36 Edg/84.0.522.52'}
def get_page(url): #获得页面
resp=requests.get(url,headers=headers).text
return resp
def get_url(link_url): #获得粗略链接
resp=get_page(link_url)
menu_url = 'https://wall.alphacoders.com/big.php?i={}&lang=Chinese'
pic_ids=re.compile(' <div class="thumb-container-big " id="thumb_(.+?)">').findall(resp)
menu_links=[menu_url.format(pic_id) for pic_id in pic_ids]
return menu_links
def parser_url(picture_url): #获得原图链接
resp=get_page(picture_url)
get_url = re.compile('"image" content="(.+?)" />').findall(resp)[0].split('.')
pic_format = get_url[3]
image = re.sub('https://', '', get_url[0])
id = get_url[2].split('-')[-1]
base_url = 'https://initiate.alphacoders.com/download/wallpaper/{}/{}/{}'
pic_url = base_url.format(id, image, pic_format)
return pic_url,pic_format
def download(picu,count): #下载图片
picture=requests.get(picu,headers=headers).content
print('第{}张.{}下载完成'.format(count, pic[1]))
with open('./动漫/{}.{}'.format(count, pic[1]), 'wb') as fp:
fp.write(picture)
if __name__ == '__main__':
url = 'https://wall.alphacoders.com/by_category.php?id=3&name=%E5%8A%A8%E6%BC%AB+%E5%A3%81%E7%BA%B8&lang=Chinese&page={}'
count=0
for i in range(1,10):
time.sleep(0.5)
page=url.format(i)
menu_links=get_url(page)
for menu_link in menu_links:
count+=1
time.sleep(1)
pic=parser_url(menu_link)
picu=pic[0]
print('第{}张.{}下载完成'.format(count,pic[1]))
process=threading.Thread(target=download,args=(picu,count))
process.start()
大功告成,小妹妹高兴坏了。。。

















 2703
2703





 到【灌水乐园】发言
到【灌水乐园】发言







