 P4语言与控制器实现数据包CPU转发
P4语言与控制器实现数据包CPU转发





 本文档展示了如何使用P4语言编写一个简单的交换机程序,该程序在解析到IPv4包时,根据控制器指令将数据包转发到CPU端口。控制器部分通过Scapy库获取并处理接收到的CPU端口数据包,更新路由规则,并通过Thrift接口与P4交换机交互。整个流程涉及P4解析器、表操作、控制器规则添加以及数据包的回送。
本文档展示了如何使用P4语言编写一个简单的交换机程序,该程序在解析到IPv4包时,根据控制器指令将数据包转发到CPU端口。控制器部分通过Scapy库获取并处理接收到的CPU端口数据包,更新路由规则,并通过Thrift接口与P4交换机交互。整个流程涉及P4解析器、表操作、控制器规则添加以及数据包的回送。
send_to_cpu
编写p4语言时不用写匹配规则,可以由控制器编写规则
拓扑
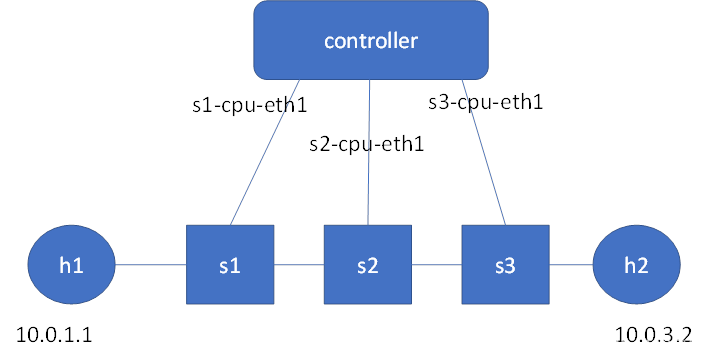
{
"program": "send_to_cpu.p4",
"switch": "simple_switch",
"compiler": "p4c",
"options": "--target bmv2 --arch v1model --std p4-16",
"switch_cli": "simple_switch_CLI",
"cli": true,
"pcap_dump": true,
"enable_log": true,
"cpu_port": true,
"topo_module": {
"file_path": "",
"module_name": "p4utils.mininetlib.apptopo",
"object_name": "AppTopo"
},
"controller_module": null,
"topodb_module": {
"file_path": "",
"module_name": "p4utils.utils.topology",
"object_name": "Topology"
},
"mininet_module": {
"file_path": "",
"module_name": "p4utils.mininetlib.p4net",
"object_name": "P4Mininet"
},
"topology": {
"links": [["h1","s1"], ["s3","h2"], ["s1","s2"], ["s2","s3"]],
"hosts": {
"h1": {
},
"h2": {
}
},
"switches": {
"s1": {
"cli_input": "s1-commands.txt",
"program": "send_to_cpu.p4",
"cpu_port": true
},
"s2": {
"cli_input": "s2-commands.txt",
"program": "send_to_cpu.p4",
"cpu_port": true
},
"s3": {
"cli_input": "s3-commands.txt",
"program": "send_to_cpu.p4",
"cpu_port": true
}
}
}
}
p4文件
/* -*- P4_16 -*- */
#include <core.p4>
#include <v1model.p4>
const bit<16> TYPE_IPV4 = 0x800;
/*************************************************************************
*********************** H E A D E R S ***********************************
*************************************************************************/
typedef bit<9> egressSpec_t;
typedef bit<48> macAddr_t;
typedef bit<32> ip4Addr_t;
header ethernet_t {
macAddr_t dstAddr;
macAddr_t srcAddr;
bit<16> etherType;
}
header ipv4_t {
bit<4> version;
bit<4> ihl;
bit<8> tos;
bit<16> totalLen;
bit<16> identification;
bit<3> flags;
bit<13> fragOffset;
bit<8> ttl;
bit<8> protocol;
bit<16> hdrChecksum;
ip4Addr_t srcAddr;
ip4Addr_t dstAddr;
}
struct metadata {
}
struct headers {
ethernet_t ethernet;
ipv4_t ipv4;
}
/*************************************************************************
*********************** P A R S E R ***********************************
*************************************************************************/
parser MyParser(packet_in packet,
out headers hdr,
inout metadata meta,
inout standard_metadata_t standard_metadata) {
state start {
packet.extract(hdr.ethernet);
transition select(hdr.ethernet.etherType){
TYPE_IPV4: ipv4;
default: accept;
}
}
state ipv4 {
packet.extract(hdr.ipv4);
transition accept;
}
}
/*************************************************************************
************ C H E C K S U M V E R I F I C A T I O N *************
*************************************************************************/
control MyVerifyChecksum(inout headers hdr, inout metadata meta) {
apply { }
}
/*************************************************************************
************** I N G R E S S P R O C E S S I N G *******************
*************************************************************************/
control MyIngress(inout headers hdr,
inout metadata meta,
inout standard_metadata_t standard_metadata) {
action drop() {
mark_to_drop(standard_metadata);
}
action ipv4_forward(macAddr_t dstAddr, egressSpec_t port) {
//set the src mac address as the previous dst, this is not correct right?
hdr.ethernet.srcAddr = hdr.ethernet.dstAddr;
//set the destination mac address that we got from the match in the table
hdr.ethernet.dstAddr = dstAddr;
//set the output port that we also get from the table
standard_metadata.egress_spec = port;
//decrease ttl by 1
hdr.ipv4.ttl = hdr.ipv4.ttl -1;
}
action to_cpu(egressSpec_t port) {
standard_metadata.egress_spec = port;
}
table ipv4_lpm {
key = {
hdr.ipv4.dstAddr: lpm;
}
actions = {
ipv4_forward;
to_cpu;
drop;
}
size = 1024;
}
apply {
//only if IPV4 the rule is applied. Therefore other packets will not be forwarded.
if (hdr.ipv4.isValid()){
ipv4_lpm.apply();
}
}
}
/*************************************************************************
**************** E G R E S S P R O C E S S I N G *******************
*************************************************************************/
control MyEgress(inout headers hdr,
inout metadata meta,
inout standard_metadata_t standard_metadata) {
apply {
}
}
/*************************************************************************
************* C H E C K S U M C O M P U T A T I O N **************
*************************************************************************/
control MyComputeChecksum(inout headers hdr, inout metadata meta) {
apply {
update_checksum(
hdr.ipv4.isValid(),
{ hdr.ipv4.version,
hdr.ipv4.ihl,
hdr.ipv4.tos,
hdr.ipv4.totalLen,
hdr.ipv4.identification,
hdr.ipv4.flags,
hdr.ipv4.fragOffset,
hdr.ipv4.ttl,
hdr.ipv4.protocol,
hdr.ipv4.srcAddr,
hdr.ipv4.dstAddr },
hdr.ipv4.hdrChecksum,
HashAlgorithm.csum16);
}
}
/*************************************************************************
*********************** D E P A R S E R *******************************
*************************************************************************/
control MyDeparser(packet_out packet, in headers hdr) {
apply {
//parsed headers have to be added again into the packet.
packet.emit(hdr.ethernet);
packet.emit(hdr.ipv4);
}
}
/*************************************************************************
*********************** S W I T C H *******************************
*************************************************************************/
//switch architecture
V1Switch(
MyParser(),
MyVerifyChecksum(),
MyIngress(),
MyEgress(),
MyComputeChecksum(),
MyDeparser()
) main;
控制器
import nnpy
import struct
from p4utils.utils.topology import Topology
from p4utils.utils.sswitch_API import SimpleSwitchAPI
#from scapy.all import Ether, sniff, Packet, BitField
from scapy.all import *
rules=[]
class myController(object):
def __init__(self):
self.topo = Topology(db="topology.db")
self.controllers = {}
self.connect_to_switches()
def connect_to_switches(self):
for p4switch in self.topo.get_p4switches():
thrift_port = self.topo.get_thrift_port(p4switch)
#print "p4switch:", p4switch, "thrift_port:", thrift_port
self.controllers[p4switch] = SimpleSwitchAPI(thrift_port)
def recv_msg_cpu(self, pkt):
print "-------------------------------------------------------------------"
global rules
print "interface:", pkt.sniffed_on
print "summary:", pkt.summary()
if IP in pkt:
ip_src=pkt[IP].src
ip_dst=pkt[IP].dst
print "ip_src:", ip_src, " ip_dst:", ip_dst
if (ip_src, ip_dst) not in rules:
rules.append((ip_src, ip_dst))
print "rules:", rules
else:
return
switches = {sw_name:{} for sw_name in self.topo.get_p4switches().keys()}
#print "switches:", switches
for sw_name, controller in self.controllers.items():
for host in self.topo.get_hosts_connected_to(sw_name):
host_ip_addr = self.topo.get_host_ip(host)
if ip_src == host_ip_addr:
sw_src = sw_name
if ip_dst == host_ip_addr:
sw_dst = sw_name
sw_port = self.topo.node_to_node_port_num(sw_name, host)
host_ip = self.topo.get_host_ip(host) + "/32"
host_mac = self.topo.get_host_mac(host)
#print host, "(", host_ip, host_mac, ")", "-->", sw_name, "with port:", sw_port
#add rule
print "table_add at {}:".format(sw_name)
self.controllers[sw_name].table_add("ipv4_lpm", "ipv4_forward", [str(host_ip)], [str(host_mac), str(sw_port)])
print "sw_src:", sw_src, "sw_dst:", sw_dst
paths = self.topo.get_shortest_paths_between_nodes(sw_src, sw_dst)
sw_1=sw_src
for next_hop in paths[0][1:]:
host_ip = ip_dst + "/32"
sw_port = self.topo.node_to_node_port_num(sw_1, next_hop)
dst_sw_mac = self.topo.node_to_node_mac(next_hop, sw_1)
#add rule
print "table_add at {}:".format(sw_1)
self.controllers[sw_1].table_add("ipv4_lpm", "ipv4_forward", [str(host_ip)],
[str(dst_sw_mac), str(sw_port)])
sw_1=next_hop
print "send original packet back from ", pkt.sniffed_on
sendp(pkt, iface=pkt.sniffed_on, verbose=False)
def run_cpu_port_loop(self):
cpu_interfaces = [str(self.topo.get_cpu_port_intf(sw_name).replace("eth0", "eth1")) for sw_name in self.controllers]
sniff(iface=cpu_interfaces, prn=self.recv_msg_cpu)
if __name__ == "__main__":
controller = myController()
controller.run_cpu_port_loop()
告知交换机发送到cpu的端口
table_set_default ipv4_lpm to_cpu 3
测试
运行p4run后,python开启控制器

















 535
535

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









