 JUC下原子类的详细讲解
JUC下原子类的详细讲解




原子整数 原子引用
原子整数,如AtomicInteger、AtomicLong等,它们的方法都是采用cas+volatile保证了原子性。
原子引用,如AtomicReference、AtomicStampReference、AtomicMarkableReference,用于引用类型,使用方法跟原子整数差不多,都是new出来,然后对象调用方法。
它们实际维护的值被放在属性value中。value被volatile修饰,确保读取值时到主存读取,拿到的值是最新值。
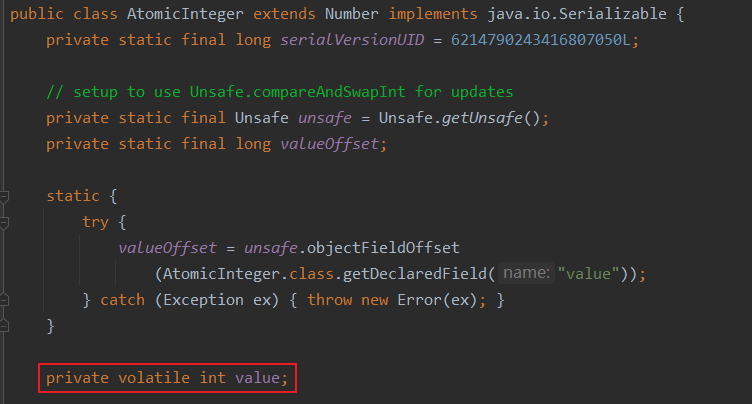
cas一般传入两个参数,这里拿AotmicInteger举例,expect是传入你获得到的value值,update传入要修改成的值(要更新,拿到value值,计算得到新值)。cas会拿expect去跟现在最新的value值对比,如果一致,证明value没有被其他线程修改过,那么修改成功;如果不一致,证明value已经被其他线程修改了,那么这次cas修改失败。

ABA
由于cas是对比原先值和最新值,只要一致,就可以修改。于是,会出现ABA问题。
ABA问题就是,比如value初始值是A,线程1拿到value为A,准备把value修改为C。在拿到A后,修改为C前,有线程2将value从A改为B,线程3又将value从B改为A,然后,线程1才接着执行,它要把value改为C,一看,它拿到的value是A,现在最新的value也是A,一致,于是cas修改成功。在这种情况下,线程A无法感知到其他线程对共享变量value从A改到B,又从B改回A的操作。
如果希望,线程修改value时,只要value被其他线程修改过,就cas失败,那么,可以加上一个版本号,只要value被修改一次,版本号就加1。线程修改时,不仅对比value值,还对比版本号,这样就可以避免ABA问题。
JUC也提供了带版本号的原子类AtomicStampedReference
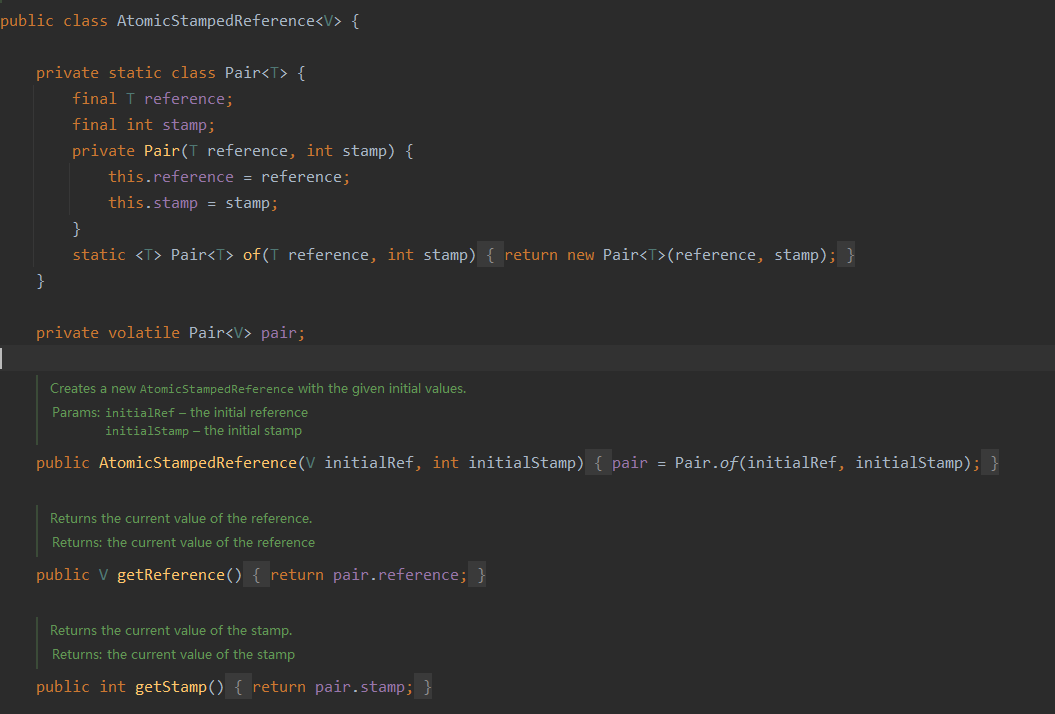
它维护的值放在属性reference中,版本号是stamp。
它也提供了compareAndSet(cas)方法,比之前的类就是多了版本号。

但有时候,我们并不关心变量被修改了多少次,只关心是否被修改过,于是AtomicMarkableReference就登场了,它不像AtomicStampedReference维护整数版本号,而是维护一个boolean值。
原子数组
因为原子引用保护的是引用本身的线程安全,它修改的是引用本身地址,但它无法保护引用内部元素的变化,如数组。当线程不是想修改引用本身地址,而是想修改内部元素时,就要用到原子数组类了。如AtomicIntegerArray,该类还重写了toString()方法,可以直接打印。
一个使用原子数组和不安全数组进行自增的对比测试,使用了函数式接口编程,博主觉得是个非常好的例子,分享给大家。
public class Test39 {
public static void main(String[] args) {
//线程不安全数组
demo(
() -> new int[10],
(array) -> array.length,
(array,index) -> array[index]++,
(array) -> System.out.println(Arrays.toString(array))
);
//线程安全数组
demo(
() -> new AtomicIntegerArray(10), //原子数组
(array) -> array.length(),
(array,index) -> array.getAndIncrement(index),
(array) -> System.out.println(array)
);
}
/**
*
* @param arraySupplier 提供数组,可以是线程不安全数组或线程安全数组
* @param lengthFun 获取数组长度的方法
* @param putConsumer 自增方法,回传array、index
* @param printConsumer 打印数组的方法
*/
//参数是函数式接口给你的,结果是调用者要给回来的
//supplier 提供者 无中生有(无参,要结果) () -> 结果
//function 函数 一个参数一个结果 (参数)->结果 BiFunction (参数1,参数2)->结果
//consumer 消费者 一个参数没结果 (参数) -> void BiConsumer (参数1,参数2) -> void
private static <T> void demo(
Supplier<T> arraySupplier,
Function<T, Integer> lengthFun,
BiConsumer<T, Integer> putConsumer,
Consumer<T> printConsumer ){
List<Thread> ts = new ArrayList<>(); //线程集合,将线程加到集合里方便统一操作
//拿到数组
T array = arraySupplier.get();
int length = lengthFun.apply(array);
for (int i = 0; i < length; i++) { //length个线程,即数组有多长,就拿多少个线程
//每个线程对数组作10000次操作
ts.add(new Thread(() -> {
for (int j = 0; j < 10000; j++) {
putConsumer.accept(array, j % length); //j % length是拿下标,将操作均摊到数组的每个元素上
}
}));
}
//启动所有线程
ts.forEach(t -> t.start());
//等待所有线程结束
ts.forEach(t -> {
try {
t.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
});
printConsumer.accept(array);
}
}
输出结果:
[7730, 7745, 7732, 7696, 7704, 7725, 7764, 7730, 7721, 7756]
[10000, 10000, 10000, 10000, 10000, 10000, 10000, 10000, 10000, 10000]
字段更新器
字段更新器保护的是对象中的属性,它能保证多个线程访问同一个对象的成员变量时,成员变量的线程安全性。(即原子修改对象的成员变量)如AtomicReferenceFieldUpdater、AtomicIntegerFieldUpdater、AtomicLongFieldUpdater。
要注意,被保护的属性不能被private修饰,因为字段更新器要访问它。同时,被保护的属性必须被volatile修饰,因为要用cas,如果不被volatile修饰,会报错。
@Slf4j(topic = "c.Test40")
public class Test40 {
public static void main(String[] args) {
Student s = new Student();
//参数1:哪个类
//参数2:哪个属性
//参数3:属性名
AtomicReferenceFieldUpdater updater =
AtomicReferenceFieldUpdater.newUpdater(Student.class, String.class, "name");
System.out.println(updater.compareAndSet(s, null, "张三"));
System.out.println(s);
}
}
class Student {
volatile String name;
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
'}';
}
}
true
Student{name='张三'}
原子累加器
虽然原子整数可以调用如getAndIncrement()等方法进行累加,但JUC提供LongAdder原子累加器,它利用了cells累加单元,提高了累加效率,比调用原子整数方法累加效率快了许多。
具体原因是原子整数类累加都是在一个共享变量上累加,当竞争比较激烈时,就会频繁出现cas失败重试的现象,影响效率。而LongAdder在有竞争时会创建累加单元,每个线程有自己的累加单元,线程都在自己的累加单元上累加,最后将结果汇总,这样就减少了cas重试次数,提高了效率。
increment()
LongAdder的自增方法:increment()
它是调用了add(1L)
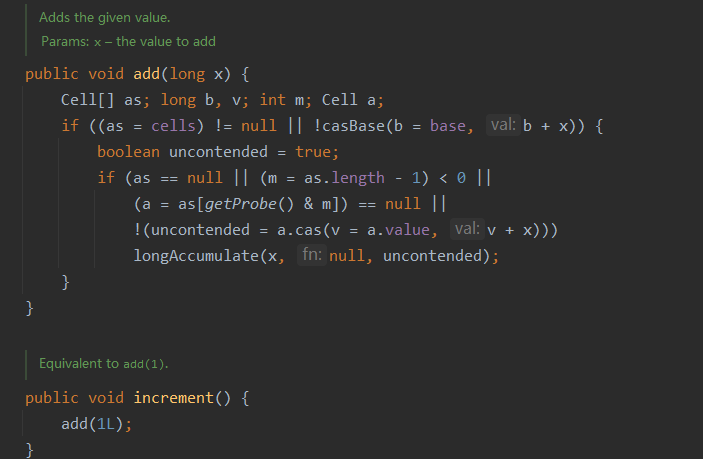
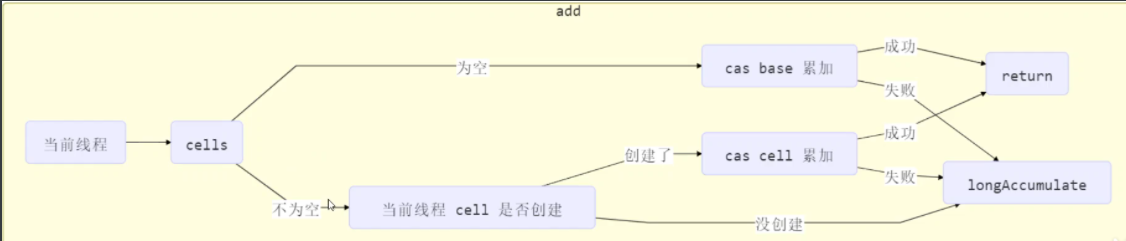
add流程如下:
①初始时,累加单元数组cells为空,即(as = cells) == null。caseBase在base属性上累加(没有竞争,就在base属性上累加,等同于原子整数类在一个变量上累加),如果cas成功,累加完成,add方法结束;如果cas失败,证明有竞争了,进入第一个if块。
因为【as == null】成立(累加单元数组cells为空),进入第二个if块,执行longAccumulate(),里面会去创建累加单元数组。
②再次调用add(1L),累加单元数组不为空了(那证明已经有过竞争了,不再在base属性上自增,要直接去累加单元上自增了),进入第1个if块,【a = as[getProbe() & m]) == null】判断当前线程是否有累加单元,如果没有,也就是条件成立,进入第二个if块。进入longAccumulate() (它去为当前线程创建累加单元)。如果当前线程有累加单元,【!(uncontended = a.cas(v = a.value, v + x))】让当前线程在自己的累加单元上进行cas操作,如果成功,add方法结束;如果失败,进入longAccumulate() (证明累加单元不够,扩容)
总结流程:
先看有没有累加单元数组,判断是否发生过竞争,没有就在base属性上cas,成功了直接返回,失败了就去调用longAccumulate()。有累加单元数组了,存在过竞争看当前线程是否有,累加单元,如果有,在累加单元上累加,成功返回,失败证明累加单元不够,去扩容,走longAccumulate();如果当前线程还没有累加单元,执行longAccumulate()
流程图:
longAccumulate()
先贴个整体
final void longAccumulate(long x, LongBinaryOperator fn,
boolean wasUncontended) {
int h;
if ((h = getProbe()) == 0) {
ThreadLocalRandom.current(); // force initialization
h = getProbe();
wasUncontended = true;
}
boolean collide = false; // True if last slot nonempty
for (;;) {
Cell[] as; Cell a; int n; long v;
if ((as = cells) != null && (n = as.length) > 0) {
if ((a = as[(n - 1) & h]) == null) {
if (cellsBusy == 0) { // Try to attach new Cell
Cell r = new Cell(x); // Optimistically create
if (cellsBusy == 0 && casCellsBusy()) {
boolean created = false;
try { // Recheck under lock
Cell[] rs; int m, j;
if ((rs = cells) != null &&
(m = rs.length) > 0 &&
rs[j = (m - 1) & h] == null) {
rs[j] = r;
created = true;
}
} finally {
cellsBusy = 0;
}
if (created)
break;
continue; // Slot is now non-empty
}
}
collide = false;
}
else if (!wasUncontended) // CAS already known to fail
wasUncontended = true; // Continue after rehash
else if (a.cas(v = a.value, ((fn == null) ? v + x :
fn.applyAsLong(v, x))))
break;
else if (n >= NCPU || cells != as)
collide = false; // At max size or stale
else if (!collide)
collide = true;
else if (cellsBusy == 0 && casCellsBusy()) {
try {
if (cells == as) { // Expand table unless stale
Cell[] rs = new Cell[n << 1];
for (int i = 0; i < n; ++i)
rs[i] = as[i];
cells = rs;
}
} finally {
cellsBusy = 0;
}
collide = false;
continue; // Retry with expanded table
}
h = advanceProbe(h);
}
else if (cellsBusy == 0 && cells == as && casCellsBusy()) {
boolean init = false;
try { // Initialize table
if (cells == as) {
Cell[] rs = new Cell[2];
rs[h & 1] = new Cell(x);
cells = rs;
init = true;
}
} finally {
cellsBusy = 0;
}
if (init)
break;
}
else if (casBase(v = base, ((fn == null) ? v + x :
fn.applyAsLong(v, x))))
break; // Fall back on using base
}
}
主要逻辑在for死循环中,用if/else分为三大块:
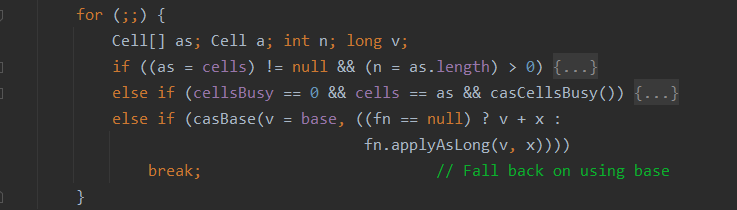
对应add()调用longAccumulate()的三种情况,分别来看:
①没有累加单元数组进来:
cells就是累加单元数组,当没有累加单元时,第一个if ((as = cells) != null && (n = as.length) > 0)判断失败,进入第二个if。cellsBusy == 0判断还没有线程对累加单元数组加锁,cells==as判断累加单元数组还是原来的那个,即没有被别的线程修改过(多线程情况下,可能当前线程判断了累加单元数组为空后,准备第二个if判断,另一个线程刚好改完释放了锁,当前线程就拿到了锁,所以还要判断一下cells是不是原来拿到的cells),casCellsBusy()是用cas对cells加锁,即将cellsBusy从0改为1。如果cas失败,会进入第三个if块,会去修改base的值,修改成功方法结束,修改失败继续循环。

如果三个条件都成立,进入第二个if块,准备创建累加单元数组
else if (cellsBusy == 0 && cells == as && casCellsBusy()) {
boolean init = false;
try { // Initialize table
//再次判断cells还是原来的cells
if (cells == as) {
//刚开始创建累加单元数组,大小只有2,后面才会慢慢扩容。
Cell[] rs = new Cell[2]; //大小为2的数组
rs[h & 1] = new Cell(x); //但只创建了一个累加单元
cells = rs; //将数组赋值给cells
init = true;
}
} finally {
cellsBusy = 0; //最后解锁
}
if (init)
break;
}
②有累加单元数组,但当前线程还没有累加单元:
明显会进入死循环中第一个if块,然后会进入这个if块,因为a = as[(n - 1) & h]) == null表示当前线程没有自己的累加单元。
if ((a = as[(n - 1) & h]) == null) {
//cells还没被加锁
if (cellsBusy == 0) { // Try to attach new Cell
//创建一个累加单元
Cell r = new Cell(x); // Optimistically create
//再次判断没有被加锁,cas去对cells加锁
if (cellsBusy == 0 && casCellsBusy()) {
boolean created = false;
try { // Recheck under lock
Cell[] rs; int m, j;
//再次检查cells不为空,并且当前线程累加单元为空
if ((rs = cells) != null &&
(m = rs.length) > 0 &&
rs[j = (m - 1) & h] == null) {
放入
rs[j] = r;
created = true;
}
} finally { //解锁
cellsBusy = 0;
}
if (created)
break;
continue; // Slot is now non-empty
}
}
collide = false;
}
③有累加单元数组,当前线程也有累加单元,但对累加单元累加失败:
这个块是对当前线程的累加单元再次尝试累加,如果成功,方法结束;如果失败,不会进这个else if,接着往下走。

boolean collide表示是否要扩容,如果累加单元数组长度大于CPU核心数,那么扩容后,即再增加累加单元,是没有意义的。如果没有超过CPU核心数,到else if(!collide),证明有累加单元数组并且在当前线程的累加单元上累加失败了,collide为false,于是进入这个else if块,将collide改为true,表示要扩容。
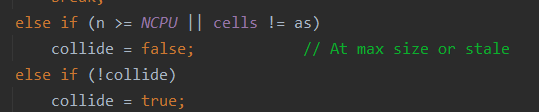
然后会继续循环,下一次循环会走扩容逻辑。
扩容逻辑进入下面这个块,如果cas能够成功加锁,并且cells还是原来的cells,创建一个长度为原来2倍的累加单元数组,将原数组元素拷贝到新数组,再将新数组赋值给cells,最后解锁。
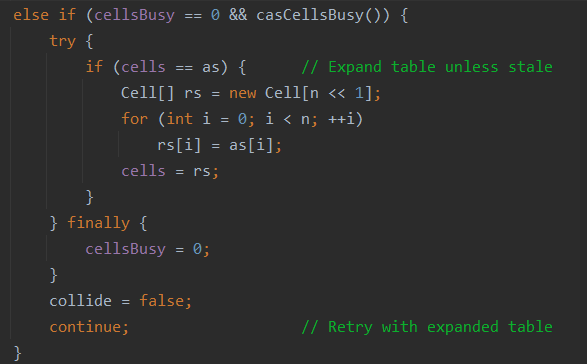

















 1022
1022

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









