



表函数+管道函数+正则表达式
初始数据
create table istr(I_SOURCESTR varchar(255),I_SEPARATOR varchar(255));
insert all
into istr values
('诗歌、戏剧、小说、科学论文、记叙文、议论文、说明文、应用文','、')
into istr values
('天翻地覆|水落石出|手舞足蹈|草长莺飞|莺歌燕舞','|')
into istr values
('沉甸,白花花,绿油油,黑黝黝,慢慢腾腾,阴森森,皱巴巴',',')
select 1 from dual;
select * from istr;

编写表函数
create or replace type dfg as object( --创建对象类型
io int,
rq date,
mc varchar2(60)
);
create or replace type arrytype is table of dfg;--定义表类型
create or replace function func_split(split_source in varchar2,sep in varchar2)--创建表函数
return arrytype PIPELINED --管道函数
as
arry arrytype:=arrytype();
le number;-- 定义分隔符的数量
begin
le:=length(split_source)-length(replace(split_source,sep,''))+1;
for i in 1..le loop
pipe row(dfg(i,sysdate,regexp_substr(split_source,'[^'||sep||']+',1,i)));-- 对目标行进行内容的新增
end loop;
return;
end ;
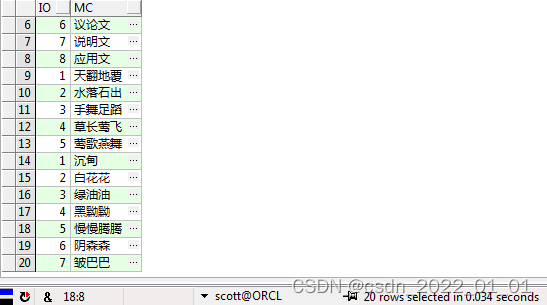
使用表函数对数据清洗输出结果
select io,mc from istr a,table(
func_split( split_source=>a.I_SOURCESTr,sep =>a.I_SEPARATOR))
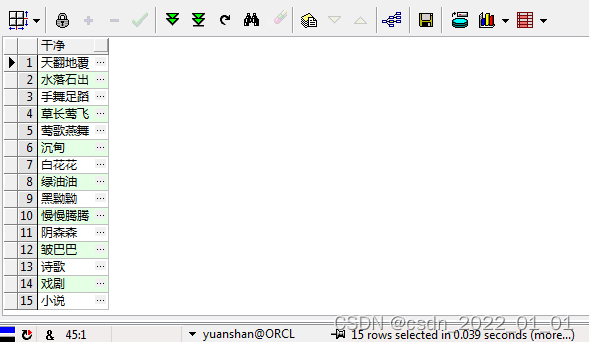
完全用sql进行数据清洗 对比
with len_list as (
select rownum r from dual connect by rownum<=
(select max(length(I_SOURCESTR)-length(replace(I_SOURCESTR,I_SEPARATOR,''))+1) from istr))
select regexp_substr(I_SOURCESTR,'[^'||I_SEPARATOR||']+',1,r) 干净 from istr,len_list where
r<=length(I_SOURCESTR)-length(replace(I_SOURCESTR,I_SEPARATOR,''))+1
order by I_SOURCESTR,r
这里用到递归实现hive炸裂函数的用法
平均耗时对比是管道函数更快
但是表函数跑到块是因为都在内存中进行计算输出,计算后立即返回给用户,不是一次性返回
资源cost耗费特别多
存储过程清洗
处理一条数据再插入到另一个表格中,需要多层循环,效率比较低,不在这里展示


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









