



 本文介绍了作者在使用Loki、Promtail和Grafana构建日志收集系统的过程,对比了Loki与ElasticSearch在日志管理和资源占用上的区别,并分享了Promtail的配置与使用经验,以及在实施过程中遇到的问题和解决方案。
本文介绍了作者在使用Loki、Promtail和Grafana构建日志收集系统的过程,对比了Loki与ElasticSearch在日志管理和资源占用上的区别,并分享了Promtail的配置与使用经验,以及在实施过程中遇到的问题和解决方案。
自从买了一套云服务器以后,部署好了kubernetes,也部署了自己写的一套后台接口SHOP,通过Drone+Helm发到自己的kubernetes集群中,因此希望收集服务运行日志供查看。
日志收集系统,一般以ELK架构居多,现在很多也会考虑用 Fluentd 组成EFK。但对于资源有限的集群来说,部署一个ElasticSearch的成本实在太高,幸好现在已经有一套新的低成本开源方案,那就是LPG。也同样能达到日志收集和检索的目的,占用的资源还少。
Loki
Loki是Grafana公司出的一款开源的日志存储和检索系统,对标的是ElasticSearch,但是设计理念完全不同,ElasticSearch核心是倒排索引,而Loki的核心是基于KV标签的索引+原始日志存储。在存储占用上,Loki的占用量天生就比ElasticSearch少,这里我不想具体分析Loki的架构,因为官方文档和一些技术文章都介绍的很详细了,我想从主观上记录下与ElasticSearch使用上的不同点。
- Loki 更适合日志
ElasticSearch我们都知道,是一个搜索引擎,可以处理分词、排序、聚合计算等等搜索引擎需要的功能,用于日志的话,更多是在使用它的存储能力和全文检索能力,但实际使用时,不但它提供的排序、聚合等操作我们用不上,还得学习它的检索语法,还得处理好日志字段的索引规则,要优化的点比较多,换句话说,学习成本和维护成本比较高。而我们平常查看日志,无非是希望日志能可靠的存储起来,查询时能根据某些条件进行筛选,就够用了。Loki在设计时也考虑到了这些方面,所以它并不是索引全部的日志记录,而是索引日志的标签,比如说,Node: 10.0.17.1 标签、Service: sk-shop 标签、LogLevel: Info 标签等。可以通过这些标签去缩小日志范围,再通过扫描日志内容的方式grep出需要的日志。听起来好像不靠谱,好比我一个服务每天打印几十G日志,你一条条的筛选内容效率不是O(n)了吗,但实际上,我们日志查询其实只是查某段时间内的日志,实际查询时量没那么大的,而且Loki在筛选是可以并行化筛选,所以速度其实不慢,实测下来并没有什么大的影响。 - Loki资源占用少
我本地机器是2核4G,上面不止跑了loki,还跑了很多其它应用,查询速度也没受到什么影响,如果换成ElasticSearch,我怀疑可能这配置都运行不起来。 - Loki和kubernetes结合的比较好
Grafana出的很多开源产品,都借鉴了Prometheus的设计,比如标签,比如Prometheus的查询语言是PromQL,Loki就搞出一个LogQL,比如自动服务发现,天生就支持在kubernetes中自动发现,配置起来比较简单,这点也是ElasticSearch做不到的。
Promtail
Promtail说白了就是个Loki专用的日志收集工具,实际上其它的日志收集工具比如:Filebeat、Fluentd等也可以使用,我觉得哪个用的熟练就用那个,都没用过就用Promtail。
Promtail的官方文档藏在Loki文档里面,而且写的比较乱,实际上它的工作流程就是:从配置文件中读取服务发现配置,然后去抓取对应的服务的日志文件,比如配置了kubernetes_sd_config,部署方式是DaemonSet,那就去节点的/var/log下去抓日志文件,它会保存当前读取的日志文件的offset,所以重启也不用担心会重复抓取,在这个抓的过程中,就可以配置一些标签,方便后续查询。
Promtail抓取到文件后,就可以通过它提供的Pipelines能力过滤日志内容,每条日志都会进入Pipelines进行处理,管道的操作可以分为四种:解析、转换、动作、过滤。如果管道什么都不做,那就会把抓到的日志原样送到Loki中存储。
- 解析
一般是解析日志内容,获取一些KV值,供后序操作读取和使用。比如通过正则表达式去解析出一些匹配组,或者解析json,转换成KV字段。比如以下日志行,就可以解析出log、stream、time三个Key,给后序操作使用
{"log":"log message\n","stream":"stderr","time":"2019-04-30T02:12:41.8443515Z"}
- 转换
就是可以改变抓取到的日志行的内容。 - 动作
可以使用前面提取的KV值,比如作为标签写入Loki,进行一些计算之类的。 - 过滤
可以根据LogQL筛选一些日志条目。
实际使用中感觉Promtail能力还是够用的,做好了日志收集器的本职工作,也没有什么七七八八的插件,就是收集、处理、发给Loki。学起来比较简单,只是官方文档写的比较散乱没逻辑。
Grafana
Grafana就不多说了,YYDS属于是。Kibana虽然不论从功能丰富性还是从UI美观度上都比Grafana强些(个人感觉),但Kibana太大而全,学习成本高,里面很多东西比如机器学习、Infrastructure、Uptime那些,都用不上,纯属浪费资源。而且看日志也不是很方便,我记得要看日志上下文还得跳转到其它菜单页中看。
Grafana相比之下就简单多了,但该有的功能还是一个不少的,比如日志检索,上下文查看等,还有些特色功能,总之使用上比较顺手。
踩坑经历
本次踩坑主要是在Promtail的配置上,也是对Kubernetes的日志机制不太熟,比如我kubectl log打出程序日志:
{"level":"info","time":"2022-07-05 17:29:32","caller":"core/opentelemetry.go:106","msg":"core-interceptor","span_id":"d04834f01db9c801","traceId":"856e8ed9af60d9a631d42b856766cfe4","method":"GET","path":"/sk_shop_sk/v1/list","http_code":200,"business_code":0,"cost_seconds":0.009312892}
{"level":"info","time":"2022-07-05 17:29:32","caller":"core/opentelemetry.go:106","msg":"core-interceptor","span_id":"4fb18fcf0e348d06","traceId":"819f8e22f754082e92e966acde6f8a32","method":"GET","path":"/sk_shop_sk/v1/list","http_code":200,"business_code":0,"cost_seconds":0.008773451}
{"level":"info","time":"2022-07-05 17:29:32","caller":"core/opentelemetry.go:106","msg":"core-interceptor","span_id":"1b3f8f03cdaa9cd5","traceId":"301e308eee8c5efd9c14b114177b497f","method":"GET","path":"/sk_shop_sk/v1/list","http_code":200,"business_code":0,"cost_seconds":0.009352069}
{"level":"info","time":"2022-07-05 17:29:32","caller":"core/opentelemetry.go:106","msg":"core-interceptor","span_id":"004fb8a7fc2b8e43","traceId":"dfd90c901fc284b20957ec3960d2efd5","method":"GET","path":"/sk_shop_sk/v1/list","http_code":200,"business_code":0,"cost_seconds":0.009415056}
{"level":"info","time":"2022-07-05 17:29:33","caller":"core/opentelemetry.go:106","msg":"core-interceptor","span_id":"a59e6dc94e0ef1eb","traceId":"df31011a1b22831ce62826eb048dabd9","method":"GET","path":"/sk_shop_sk/v1/list","http_code":200,"business_code":0,"cost_seconds":0.009245755}
{"level":"info","time":"2022-07-05 17:29:33","caller":"core/opentelemetry.go:106","msg":"core-interceptor","span_id":"3463327dd5b8faa9","traceId":"448d237198db62f658c07347f6861431","method":"GET","path":"/sk_shop_sk/v1/list","http_code":200,"business_code":0,"cost_seconds":0.009157465}
程序日志是用zap打出来的json结构化日志,方便解析,我使用以下Promtail配置去处理日志:
server:
log_level: info
http_listen_port: 3101
client:
url: http://loki-0.loki-headless.kube-ops.svc.cluster.local:3100/loki/api/v1/push
positions:
filename: /run/promtail/positions.yaml
scrape_configs:
- job_name: kubernetes-pods
pipeline_stages:
- match:
selector: '{namespace="default",pod=~"sk-.+"}'
stages:
- json:
expressions:
caller: caller
level: level
msg: msg
span_id: span_id
time: time
- labels:
level: null
kubernetes_sd_configs:
- role: pod
relabel_configs:
...
可以看到,我用了Pipeline,首先用match操作过滤出服务的pod,再用json操作去解析pod打出来的日志,提取level字段,再用labels操作把level打到日志标签中。
但是这个配置没生效,就很奇怪:
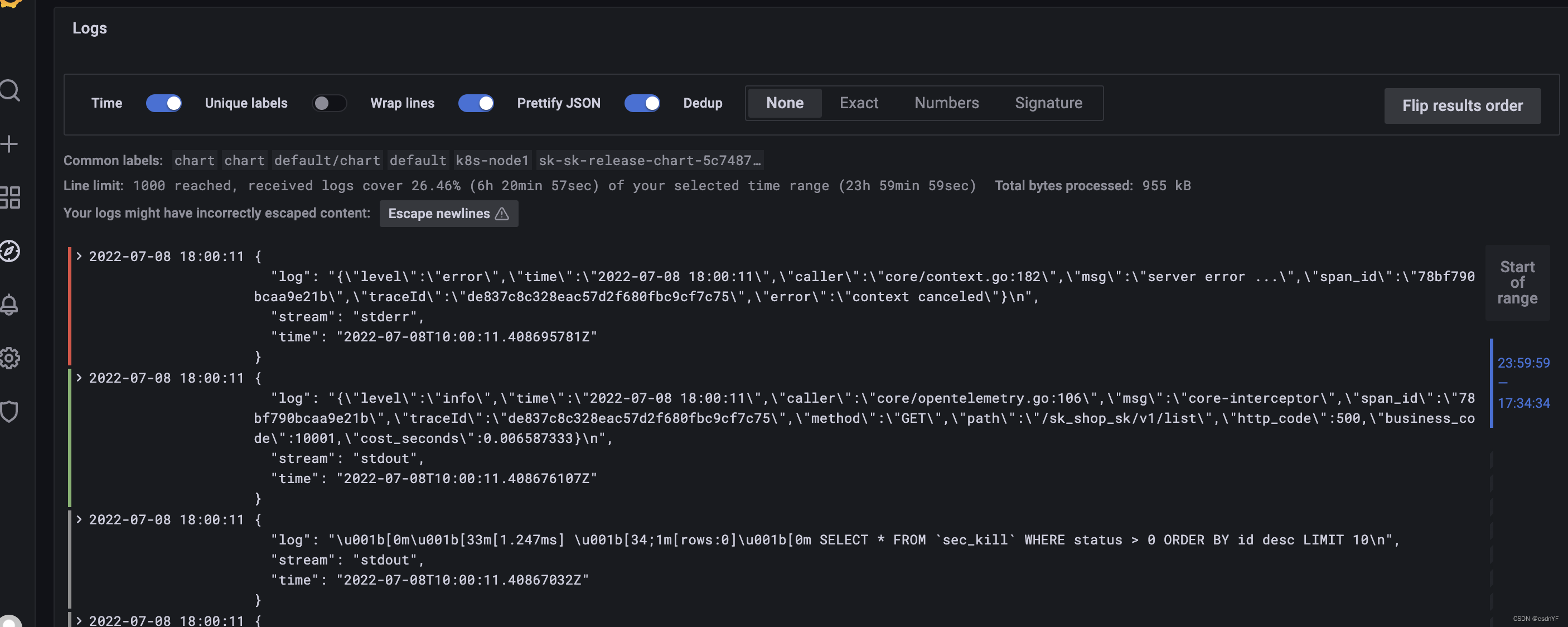
抓到Loki中的日志被包上了log、stream、time这样的标签,多方查阅资料才发现,因为我kubernetes底层容器运行时是Docker,而Docker默认的日志格式就是这样的,只是我们使用kubectl log 命令时,自动帮我们解包了而已。
{"log":"{\"level\":\"info\",\"time\":\"2022-07-11 14:27:33\",\"caller\":\"core/opentelemetry.go:106\",\"msg\":\"core-interceptor\",\"span_id\":\"423d77f877c8aee3\",\"traceId\":\"5d69f66d5a0ffb881f7565e87ab8bd26\",\"method\":\"GET\",\"path\":\"/sk_shop_sk/v1/list\",\"http_code\":200,\"business_code\":0,\"cost_seconds\":0.008391238}\n","stream":"stdout","time":"2022-07-11T06:27:33.649912105Z"}
{"log":"{\"level\":\"info\",\"time\":\"2022-07-11 14:27:33\",\"caller\":\"core/opentelemetry.go:106\",\"msg\":\"core-interceptor\",\"span_id\":\"478ffa75bae4b3da\",\"traceId\":\"e18fa3500faaccc9d643d5b155ed33b7\",\"method\":\"GET\",\"path\":\"/sk_shop_sk/v1/list\",\"http_code\":200,\"business_code\":0,\"cost_seconds\":0.008335854}\n","stream":"stdout","time":"2022-07-11T06:27:33.70734752Z"}
{"log":"{\"level\":\"info\",\"time\":\"2022-07-11 14:27:33\",\"caller\":\"core/opentelemetry.go:106\",\"msg\":\"core-interceptor\",\"span_id\":\"b823e2aafe230bcd\",\"traceId\":\"210bd055cb7a6beb5843f1deadb29d1d\",\"method\":\"GET\",\"path\":\"/sk_shop_sk/v1/list\",\"http_code\":200,\"business_code\":0,\"cost_seconds\":0.019066681}\n","stream":"stdout","time":"2022-07-11T06:27:33.843295157Z"}
所以Promtail的配置文件应该改成如下:
server:
log_level: info
http_listen_port: 3101
client:
url: http://loki-0.loki-headless.kube-ops.svc.cluster.local:3100/loki/api/v1/push
positions:
filename: /run/promtail/positions.yaml
scrape_configs:
- job_name: kubernetes-pods
pipeline_stages:
- docker: {} # 要先用docker 解析 容器日志
- match:
selector: '{namespace="default",pod=~"sk-.+"}'
stages:
- json:
expressions:
caller: caller
level: level
msg: msg
span_id: span_id
time: time
- labels:
level: null
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels:
- __meta_kubernetes_pod_controller_name
regex: ([0-9a-z-.]+?)(-[0-9a-f]{8,10})?
action: replace
target_label: __tmp_controller_name
- source_labels:
- __meta_kubernetes_pod_label_app_kubernetes_io_name
- __meta_kubernetes_pod_label_app
- __tmp_controller_name
- __meta_kubernetes_pod_name
regex: ^;*([^;]+)(;.*)?$
action: replace
target_label: app
- source_labels:
- __meta_kubernetes_pod_label_app_kubernetes_io_component
- __meta_kubernetes_pod_label_component
regex: ^;*([^;]+)(;.*)?$
action: replace
target_label: component
- action: replace
source_labels:
- __meta_kubernetes_pod_node_name
target_label: node_name
- action: replace
source_labels:
- __meta_kubernetes_namespace
target_label: namespace
- action: replace
replacement: $1
separator: /
source_labels:
- namespace
- app
target_label: job
- action: replace
source_labels:
- __meta_kubernetes_pod_name
target_label: pod
- action: replace
source_labels:
- __meta_kubernetes_pod_container_name
target_label: container
- action: replace
replacement: /var/log/pods/*$1/*.log
separator: /
source_labels:
- __meta_kubernetes_pod_uid
- __meta_kubernetes_pod_container_name
target_label: __path__
- action: replace
regex: true/(.*)
replacement: /var/log/pods/*$1/*.log
separator: /
source_labels:
- __meta_kubernetes_pod_annotationpresent_kubernetes_io_config_hash
- __meta_kubernetes_pod_annotation_kubernetes_io_config_hash
- __meta_kubernetes_pod_container_name
target_label: __path__
我直接贴上完整的配置供参考。这次再访问Grafana,就可以看到正常的json日志了:
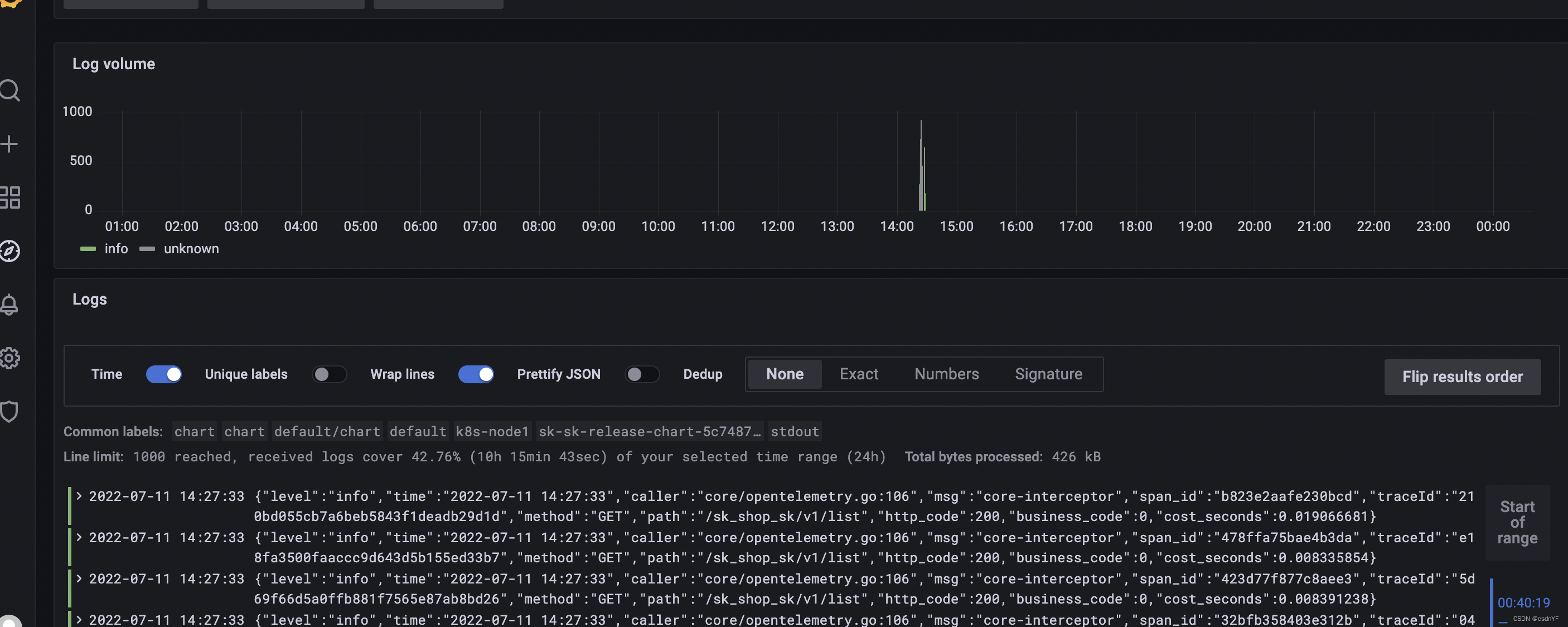
附录
文章最后,如果大家也想搭建属于自己的kubernetes集群,学习云原生知识的话,建议可以通过这个连接去腾讯云购买云服务器,两百多块钱就能买到2核4G+2核2G 一年,现在搞活动还多送3个月,足够学习了。
毕竟本地搭kubernetes集群只是模拟的,真正在云上搭才会遇到网络问题、存储问题、服务发现等kubernetes常见问题,对提高自己的技能比较有帮助。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









